 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Neural Mask Estimator For Generalized Eigen-Value Beamforming Based ASR
Paper and Code
Nov 28, 2019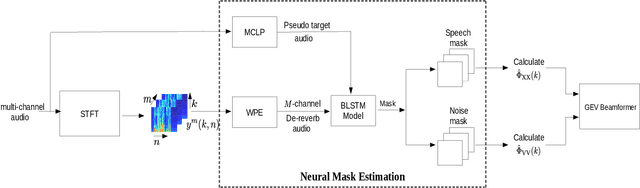

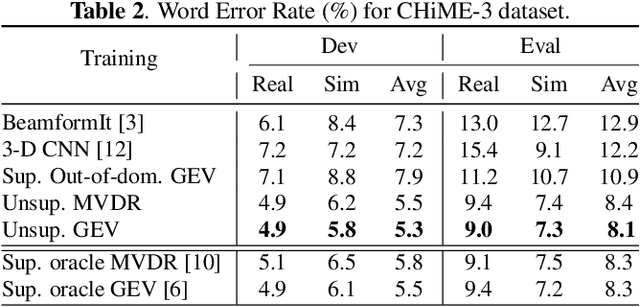
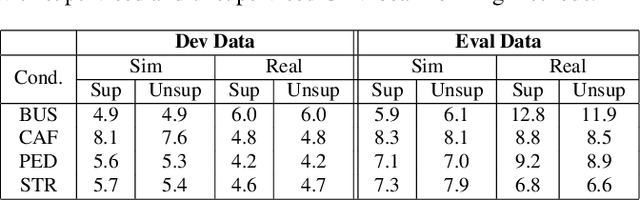
The state-of-art methods for acoustic beamforming in multi-channel ASR are based on a neural mask estimator that predicts the presence of speech and noise. These models are trained using a paired corpus of clean and noisy recordings (teacher model). In this paper, we attempt to move away from the requirements of having supervised clean recordings for training the mask estimator. The models based on signal enhancement and beamforming using multi-channel linear prediction serve as the required mask estimate. In this way, the model training can also be carried out on real recordings of noisy speech rather than simulated ones alone done in a typical teacher model. Several experiments performed on noisy and reverberant environments in the CHiME-3 corpus as well as the REVERB challenge corpus highlight the effectiveness of the proposed approach. The ASR results for the proposed approach provide performances that are significantly better than a teacher model trained on an out-of-domain dataset and on par with the oracle mask estimators trained on the in-domain dataset.