 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting the equivalence between quantum neural networks and perceptrons
Jul 05, 2024
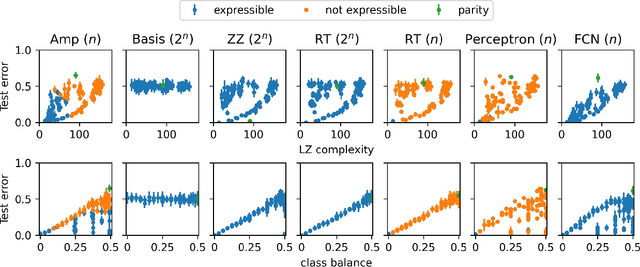
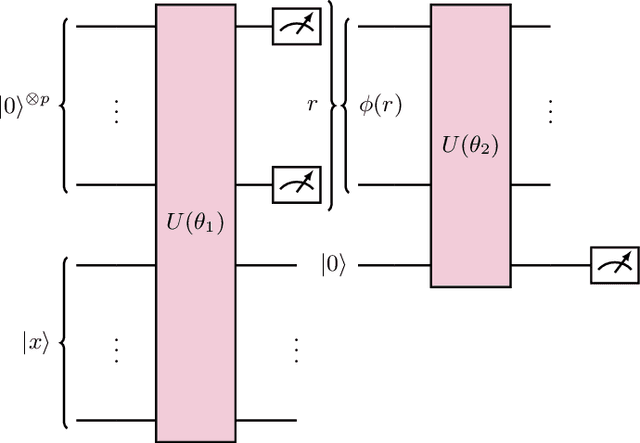
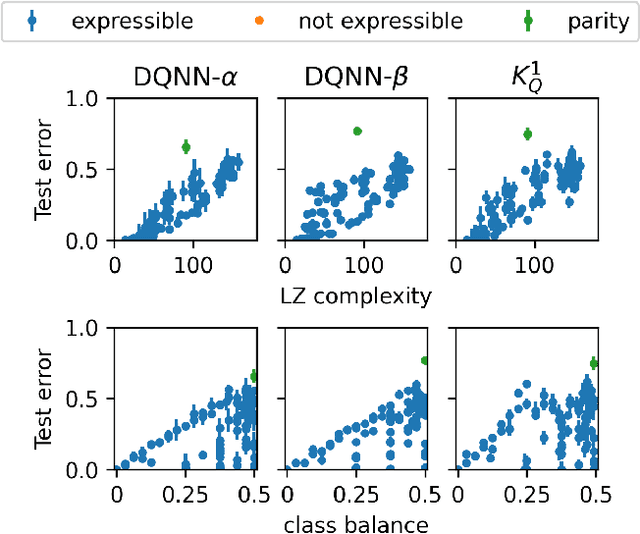
Quantum machine learning models based on parametrized quantum circuits, also called quantum neural networks (QNNs), are considered to be among the most promising candidates for applications on near-term quantum devices. Here we explore the expressivity and inductive bias of QNNs by exploiting an exact mapping from QNNs with inputs $x$ to classical perceptrons acting on $x \otimes x$ (generalised to complex inputs). The simplicity of the perceptron architecture allows us to provide clear examples of the shortcomings of current QNN models, and the many barriers they face to becoming useful general-purpose learning algorithms. For example, a QNN with amplitude encoding cannot express the Boolean parity function for $n\geq 3$, which is but one of an exponential number of data structures that such a QNN is unable to express. Mapping a QNN to a classical perceptron simplifies training, allowing us to systematically study the inductive biases of other, more expressive embeddings on Boolean data. Several popular embeddings primarily produce an inductive bias towards functions with low class balance, reducing their generalisation performance compared to deep neural network architectures which exhibit much richer inductive biases. We explore two alternate strategies that move beyond standard QNNs. In the first, we use a QNN to help generate a classical DNN-inspired kernel. In the second we draw an analogy to the hierarchical structure of deep neural networks and construct a layered non-linear QNN that is provably fully expressive on Boolean data, while also exhibiting a richer inductive bias than simple QNNs. Finally, we discuss characteristics of the QNN literature that may obscure how hard it is to achieve quantum advantage over deep learning algorithms on classical data.
Do Quantum Neural Networks have Simplicity Bias?
Jul 03, 2024



One hypothesis for the success of deep neural networks (DNNs) is that they are highly expressive, which enables them to be applied to many problems, and they have a strong inductive bias towards solutions that are simple, known as simplicity bias, which allows them to generalise well on unseen data because most real-world data is structured (i.e. simple). In this work, we explore the inductive bias and expressivity of quantum neural networks (QNNs), which gives us a way to compare their performance to those of DNNs. Our results show that it is possible to have simplicity bias with certain QNNs, but we prove that this type of QNN limits the expressivity of the QNN. We also show that it is possible to have QNNs with high expressivity, but they either have no inductive bias or a poor inductive bias and result in a worse generalisation performance compared to DNNs. We demonstrate that an artificial (restricted) inductive bias can be produced by intentionally restricting the expressivity of a QNN. Our results suggest a bias-expressivity tradeoff. Our conclusion is that the QNNs we studied can not generally offer an advantage over DNNs, because these QNNs either have a poor inductive bias or poor expressivity compared to DNNs.