 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEliminating the Language Bias for Visual Question Answering with fine-grained Causal Intervention
Paper and Code
Oct 14, 2024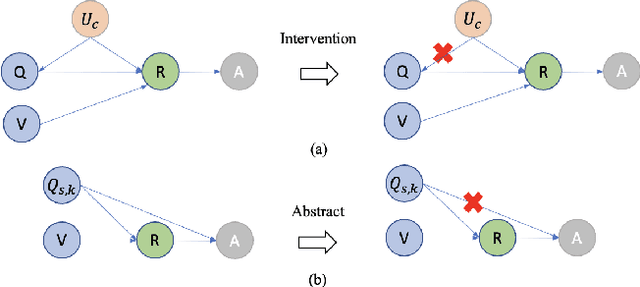
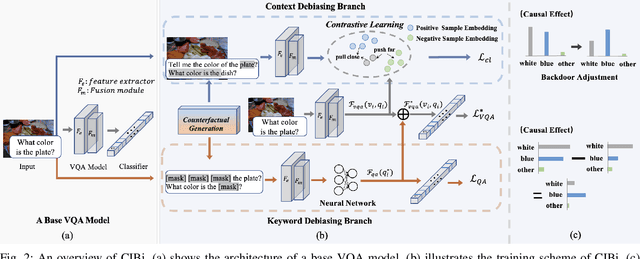
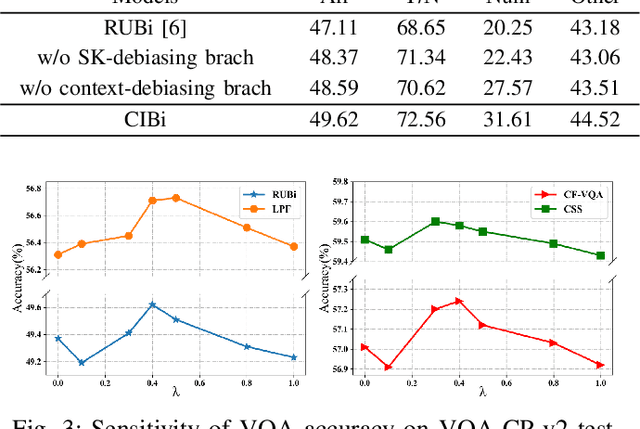
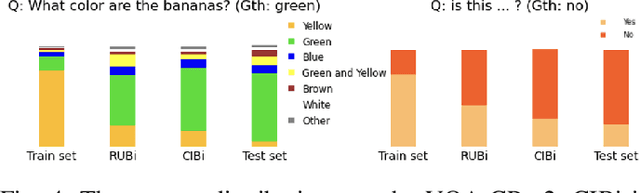
Despite the remarkable advancements in Visual Question Answering (VQA), the challenge of mitigating the language bias introduced by textual information remains unresolved. Previous approaches capture language bias from a coarse-grained perspective. However, the finer-grained information within a sentence, such as context and keywords, can result in different biases. Due to the ignorance of fine-grained information, most existing methods fail to sufficiently capture language bias. In this paper, we propose a novel causal intervention training scheme named CIBi to eliminate language bias from a finer-grained perspective. Specifically, we divide the language bias into context bias and keyword bias. We employ causal intervention and contrastive learning to eliminate context bias and improve the multi-modal representation. Additionally, we design a new question-only branch based on counterfactual generation to distill and eliminate keyword bias. Experimental results illustrate that CIBi is applicable to various VQA models, yielding competitive performance.