 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning-Based Airway Segmentation in Systemic Lupus Erythematosus Patients with Interstitial Lung Disease (SLE-ILD): A Comparative High-Resolution CT Analysis
Mar 18, 2026To characterize lobar and segmental airway volume differences between systemic lupus erythematosus (SLE) patients with interstitial lung disease (ILD) and those without ILD (non-ILD) using a deep learning-based approach on non-contrast chest high-resolution CT (HRCT). Methods: A retrospective analysis was conducted on 106 SLE patients (27 SLE-ILD, 79 SLE-non-ILD) who underwent HRCT. A customized deep learning framework based on the U-Net architecture was developed to automatically segment airway structures at the lobar and segmental levels via HRCT. Volumetric measurements of lung lobes and segments derived from the segmentations were statistically compared between the two groups using two-sample t-tests (significance threshold: p < 0.05). Results: At lobar level, significant airway volume enlargement in SLE-ILD patients was observed in the right upper lobe (p=0.009) and left upper lobe (p=0.039) compared to SLE-non-ILD. At the segmental level, significant differences were found in segments including R1 (p=0.016), R3 (p<0.001), and L3 (p=0.038), with the most marked changes in the upper lung zones, while lower zones showed non-significant trends. Conclusion: Our study demonstrates that an automated deep learning-based approach can effectively quantify airway volumes on HRCT scans and reveal significant, region-specific airway dilation in patients with SLE-ILD compared to those without ILD. The pattern of involvement, predominantly affecting the upper lobes and specific segments, highlights a distinct topographic phenotype of SLE-ILD and implicates airway structural alterations as a potential biomarker for disease presence. This AI-powered quantitative imaging biomarker holds promise for enhancing the early detection and monitoring of ILD in the SLE population, ultimately contributing to more personalized patient management.
Bronchovascular Tree-Guided Weakly Supervised Learning Method for Pulmonary Segment Segmentation
May 20, 2025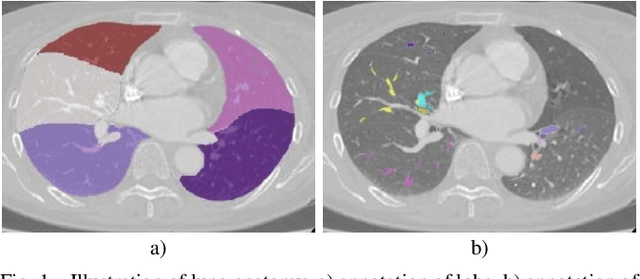
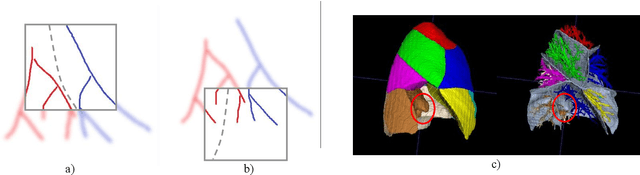
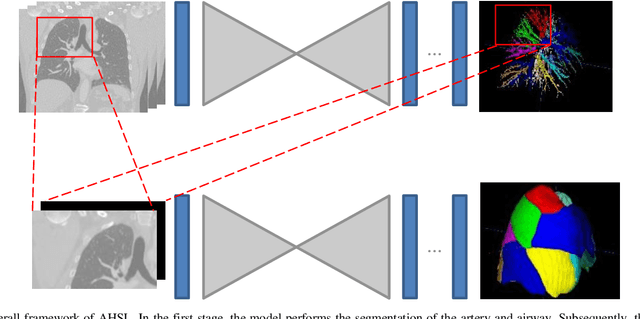
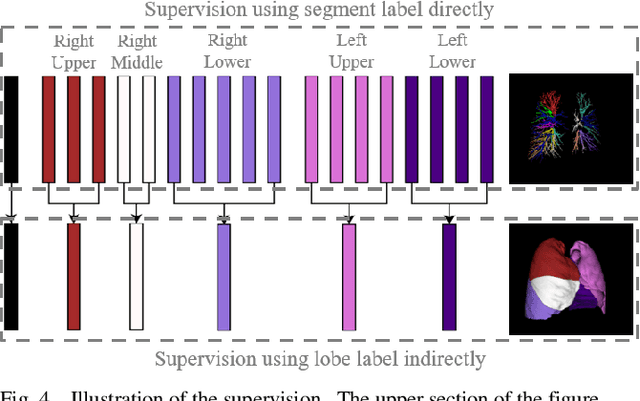
Pulmonary segment segmentation is crucial for cancer localization and surgical planning. However, the pixel-wise annotation of pulmonary segments is laborious, as the boundaries between segments are indistinguishable in medical images. To this end, we propose a weakly supervised learning (WSL) method, termed Anatomy-Hierarchy Supervised Learning (AHSL), which consults the precise clinical anatomical definition of pulmonary segments to perform pulmonary segment segmentation. Since pulmonary segments reside within the lobes and are determined by the bronchovascular tree, i.e., artery, airway and vein, the design of the loss function is founded on two principles. First, segment-level labels are utilized to directly supervise the output of the pulmonary segments, ensuring that they accurately encompass the appropriate bronchovascular tree. Second, lobe-level supervision indirectly oversees the pulmonary segment, ensuring their inclusion within the corresponding lobe. Besides, we introduce a two-stage segmentation strategy that incorporates bronchovascular priori information. Furthermore, a consistency loss is proposed to enhance the smoothness of segment boundaries, along with an evaluation metric designed to measure the smoothness of pulmonary segment boundaries. Visual inspection and evaluation metrics from experiments conducted on a private dataset demonstrate the effectiveness of our method.
FedDiv: Collaborative Noise Filtering for Federated Learning with Noisy Labels
Dec 20, 2023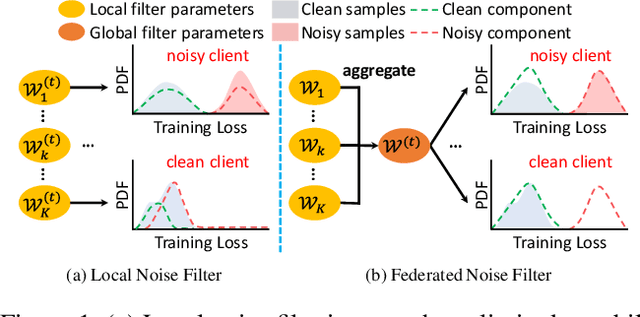
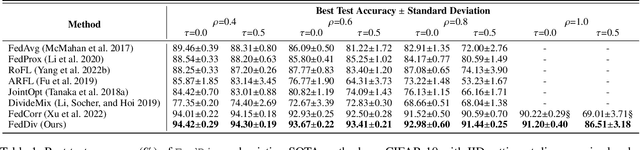
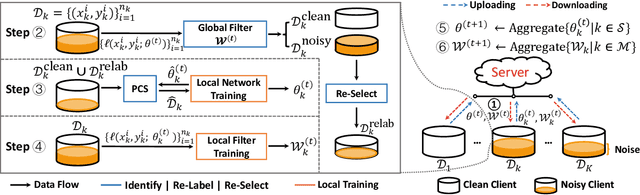
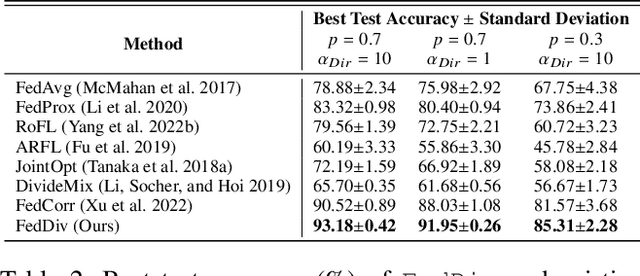
Federated learning with noisy labels (F-LNL) aims at seeking an optimal server model via collaborative distributed learning by aggregating multiple client models trained with local noisy or clean samples. On the basis of a federated learning framework, recent advances primarily adopt label noise filtering to separate clean samples from noisy ones on each client, thereby mitigating the negative impact of label noise. However, these prior methods do not learn noise filters by exploiting knowledge across all clients, leading to sub-optimal and inferior noise filtering performance and thus damaging training stability. In this paper, we present FedDiv to tackle the challenges of F-LNL. Specifically, we propose a global noise filter called Federated Noise Filter for effectively identifying samples with noisy labels on every client, thereby raising stability during local training sessions. Without sacrificing data privacy, this is achieved by modeling the global distribution of label noise across all clients. Then, in an effort to make the global model achieve higher performance, we introduce a Predictive Consistency based Sampler to identify more credible local data for local model training, thus preventing noise memorization and further boosting the training stability. Extensive experiments on CIFAR-10, CIFAR-100, and Clothing1M demonstrate that \texttt{FedDiv} achieves superior performance over state-of-the-art F-LNL methods under different label noise settings for both IID and non-IID data partitions. Source code is publicly available at https://github.com/lijichang/FLNL-FedDiv.
Boundary Cues for 3D Object Shape Recovery
Dec 24, 2019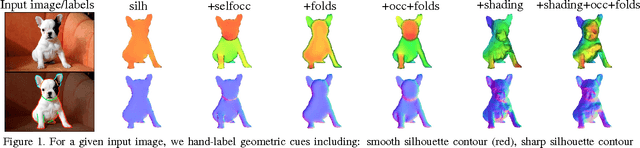
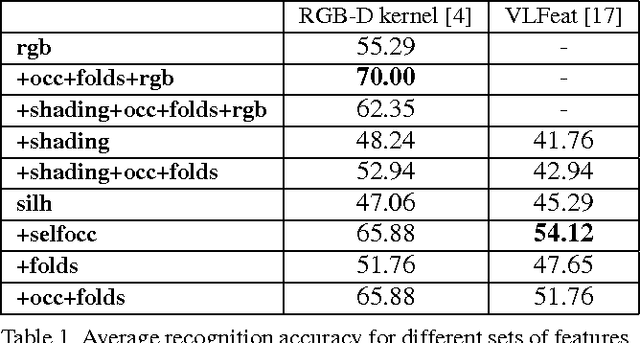


Early work in computer vision considered a host of geometric cues for both shape reconstruction and recognition. However, since then, the vision community has focused heavily on shading cues for reconstruction, and moved towards data-driven approaches for recognition. In this paper, we reconsider these perhaps overlooked "boundary" cues (such as self occlusions and folds in a surface), as well as many other established constraints for shape reconstruction. In a variety of user studies and quantitative tasks, we evaluate how well these cues inform shape reconstruction (relative to each other) in terms of both shape quality and shape recognition. Our findings suggest many new directions for future research in shape reconstruction, such as automatic boundary cue detection and relaxing assumptions in shape from shading (e.g. orthographic projection, Lambertian surfaces).
Intrinsic Image Transformation via Scale Space Decomposition
May 25, 2018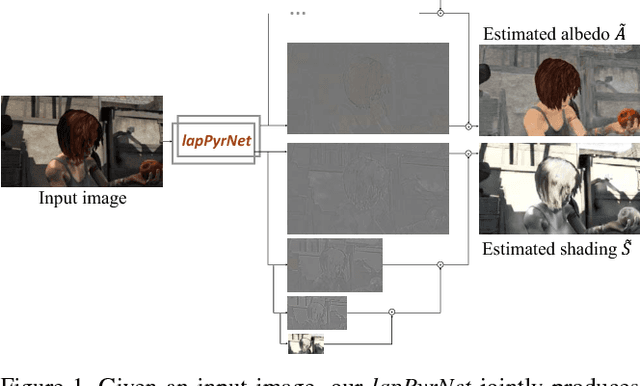
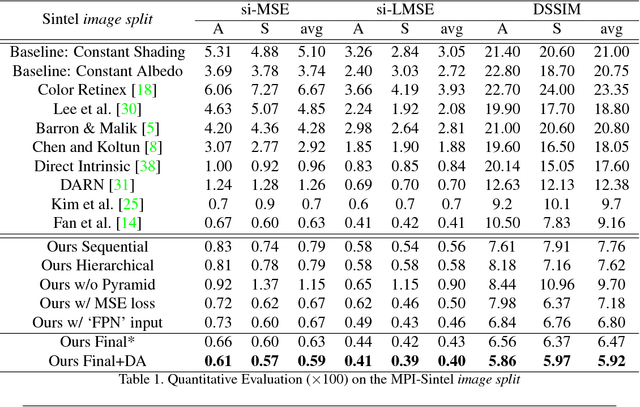
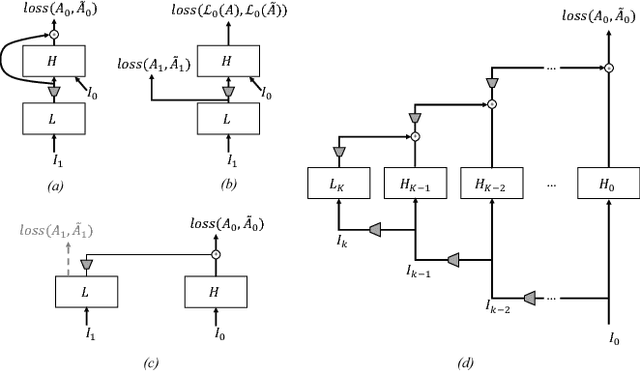
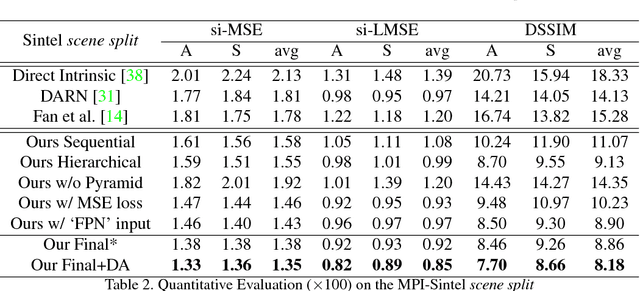
We introduce a new network structure for decomposing an image into its intrinsic albedo and shading. We treat this as an image-to-image transformation problem and explore the scale space of the input and output. By expanding the output images (albedo and shading) into their Laplacian pyramid components, we develop a multi-channel network structure that learns the image-to-image transformation function in successive frequency bands in parallel, within each channel is a fully convolutional neural network with skip connections. This network structure is general and extensible, and has demonstrated excellent performance on the intrinsic image decomposition problem. We evaluate the network on two benchmark datasets: the MPI-Sintel dataset and the MIT Intrinsic Images dataset. Both quantitative and qualitative results show our model delivers a clear progression over state-of-the-art.
Piecewise Flat Embedding for Image Segmentation
May 20, 2018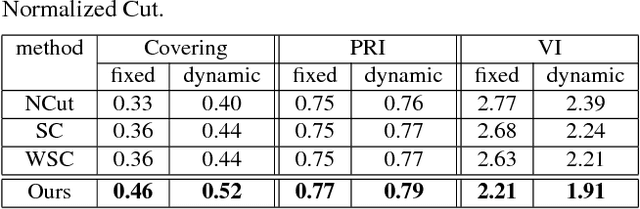

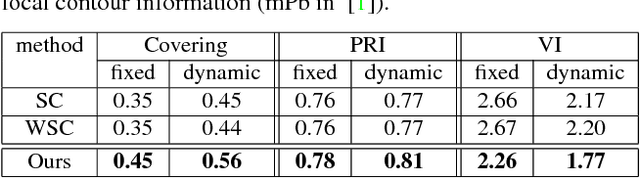
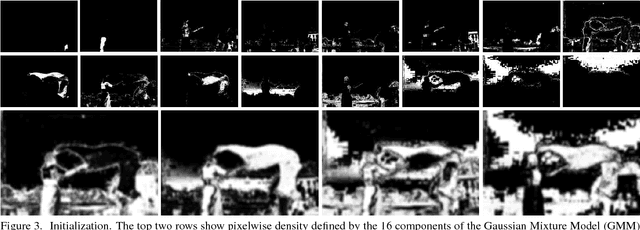
We introduce a new multi-dimensional nonlinear embedding -- Piecewise Flat Embedding (PFE) -- for image segmentation. Based on the theory of sparse signal recovery, piecewise flat embedding with diverse channels attempts to recover a piecewise constant image representation with sparse region boundaries and sparse cluster value scattering. The resultant piecewise flat embedding exhibits interesting properties such as suppressing slowly varying signals, and offers an image representation with higher region identifiability which is desirable for image segmentation or high-level semantic analysis tasks. We formulate our embedding as a variant of the Laplacian Eigenmap embedding with an $L_{1,p} (0<p\leq1)$ regularization term to promote sparse solutions. First, we devise a two-stage numerical algorithm based on Bregman iterations to compute $L_{1,1}$-regularized piecewise flat embeddings. We further generalize this algorithm through iterative reweighting to solve the general $L_{1,p}$-regularized problem. To demonstrate its efficacy, we integrate PFE into two existing image segmentation frameworks, segmentation based on clustering and hierarchical segmentation based on contour detection. Experiments on four major benchmark datasets, BSDS500, MSRC, Stanford Background Dataset, and PASCAL Context, show that segmentation algorithms incorporating our embedding achieve significantly improved results.
An Approximate Shading Model with Detail Decomposition for Object Relighting
Apr 20, 2018


We present an object relighting system that allows an artist to select an object from an image and insert it into a target scene. Through simple interactions, the system can adjust illumination on the inserted object so that it appears naturally in the scene. To support image-based relighting, we build object model from the image, and propose a \emph{perceptually-inspired} approximate shading model for the relighting. It decomposes the shading field into (a) a rough shape term that can be reshaded, (b) a parametric shading detail that encodes missing features from the first term, and (c) a geometric detail term that captures fine-scale material properties. With this decomposition, the shading model combines 3D rendering and image-based composition and allows more flexible compositing than image-based methods. Quantitative evaluation and a set of user studies suggest our method is a promising alternative to existing methods of object insertion.
Structured Label Inference for Visual Understanding
Feb 18, 2018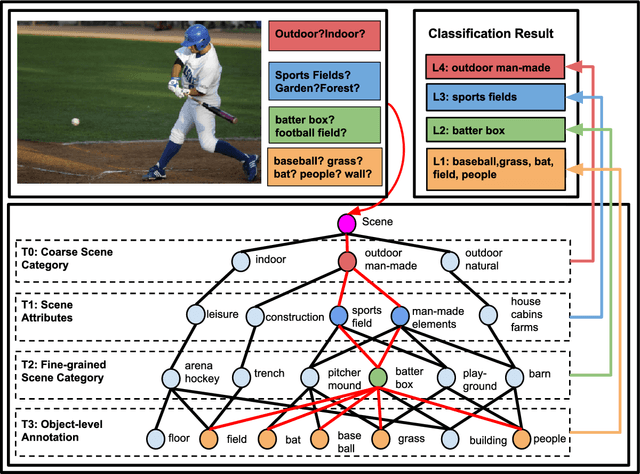
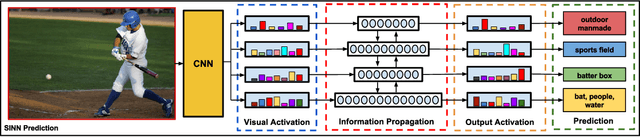
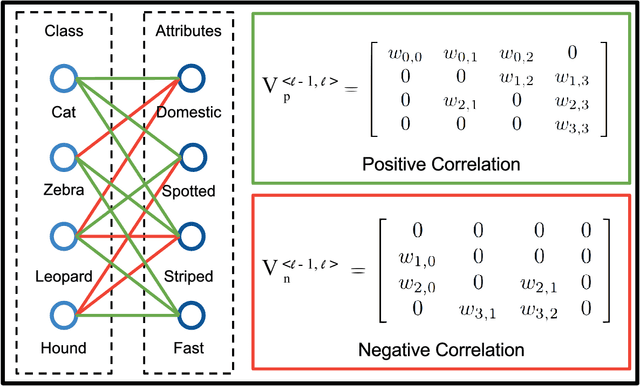
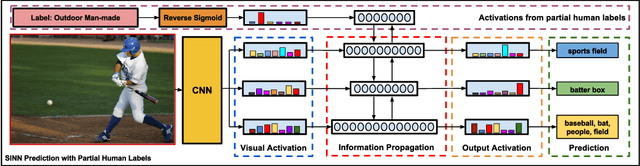
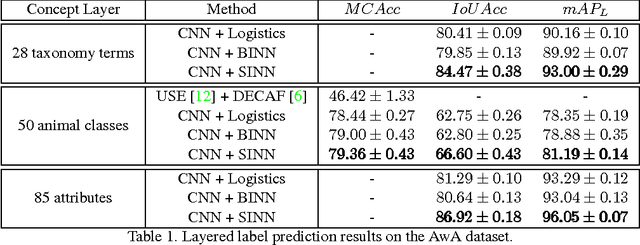
Visual data such as images and videos contain a rich source of structured semantic labels as well as a wide range of interacting components. Visual content could be assigned with fine-grained labels describing major components, coarse-grained labels depicting high level abstractions, or a set of labels revealing attributes. Such categorization over different, interacting layers of labels evinces the potential for a graph-based encoding of label information. In this paper, we exploit this rich structure for performing graph-based inference in label space for a number of tasks: multi-label image and video classification and action detection in untrimmed videos. We consider the use of the Bidirectional Inference Neural Network (BINN) and Structured Inference Neural Network (SINN) for performing graph-based inference in label space and propose a Long Short-Term Memory (LSTM) based extension for exploiting activity progression on untrimmed videos. The methods were evaluated on (i) the Animal with Attributes (AwA), Scene Understanding (SUN) and NUS-WIDE datasets for multi-label image classification, (ii) the first two releases of the YouTube-8M large scale dataset for multi-label video classification, and (iii) the THUMOS'14 and MultiTHUMOS video datasets for action detection. Our results demonstrate the effectiveness of structured label inference in these challenging tasks, achieving significant improvements against baselines.
Learning Structured Inference Neural Networks with Label Relations
Oct 24, 2016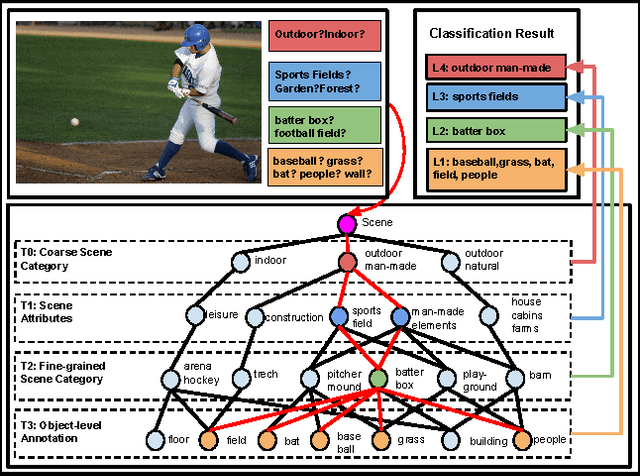

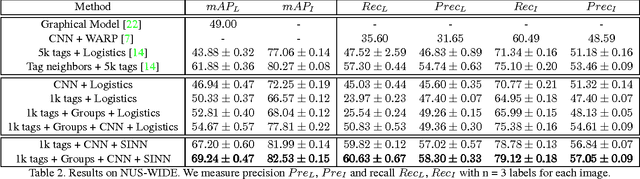
Images of scenes have various objects as well as abundant attributes, and diverse levels of visual categorization are possible. A natural image could be assigned with fine-grained labels that describe major components, coarse-grained labels that depict high level abstraction or a set of labels that reveal attributes. Such categorization at different concept layers can be modeled with label graphs encoding label information. In this paper, we exploit this rich information with a state-of-art deep learning framework, and propose a generic structured model that leverages diverse label relations to improve image classification performance. Our approach employs a novel stacked label prediction neural network, capturing both inter-level and intra-level label semantics. We evaluate our method on benchmark image datasets, and empirical results illustrate the efficacy of our model.