 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverse Rendering Techniques for Physically Grounded Image Editing
Dec 25, 2019From a single picture of a scene, people can typically grasp the spatial layout immediately and even make good guesses at materials properties and where light is coming from to illuminate the scene. For example, we can reliably tell which objects occlude others, what an object is made of and its rough shape, regions that are illuminated or in shadow, and so on. It is interesting how little is known about our ability to make these determinations; as such, we are still not able to robustly "teach" computers to make the same high-level observations as people. This document presents algorithms for understanding intrinsic scene properties from single images. The goal of these inverse rendering techniques is to estimate the configurations of scene elements (geometry, materials, luminaires, camera parameters, etc) using only information visible in an image. Such algorithms have applications in robotics and computer graphics. One such application is in physically grounded image editing: photo editing made easier by leveraging knowledge of the physical space. These applications allow sophisticated editing operations to be performed in a matter of seconds, enabling seamless addition, removal, or relocation of objects in images.
DepthTransfer: Depth Extraction from Video Using Non-parametric Sampling
Dec 24, 2019
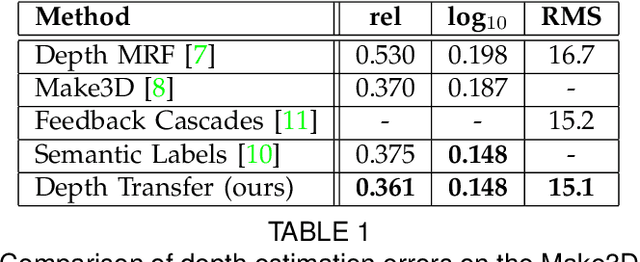
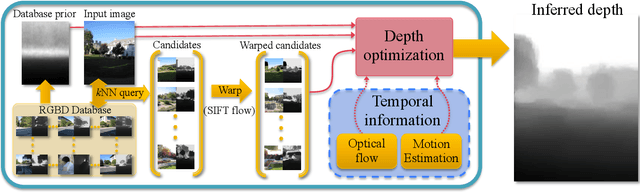

We describe a technique that automatically generates plausible depth maps from videos using non-parametric depth sampling. We demonstrate our technique in cases where past methods fail (non-translating cameras and dynamic scenes). Our technique is applicable to single images as well as videos. For videos, we use local motion cues to improve the inferred depth maps, while optical flow is used to ensure temporal depth consistency. For training and evaluation, we use a Kinect-based system to collect a large dataset containing stereoscopic videos with known depths. We show that our depth estimation technique outperforms the state-of-the-art on benchmark databases. Our technique can be used to automatically convert a monoscopic video into stereo for 3D visualization, and we demonstrate this through a variety of visually pleasing results for indoor and outdoor scenes, including results from the feature film Charade.
Boundary Cues for 3D Object Shape Recovery
Dec 24, 2019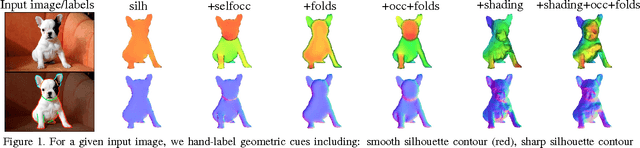
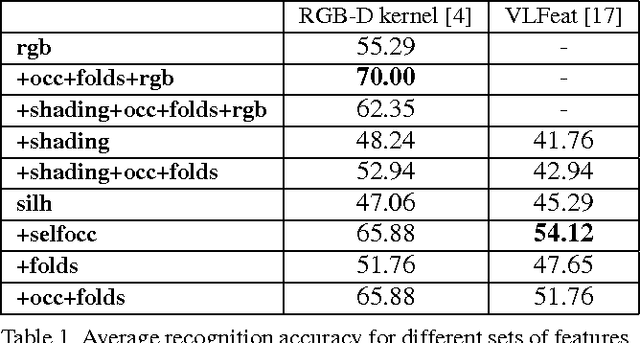


Early work in computer vision considered a host of geometric cues for both shape reconstruction and recognition. However, since then, the vision community has focused heavily on shading cues for reconstruction, and moved towards data-driven approaches for recognition. In this paper, we reconsider these perhaps overlooked "boundary" cues (such as self occlusions and folds in a surface), as well as many other established constraints for shape reconstruction. In a variety of user studies and quantitative tasks, we evaluate how well these cues inform shape reconstruction (relative to each other) in terms of both shape quality and shape recognition. Our findings suggest many new directions for future research in shape reconstruction, such as automatic boundary cue detection and relaxing assumptions in shape from shading (e.g. orthographic projection, Lambertian surfaces).
Depth Extraction from Video Using Non-parametric Sampling
Dec 24, 2019We describe a technique that automatically generates plausible depth maps from videos using non-parametric depth sampling. We demonstrate our technique in cases where past methods fail (non-translating cameras and dynamic scenes). Our technique is applicable to single images as well as videos. For videos, we use local motion cues to improve the inferred depth maps, while optical flow is used to ensure temporal depth consistency. For training and evaluation, we use a Kinect-based system to collect a large dataset containing stereoscopic videos with known depths. We show that our depth estimation technique outperforms the state-of-the-art on benchmark databases. Our technique can be used to automatically convert a monoscopic video into stereo for 3D visualization, and we demonstrate this through a variety of visually pleasing results for indoor and outdoor scenes, including results from the feature film Charade.
* arXiv admin note: text overlap with arXiv:2001.00987
A Fast, Semi-Automatic Brain Structure Segmentation Algorithm for Magnetic Resonance Imaging
Apr 21, 2019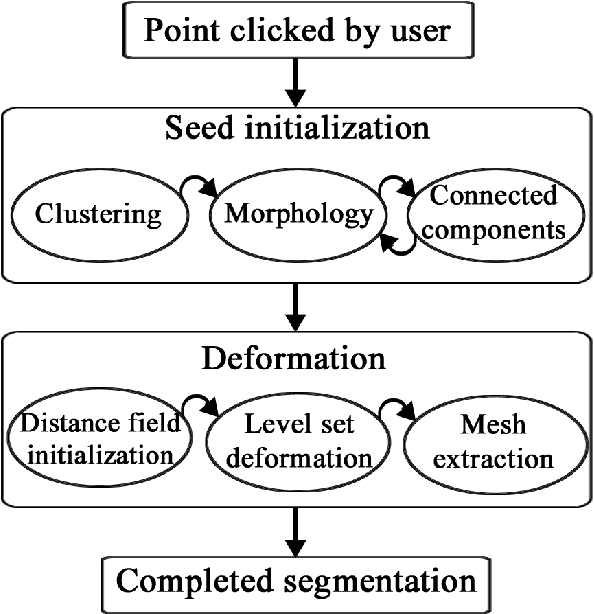

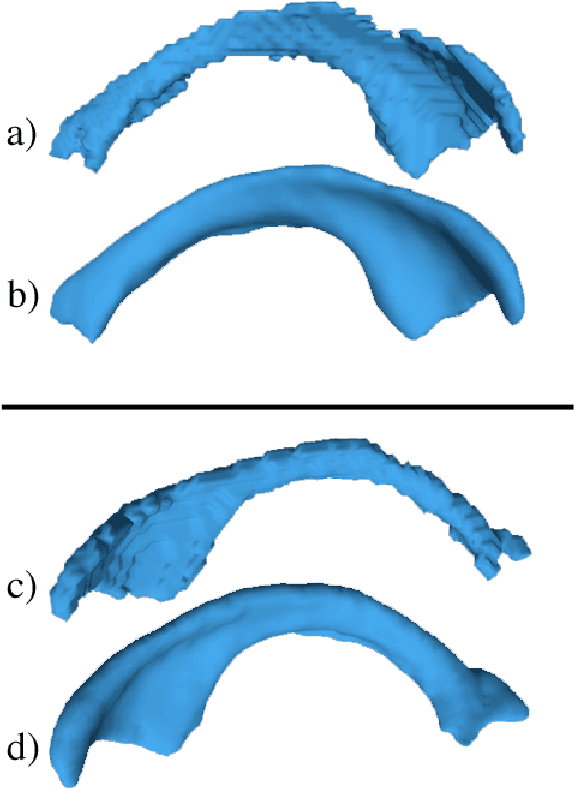
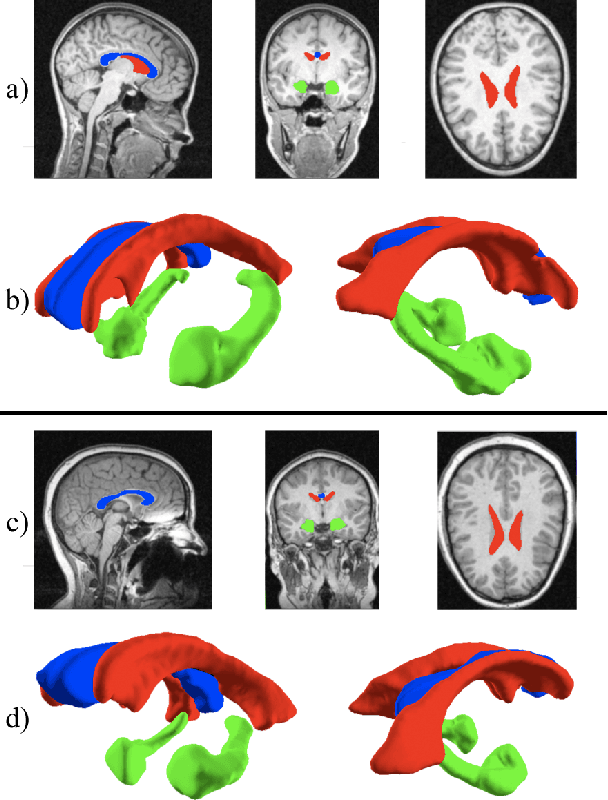
Medical image segmentation has become an essential technique in clinical and research-oriented applications. Because manual segmentation methods are tedious, and fully automatic segmentation lacks the flexibility of human intervention or correction, semi-automatic methods have become the preferred type of medical image segmentation. We present a hybrid, semi-automatic segmentation method in 3D that integrates both region-based and boundary-based procedures. Our method differs from previous hybrid methods in that we perform region-based and boundary-based approaches separately, which allows for more efficient segmentation. A region-based technique is used to generate an initial seed contour that roughly represents the boundary of a target brain structure, alleviating the local minima problem in the subsequent model deformation phase. The contour is deformed under a unique force equation independent of image edges. Experiments on MRI data show that this method can achieve high accuracy and efficiency primarily due to the unique seed initialization technique.
Web Based Brain Volume Calculation for Magnetic Resonance Images
Apr 21, 2019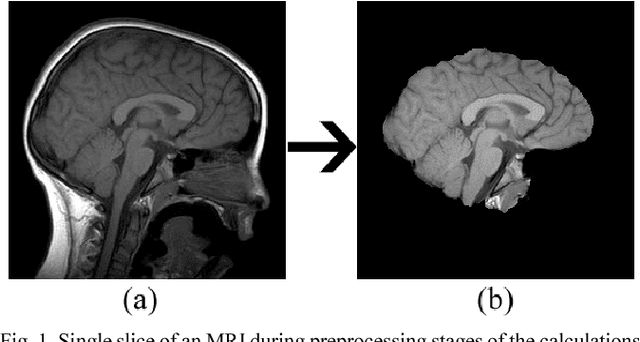
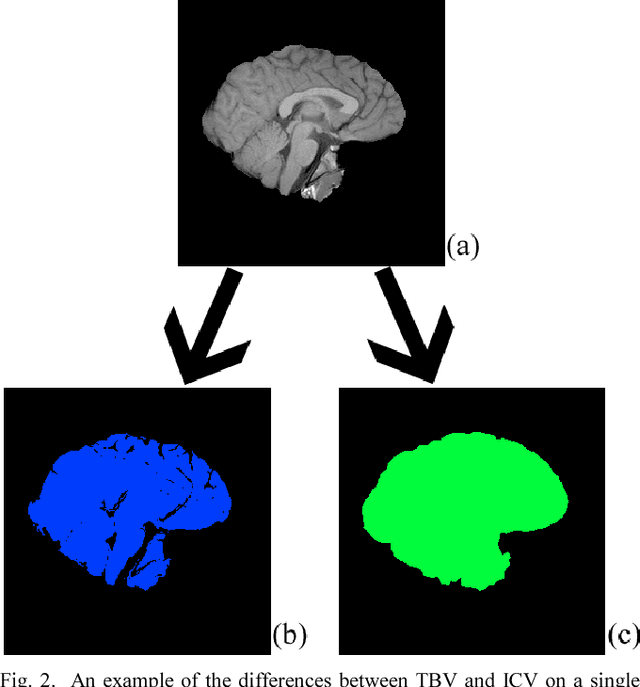
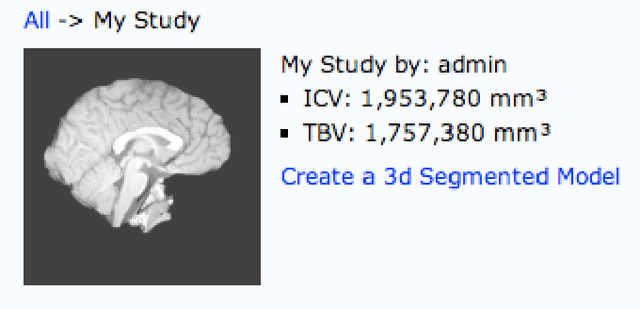
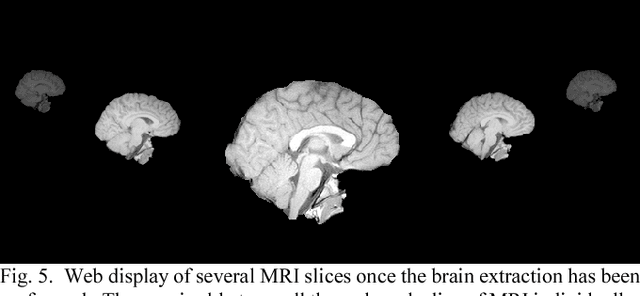
Brain volume calculations are crucial in modern medical research, especially in the study of neurodevelopmental disorders. In this paper, we present an algorithm for calculating two classifications of brain volume, total brain volume (TBV) and intracranial volume (ICV). Our algorithm takes MRI data as input, performs several preprocessing and intermediate steps, and then returns each of the two calculated volumes. To simplify this process and make our algorithm publicly accessible to anyone, we have created a web-based interface that allows users to upload their own MRI data and calculate the TBV and ICV for the given data. This interface provides a simple and efficient method for calculating these two classifications of brain volume, and it also removes the need for the user to download or install any applications.
An Approximate Shading Model with Detail Decomposition for Object Relighting
Apr 20, 2018


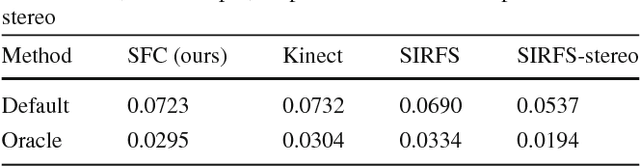
We present an object relighting system that allows an artist to select an object from an image and insert it into a target scene. Through simple interactions, the system can adjust illumination on the inserted object so that it appears naturally in the scene. To support image-based relighting, we build object model from the image, and propose a \emph{perceptually-inspired} approximate shading model for the relighting. It decomposes the shading field into (a) a rough shape term that can be reshaded, (b) a parametric shading detail that encodes missing features from the first term, and (c) a geometric detail term that captures fine-scale material properties. With this decomposition, the shading model combines 3D rendering and image-based composition and allows more flexible compositing than image-based methods. Quantitative evaluation and a set of user studies suggest our method is a promising alternative to existing methods of object insertion.