 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy Challenges in Meta-Learning: An Investigation on Model-Agnostic Meta-Learning
Jun 01, 2024Meta-learning involves multiple learners, each dedicated to specific tasks, collaborating in a data-constrained setting. In current meta-learning methods, task learners locally learn models from sensitive data, termed support sets. These task learners subsequently share model-related information, such as gradients or loss values, which is computed using another part of the data termed query set, with a meta-learner. The meta-learner employs this information to update its meta-knowledge. Despite the absence of explicit data sharing, privacy concerns persist. This paper examines potential data leakage in a prominent metalearning algorithm, specifically Model-Agnostic Meta-Learning (MAML). In MAML, gradients are shared between the metalearner and task-learners. The primary objective is to scrutinize the gradient and the information it encompasses about the task dataset. Subsequently, we endeavor to propose membership inference attacks targeting the task dataset containing support and query sets. Finally, we explore various noise injection methods designed to safeguard the privacy of task data and thwart potential attacks. Experimental results demonstrate the effectiveness of these attacks on MAML and the efficacy of proper noise injection methods in countering them.
ClusterSeq: Enhancing Sequential Recommender Systems with Clustering based Meta-Learning
Jul 25, 2023In practical scenarios, the effectiveness of sequential recommendation systems is hindered by the user cold-start problem, which arises due to limited interactions for accurately determining user preferences. Previous studies have attempted to address this issue by combining meta-learning with user and item-side information. However, these approaches face inherent challenges in modeling user preference dynamics, particularly for "minor users" who exhibit distinct preferences compared to more common or "major users." To overcome these limitations, we present a novel approach called ClusterSeq, a Meta-Learning Clustering-Based Sequential Recommender System. ClusterSeq leverages dynamic information in the user sequence to enhance item prediction accuracy, even in the absence of side information. This model preserves the preferences of minor users without being overshadowed by major users, and it capitalizes on the collective knowledge of users within the same cluster. Extensive experiments conducted on various benchmark datasets validate the effectiveness of ClusterSeq. Empirical results consistently demonstrate that ClusterSeq outperforms several state-of-the-art meta-learning recommenders. Notably, compared to existing meta-learning methods, our proposed approach achieves a substantial improvement of 16-39% in Mean Reciprocal Rank (MRR).
News Labeling as Early as Possible: Real or Fake?
Jun 08, 2019
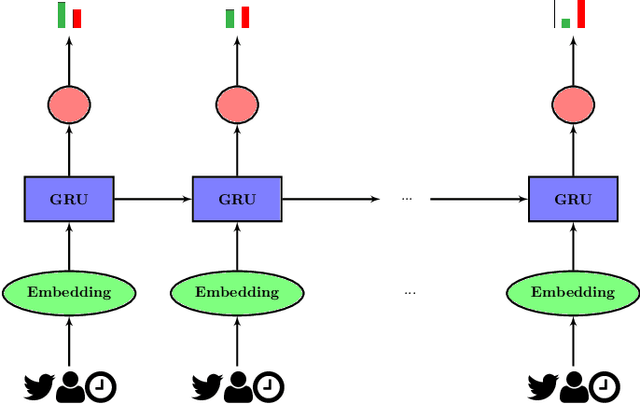

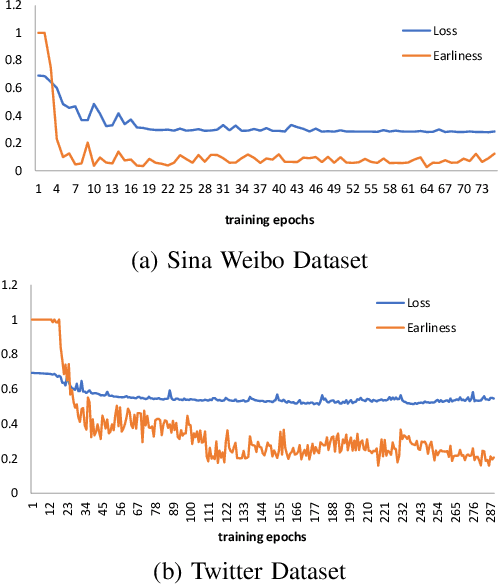
Making disguise between real and fake news propagation through online social networks is an important issue in many applications. The time gap between the news release time and detection of its label is a significant step towards broadcasting the real information and avoiding the fake. Therefore, one of the challenging tasks in this area is to identify fake and real news in early stages of propagation. However, there is a trade-off between minimizing the time gap and maximizing accuracy. Despite recent efforts in detection of fake news, there has been no significant work that explicitly incorporates early detection in its model. In this paper, we focus on accurate early labeling of news, and propose a model by considering earliness both in modeling and prediction. The proposed method utilizes recurrent neural networks with a novel loss function, and a new stopping rule. Given the context of news, we first embed it with a class-specific text representation. Then, we utilize the available public profile of users, and speed of news diffusion, for early labeling of the news. Experiments on real datasets demonstrate the effectiveness of our model both in terms of early labelling and accuracy, compared to the state of the art baseline and models.