 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Combinatorial Node Selection and Resource Allocations in the Lightning Network using Attention-based Reinforcement Learning
Nov 26, 2024



The Lightning Network (LN) has emerged as a second-layer solution to Bitcoin's scalability challenges. The rise of Payment Channel Networks (PCNs) and their specific mechanisms incentivize individuals to join the network for profit-making opportunities. According to the latest statistics, the total value locked within the Lightning Network is approximately \$500 million. Meanwhile, joining the LN with the profit-making incentives presents several obstacles, as it involves solving a complex combinatorial problem that encompasses both discrete and continuous control variables related to node selection and resource allocation, respectively. Current research inadequately captures the critical role of resource allocation and lacks realistic simulations of the LN routing mechanism. In this paper, we propose a Deep Reinforcement Learning (DRL) framework, enhanced by the power of transformers, to address the Joint Combinatorial Node Selection and Resource Allocation (JCNSRA) problem. We have improved upon an existing environment by introducing modules that enhance its routing mechanism, thereby narrowing the gap with the actual LN routing system and ensuring compatibility with the JCNSRA problem. We compare our model against several baselines and heuristics, demonstrating its superior performance across various settings. Additionally, we address concerns regarding centralization in the LN by deploying our agent within the network and monitoring the centrality measures of the evolved graph. Our findings suggest not only an absence of conflict between LN's decentralization goals and individuals' revenue-maximization incentives but also a positive association between the two.
Emo3D: Metric and Benchmarking Dataset for 3D Facial Expression Generation from Emotion Description
Oct 02, 2024
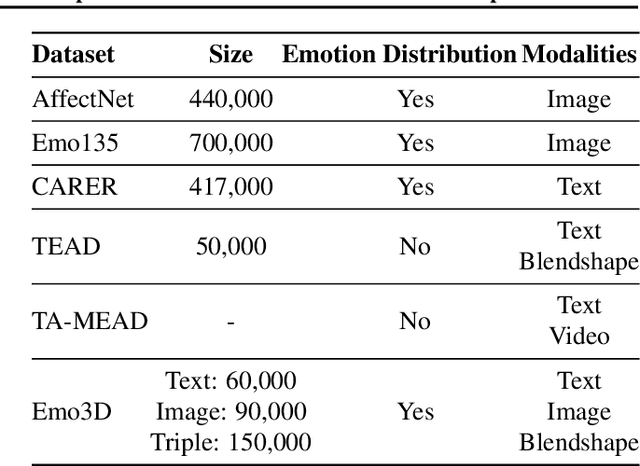

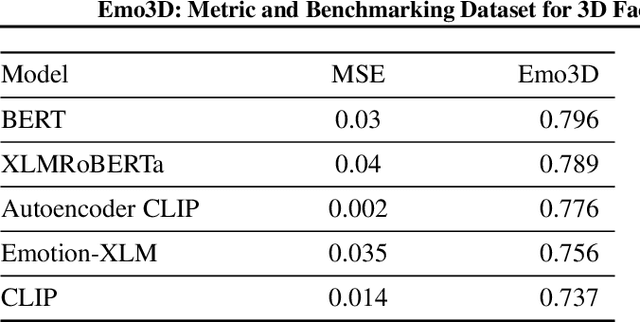
Existing 3D facial emotion modeling have been constrained by limited emotion classes and insufficient datasets. This paper introduces "Emo3D", an extensive "Text-Image-Expression dataset" spanning a wide spectrum of human emotions, each paired with images and 3D blendshapes. Leveraging Large Language Models (LLMs), we generate a diverse array of textual descriptions, facilitating the capture of a broad spectrum of emotional expressions. Using this unique dataset, we conduct a comprehensive evaluation of language-based models' fine-tuning and vision-language models like Contranstive Language Image Pretraining (CLIP) for 3D facial expression synthesis. We also introduce a new evaluation metric for this task to more directly measure the conveyed emotion. Our new evaluation metric, Emo3D, demonstrates its superiority over Mean Squared Error (MSE) metrics in assessing visual-text alignment and semantic richness in 3D facial expressions associated with human emotions. "Emo3D" has great applications in animation design, virtual reality, and emotional human-computer interaction.