 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMel Frequency Spectral Domain Defenses against Adversarial Attacks on Speech Recognition Systems
Mar 29, 2022
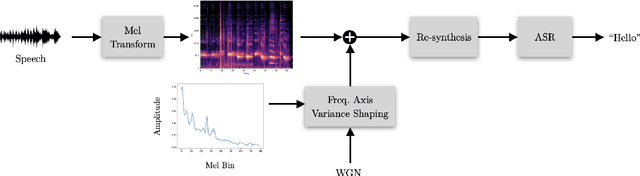
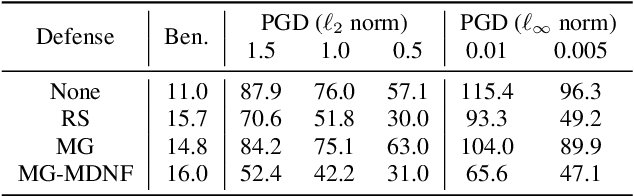
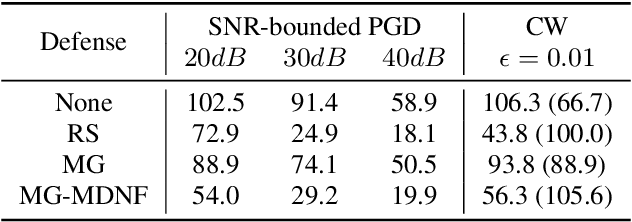
A variety of recent works have looked into defenses for deep neural networks against adversarial attacks particularly within the image processing domain. Speech processing applications such as automatic speech recognition (ASR) are increasingly relying on deep learning models, and so are also prone to adversarial attacks. However, many of the defenses explored for ASR simply adapt the image-domain defenses, which may not provide optimal robustness. This paper explores speech specific defenses using the mel spectral domain, and introduces a novel defense method called 'mel domain noise flooding' (MDNF). MDNF applies additive noise to the mel spectrogram of a speech utterance prior to re-synthesising the audio signal. We test the defenses against strong white-box adversarial attacks such as projected gradient descent (PGD) and Carlini-Wagner (CW) attacks, and show better robustness compared to a randomized smoothing baseline across strong threat models.
Dereverberation of Autoregressive Envelopes for Far-field Speech Recognition
Aug 13, 2021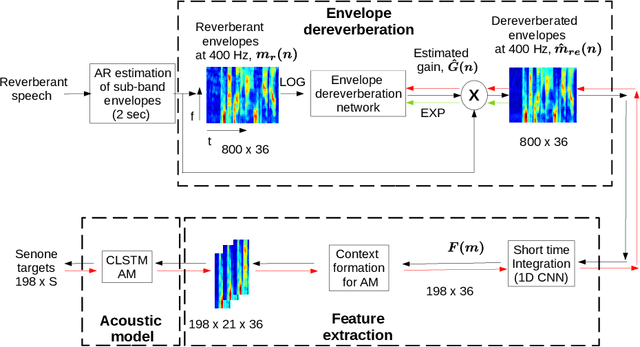
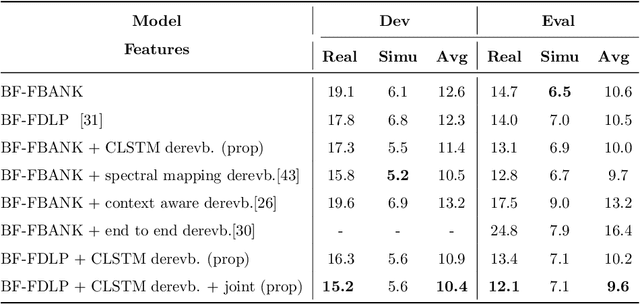
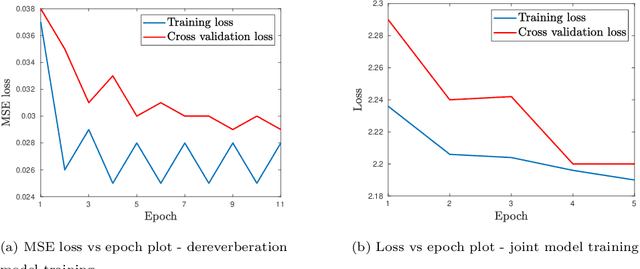

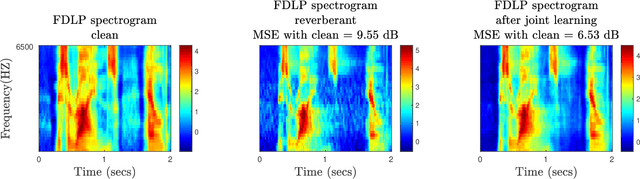
The task of speech recognition in far-field environments is adversely affected by the reverberant artifacts that elicit as the temporal smearing of the sub-band envelopes. In this paper, we develop a neural model for speech dereverberation using the long-term sub-band envelopes of speech. The sub-band envelopes are derived using frequency domain linear prediction (FDLP) which performs an autoregressive estimation of the Hilbert envelopes. The neural dereverberation model estimates the envelope gain which when applied to reverberant signals suppresses the late reflection components in the far-field signal. The dereverberated envelopes are used for feature extraction in speech recognition. Further, the sequence of steps involved in envelope dereverberation, feature extraction and acoustic modeling for ASR can be implemented as a single neural processing pipeline which allows the joint learning of the dereverberation network and the acoustic model. Several experiments are performed on the REVERB challenge dataset, CHiME-3 dataset and VOiCES dataset. In these experiments, the joint learning of envelope dereverberation and acoustic model yields significant performance improvements over the baseline ASR system based on log-mel spectrogram as well as other past approaches for dereverberation (average relative improvements of 10-24% over the baseline system). A detailed analysis on the choice of hyper-parameters and the cost function involved in envelope dereverberation is also provided.
End-to-End Speech Recognition With Joint Dereverberation Of Sub-Band Autoregressive Envelopes
Aug 09, 2021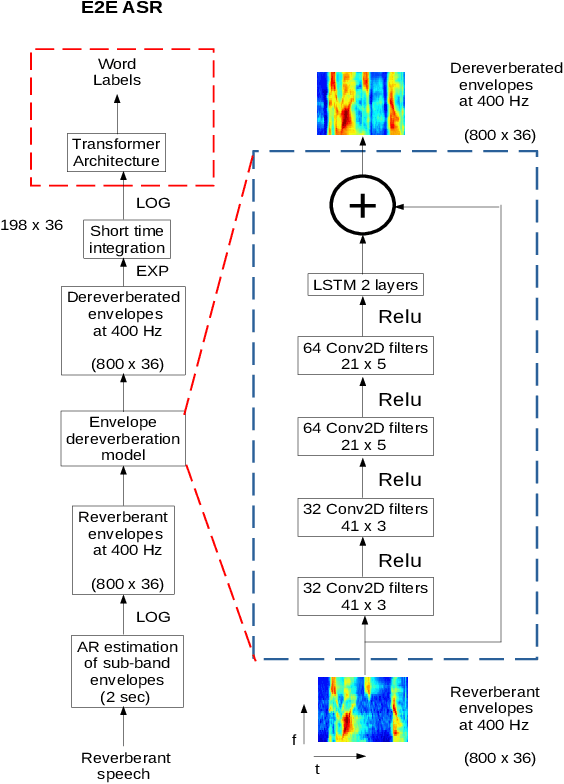
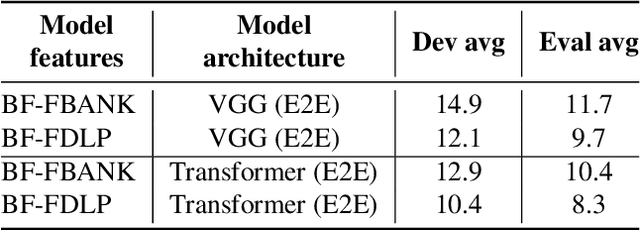
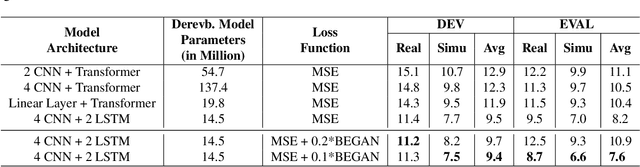
The end-to-end (E2E) automatic speech recognition (ASR) offers several advantages over previous efforts for recognizing speech. However, in reverberant conditions, E2E ASR is a challenging task as the long-term sub-band envelopes of the reverberant speech are temporally smeared. In this paper, we develop a feature enhancement approach using a neural model operating on sub-band temporal envelopes. The temporal envelopes are modeled using the framework of frequency domain linear prediction (FDLP). The neural enhancement model proposed in this paper performs an envelope gain based enhancement of temporal envelopes. The model architecture consists of a combination of convolutional and long short term memory (LSTM) neural network layers. Further, the envelope dereverberation, feature extraction and acoustic modeling using transformer based E2E ASR can all be jointly optimized for the speech recognition task. The joint optimization ensures that the dereverberation model targets the ASR cost function. We perform E2E speech recognition experiments on the REVERB challenge dataset as well as on the VOiCES dataset. In these experiments, the proposed joint modeling approach yields significant improvements compared to baseline E2E ASR system (average relative improvements of 21% on the REVERB challenge dataset and about 10% on the VOiCES dataset).
Perceptual-based deep-learning denoiser as a defense against adversarial attacks on ASR systems
Jul 12, 2021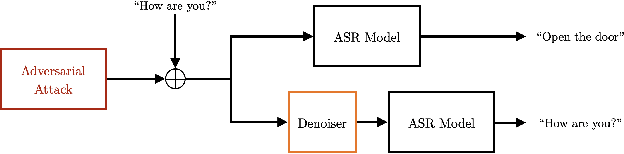
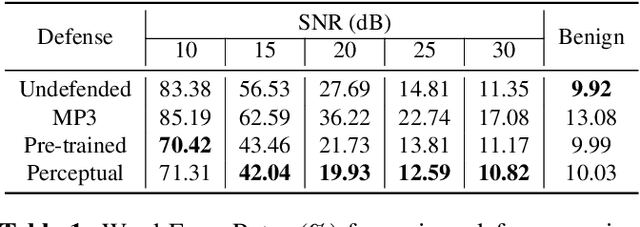
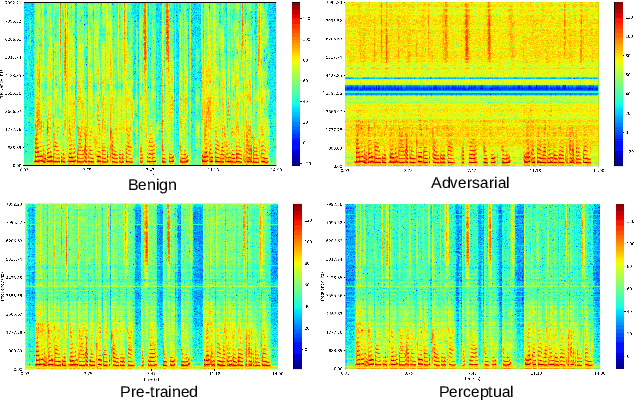
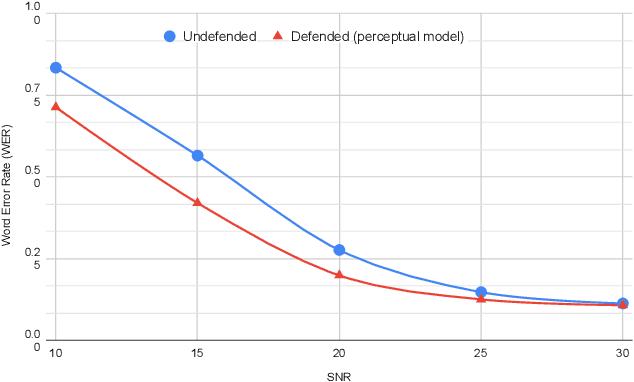
In this paper we investigate speech denoising as a defense against adversarial attacks on automatic speech recognition (ASR) systems. Adversarial attacks attempt to force misclassification by adding small perturbations to the original speech signal. We propose to counteract this by employing a neural-network based denoiser as a pre-processor in the ASR pipeline. The denoiser is independent of the downstream ASR model, and thus can be rapidly deployed in existing systems. We found that training the denoisier using a perceptually motivated loss function resulted in increased adversarial robustness without compromising ASR performance on benign samples. Our defense was evaluated (as a part of the DARPA GARD program) on the 'Kenansville' attack strategy across a range of attack strengths and speech samples. An average improvement in Word Error Rate (WER) of about 7.7% was observed over the undefended model at 20 dB signal-to-noise-ratio (SNR) attack strength.
Unsupervised Neural Mask Estimator For Generalized Eigen-Value Beamforming Based ASR
Nov 28, 2019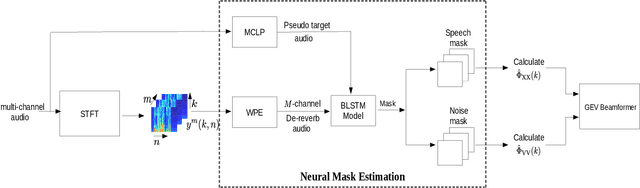

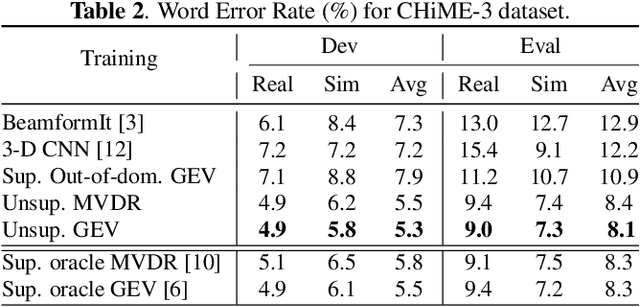
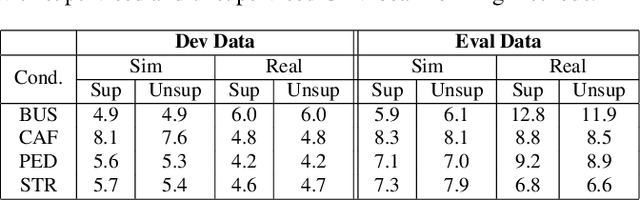
The state-of-art methods for acoustic beamforming in multi-channel ASR are based on a neural mask estimator that predicts the presence of speech and noise. These models are trained using a paired corpus of clean and noisy recordings (teacher model). In this paper, we attempt to move away from the requirements of having supervised clean recordings for training the mask estimator. The models based on signal enhancement and beamforming using multi-channel linear prediction serve as the required mask estimate. In this way, the model training can also be carried out on real recordings of noisy speech rather than simulated ones alone done in a typical teacher model. Several experiments performed on noisy and reverberant environments in the CHiME-3 corpus as well as the REVERB challenge corpus highlight the effectiveness of the proposed approach. The ASR results for the proposed approach provide performances that are significantly better than a teacher model trained on an out-of-domain dataset and on par with the oracle mask estimators trained on the in-domain dataset.
3-D Feature and Acoustic Modeling for Far-Field Speech Recognition
Nov 13, 2019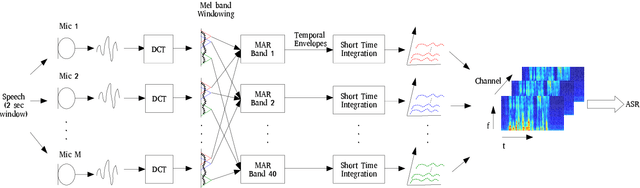
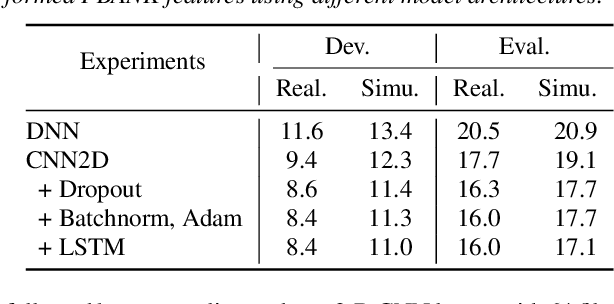

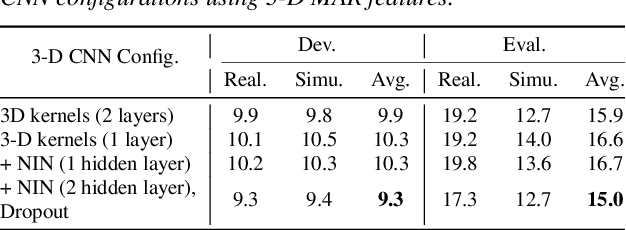
Automatic speech recognition in multi-channel reverberant conditions is a challenging task. The conventional way of suppressing the reverberation artifacts involves a beamforming based enhancement of the multi-channel speech signal, which is used to extract spectrogram based features for a neural network acoustic model. In this paper, we propose to extract features directly from the multi-channel speech signal using a multi variate autoregressive (MAR) modeling approach, where the correlations among all the three dimensions of time, frequency and channel are exploited. The MAR features are fed to a convolutional neural network (CNN) architecture which performs the joint acoustic modeling on the three dimensions. The 3-D CNN architecture allows the combination of multi-channel features that optimize the speech recognition cost compared to the traditional beamforming models that focus on the enhancement task. Experiments are conducted on the CHiME-3 and REVERB Challenge dataset using multi-channel reverberant speech. In these experiments, the proposed 3-D feature and acoustic modeling approach provides significant improvements over an ASR system trained with beamformed audio (average relative improvements of 10 % and 9 % in word error rates for CHiME-3 and REVERB Challenge datasets respectively.