 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigher Order Transformers: Enhancing Stock Movement Prediction On Multimodal Time-Series Data
Dec 13, 2024In this paper, we tackle the challenge of predicting stock movements in financial markets by introducing Higher Order Transformers, a novel architecture designed for processing multivariate time-series data. We extend the self-attention mechanism and the transformer architecture to a higher order, effectively capturing complex market dynamics across time and variables. To manage computational complexity, we propose a low-rank approximation of the potentially large attention tensor using tensor decomposition and employ kernel attention, reducing complexity to linear with respect to the data size. Additionally, we present an encoder-decoder model that integrates technical and fundamental analysis, utilizing multimodal signals from historical prices and related tweets. Our experiments on the Stocknet dataset demonstrate the effectiveness of our method, highlighting its potential for enhancing stock movement prediction in financial markets.
Higher Order Transformers: Efficient Attention Mechanism for Tensor Structured Data
Dec 04, 2024



Transformers are now ubiquitous for sequence modeling tasks, but their extension to multi-dimensional data remains a challenge due to the quadratic cost of the attention mechanism. In this paper, we propose Higher-Order Transformers (HOT), a novel architecture designed to efficiently process data with more than two axes, i.e. higher-order tensors. To address the computational challenges associated with high-order tensor attention, we introduce a novel Kronecker factorized attention mechanism that reduces the attention cost to quadratic in each axis' dimension, rather than quadratic in the total size of the input tensor. To further enhance efficiency, HOT leverages kernelized attention, reducing the complexity to linear. This strategy maintains the model's expressiveness while enabling scalable attention computation. We validate the effectiveness of HOT on two high-dimensional tasks, including multivariate time series forecasting, and 3D medical image classification. Experimental results demonstrate that HOT achieves competitive performance while significantly improving computational efficiency, showcasing its potential for tackling a wide range of complex, multi-dimensional data.
News Labeling as Early as Possible: Real or Fake?
Jun 08, 2019
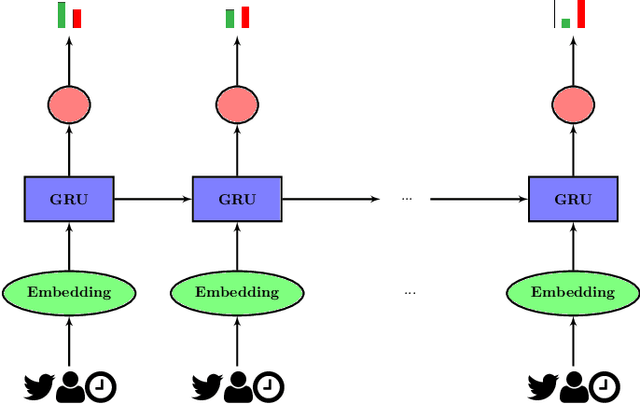

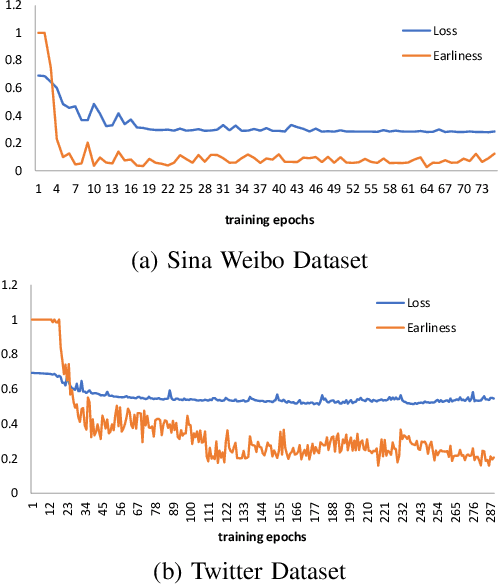
Making disguise between real and fake news propagation through online social networks is an important issue in many applications. The time gap between the news release time and detection of its label is a significant step towards broadcasting the real information and avoiding the fake. Therefore, one of the challenging tasks in this area is to identify fake and real news in early stages of propagation. However, there is a trade-off between minimizing the time gap and maximizing accuracy. Despite recent efforts in detection of fake news, there has been no significant work that explicitly incorporates early detection in its model. In this paper, we focus on accurate early labeling of news, and propose a model by considering earliness both in modeling and prediction. The proposed method utilizes recurrent neural networks with a novel loss function, and a new stopping rule. Given the context of news, we first embed it with a class-specific text representation. Then, we utilize the available public profile of users, and speed of news diffusion, for early labeling of the news. Experiments on real datasets demonstrate the effectiveness of our model both in terms of early labelling and accuracy, compared to the state of the art baseline and models.