 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextually-rich human affect perception using multimodal scene information
Paper and Code

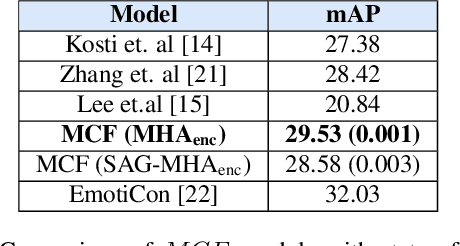
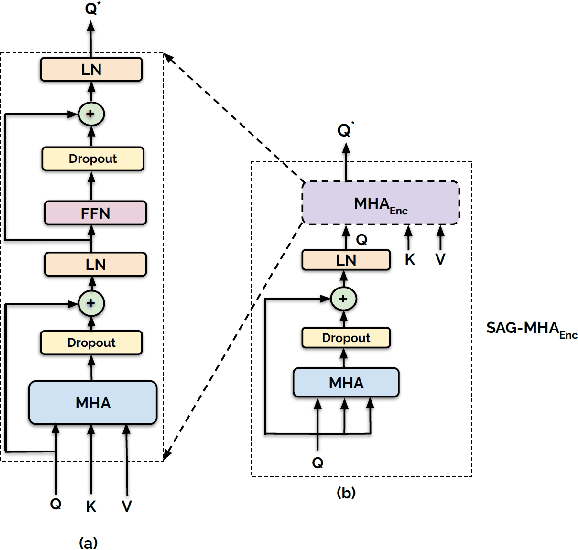
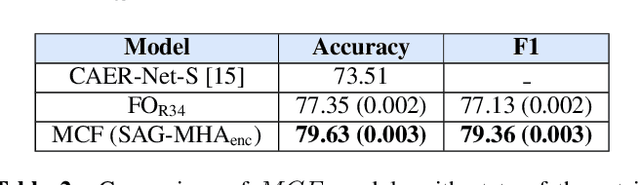
The process of human affect understanding involves the ability to infer person specific emotional states from various sources including images, speech, and language. Affect perception from images has predominantly focused on expressions extracted from salient face crops. However, emotions perceived by humans rely on multiple contextual cues including social settings, foreground interactions, and ambient visual scenes. In this work, we leverage pretrained vision-language (VLN) models to extract descriptions of foreground context from images. Further, we propose a multimodal context fusion (MCF) module to combine foreground cues with the visual scene and person-based contextual information for emotion prediction. We show the effectiveness of our proposed modular design on two datasets associated with natural scenes and TV shows.