 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding of Emotion Perception from Art
Paper and Code
Oct 13, 2021
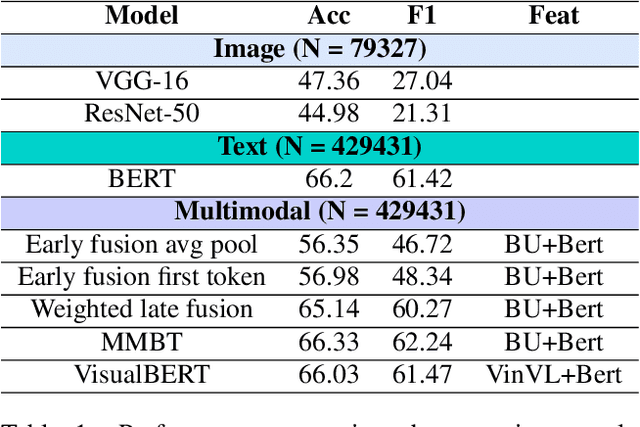

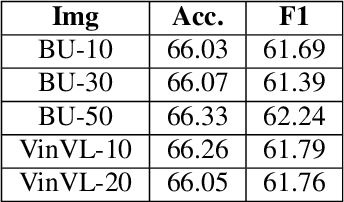
Computational modeling of the emotions evoked by art in humans is a challenging problem because of the subjective and nuanced nature of art and affective signals. In this paper, we consider the above-mentioned problem of understanding emotions evoked in viewers by artwork using both text and visual modalities. Specifically, we analyze images and the accompanying text captions from the viewers expressing emotions as a multimodal classification task. Our results show that single-stream multimodal transformer-based models like MMBT and VisualBERT perform better compared to both image-only models and dual-stream multimodal models having separate pathways for text and image modalities. We also observe improvements in performance for extreme positive and negative emotion classes, when a single-stream model like MMBT is compared with a text-only transformer model like BERT.