 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePenSLR: Persian end-to-end Sign Language Recognition Using Ensembling
Jun 24, 2024Sign Language Recognition (SLR) is a fast-growing field that aims to fill the communication gaps between the hearing-impaired and people without hearing loss. Existing solutions for Persian Sign Language (PSL) are limited to word-level interpretations, underscoring the need for more advanced and comprehensive solutions. Moreover, previous work on other languages mainly focuses on manipulating the neural network architectures or hardware configurations instead of benefiting from the aggregated results of multiple models. In this paper, we introduce PenSLR, a glove-based sign language system consisting of an Inertial Measurement Unit (IMU) and five flexible sensors powered by a deep learning framework capable of predicting variable-length sequences. We achieve this in an end-to-end manner by leveraging the Connectionist Temporal Classification (CTC) loss function, eliminating the need for segmentation of input signals. To further enhance its capabilities, we propose a novel ensembling technique by leveraging a multiple sequence alignment algorithm known as Star Alignment. Furthermore, we introduce a new PSL dataset, including 16 PSL signs with more than 3000 time-series samples in total. We utilize this dataset to evaluate the performance of our system based on four word-level and sentence-level metrics. Our evaluations show that PenSLR achieves a remarkable word accuracy of 94.58% and 96.70% in subject-independent and subject-dependent setups, respectively. These achievements are attributable to our ensembling algorithm, which not only boosts the word-level performance by 0.51% and 1.32% in the respective scenarios but also yields significant enhancements of 1.46% and 4.00%, respectively, in sentence-level accuracy.
SLPL SHROOM at SemEval2024 Task 06: A comprehensive study on models ability to detect hallucination
Apr 09, 2024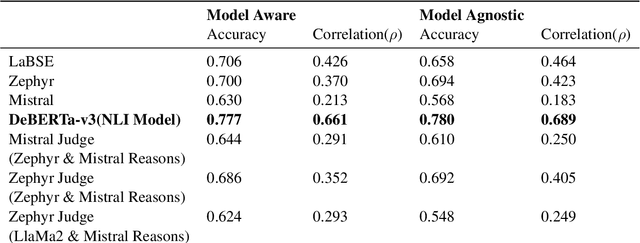
Language models, particularly generative models, are susceptible to hallucinations, generating outputs that contradict factual knowledge or the source text. This study explores methods for detecting hallucinations in three SemEval-2024 Task 6 tasks: Machine Translation, Definition Modeling, and Paraphrase Generation. We evaluate two methods: semantic similarity between the generated text and factual references, and an ensemble of language models that judge each other's outputs. Our results show that semantic similarity achieves moderate accuracy and correlation scores in trial data, while the ensemble method offers insights into the complexities of hallucination detection but falls short of expectations. This work highlights the challenges of hallucination detection and underscores the need for further research in this critical area.