 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling and Distilling Transformer Models for sEMG
Jul 29, 2025Surface electromyography (sEMG) signals offer a promising avenue for developing innovative human-computer interfaces by providing insights into muscular activity. However, the limited volume of training data and computational constraints during deployment have restricted the investigation of scaling up the model size for solving sEMG tasks. In this paper, we demonstrate that vanilla transformer models can be effectively scaled up on sEMG data and yield improved cross-user performance up to 110M parameters, surpassing the model size regime investigated in other sEMG research (usually <10M parameters). We show that >100M-parameter models can be effectively distilled into models 50x smaller with minimal loss of performance (<1.5% absolute). This results in efficient and expressive models suitable for complex real-time sEMG tasks in real-world environments.
A Review of Speech-centric Trustworthy Machine Learning: Privacy, Safety, and Fairness
Dec 18, 2022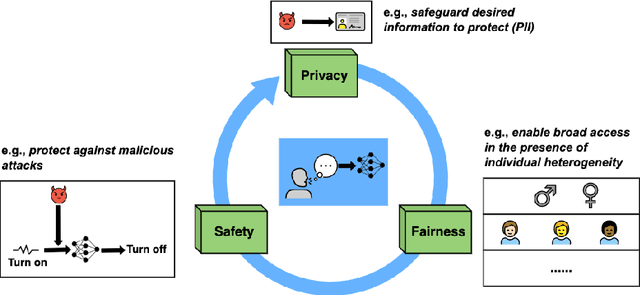
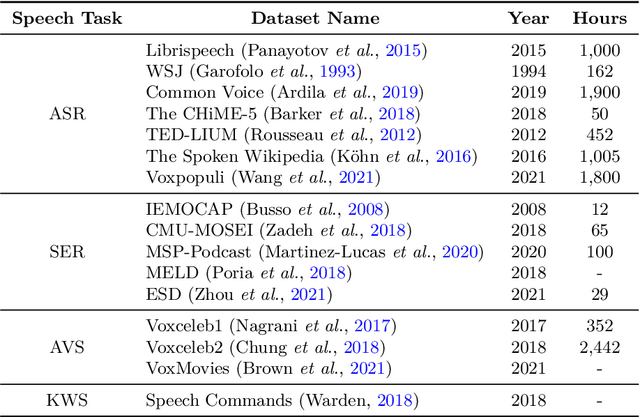
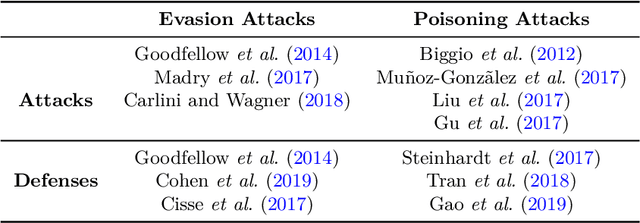
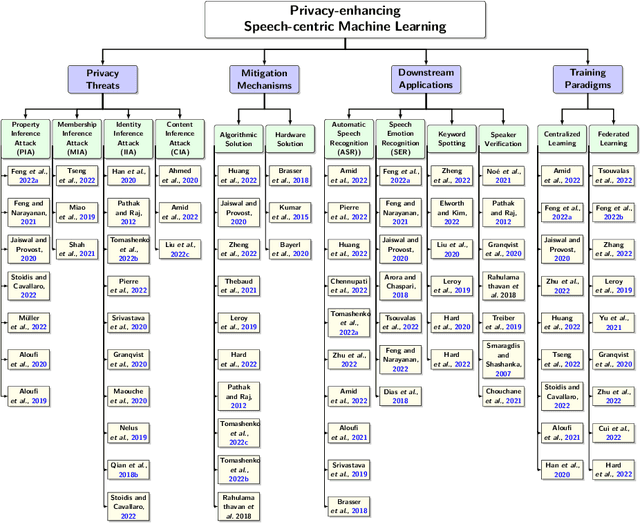
Speech-centric machine learning systems have revolutionized many leading domains ranging from transportation and healthcare to education and defense, profoundly changing how people live, work, and interact with each other. However, recent studies have demonstrated that many speech-centric ML systems may need to be considered more trustworthy for broader deployment. Specifically, concerns over privacy breaches, discriminating performance, and vulnerability to adversarial attacks have all been discovered in ML research fields. In order to address the above challenges and risks, a significant number of efforts have been made to ensure these ML systems are trustworthy, especially private, safe, and fair. In this paper, we conduct the first comprehensive survey on speech-centric trustworthy ML topics related to privacy, safety, and fairness. In addition to serving as a summary report for the research community, we point out several promising future research directions to inspire the researchers who wish to explore further in this area.
Mel Frequency Spectral Domain Defenses against Adversarial Attacks on Speech Recognition Systems
Mar 29, 2022
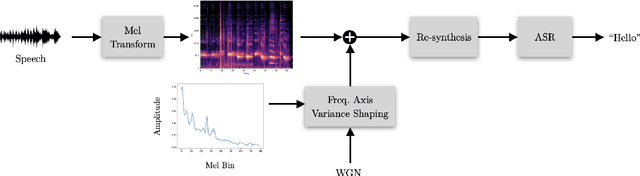
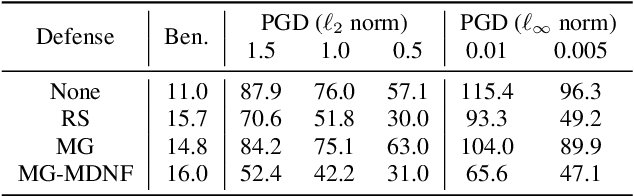
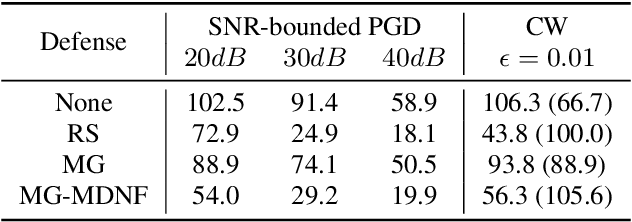
A variety of recent works have looked into defenses for deep neural networks against adversarial attacks particularly within the image processing domain. Speech processing applications such as automatic speech recognition (ASR) are increasingly relying on deep learning models, and so are also prone to adversarial attacks. However, many of the defenses explored for ASR simply adapt the image-domain defenses, which may not provide optimal robustness. This paper explores speech specific defenses using the mel spectral domain, and introduces a novel defense method called 'mel domain noise flooding' (MDNF). MDNF applies additive noise to the mel spectrogram of a speech utterance prior to re-synthesising the audio signal. We test the defenses against strong white-box adversarial attacks such as projected gradient descent (PGD) and Carlini-Wagner (CW) attacks, and show better robustness compared to a randomized smoothing baseline across strong threat models.
Perceptual-based deep-learning denoiser as a defense against adversarial attacks on ASR systems
Jul 12, 2021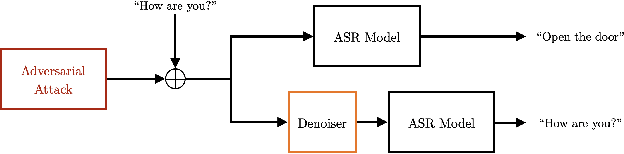
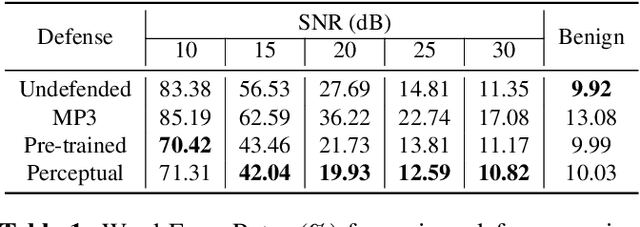
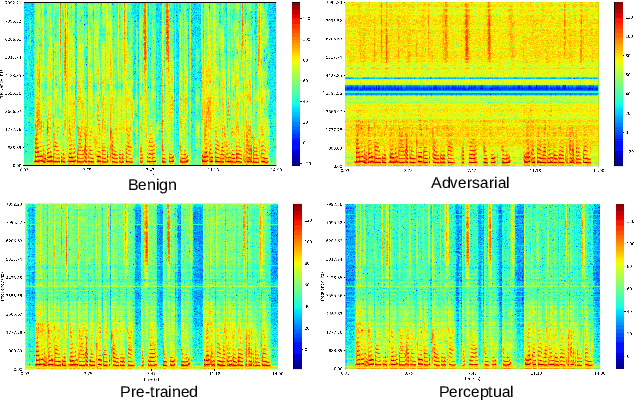
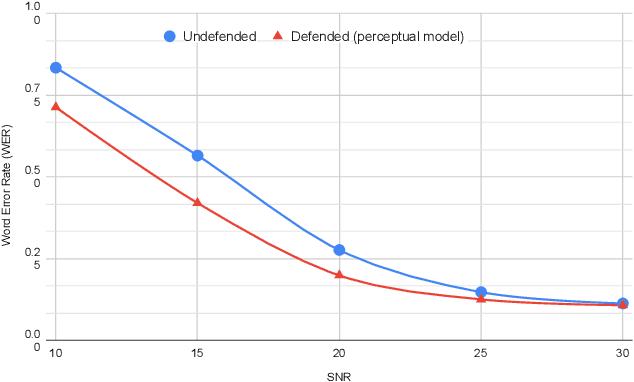
In this paper we investigate speech denoising as a defense against adversarial attacks on automatic speech recognition (ASR) systems. Adversarial attacks attempt to force misclassification by adding small perturbations to the original speech signal. We propose to counteract this by employing a neural-network based denoiser as a pre-processor in the ASR pipeline. The denoiser is independent of the downstream ASR model, and thus can be rapidly deployed in existing systems. We found that training the denoisier using a perceptually motivated loss function resulted in increased adversarial robustness without compromising ASR performance on benign samples. Our defense was evaluated (as a part of the DARPA GARD program) on the 'Kenansville' attack strategy across a range of attack strengths and speech samples. An average improvement in Word Error Rate (WER) of about 7.7% was observed over the undefended model at 20 dB signal-to-noise-ratio (SNR) attack strength.