 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTag Recommendation for Online Q&A Communities based on BERT Pre-Training Technique
Oct 10, 2020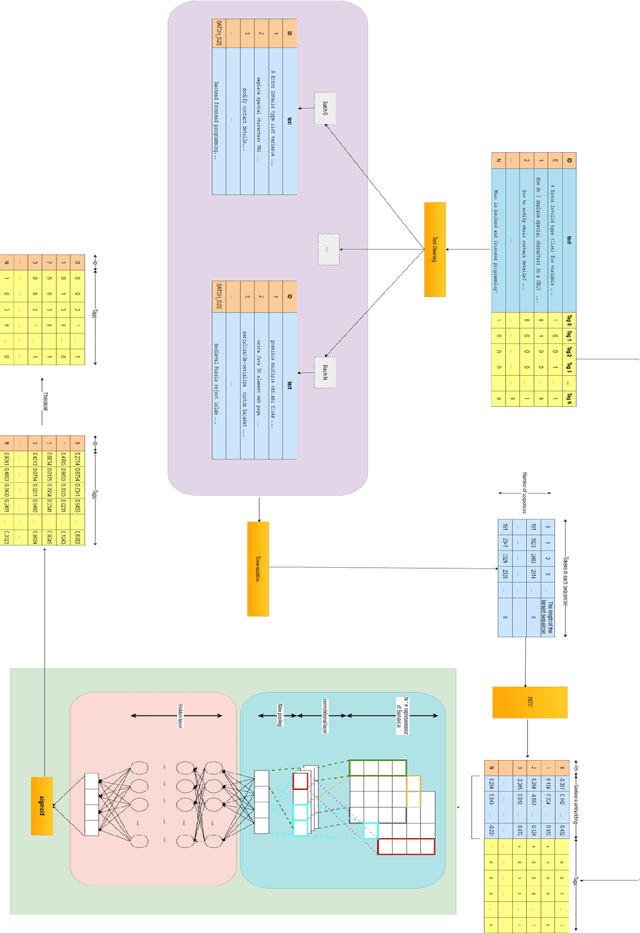
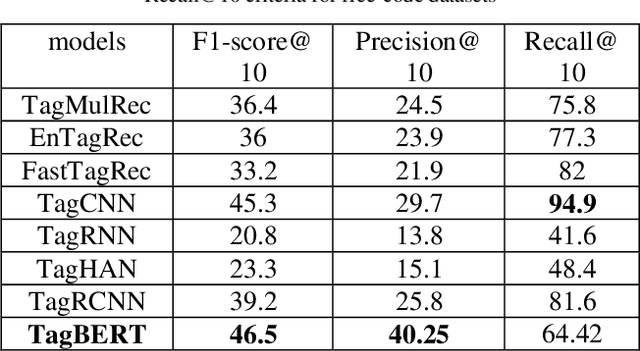
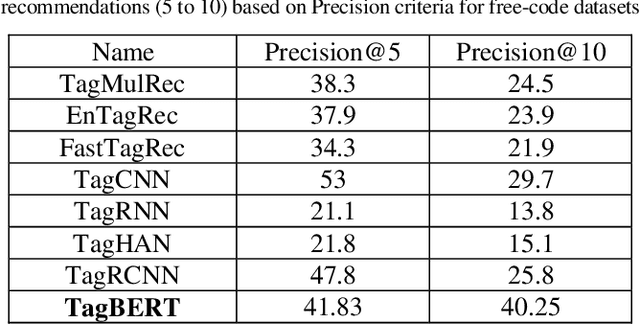
Online Q&A and open source communities use tags and keywords to index, categorize, and search for specific content. The most obvious advantage of tag recommendation is the correct classification of information. In this study, we used the BERT pre-training technique in tag recommendation task for online Q&A and open-source communities for the first time. Our evaluation on freecode datasets show that the proposed method, called TagBERT, is more accurate compared to deep learning and other baseline methods. Moreover, our model achieved a high stability by solving the problem of previous researches, where increasing the number of tag recommendations significantly reduced model performance.
Using Experts' Opinions in Machine Learning Tasks
Aug 10, 2020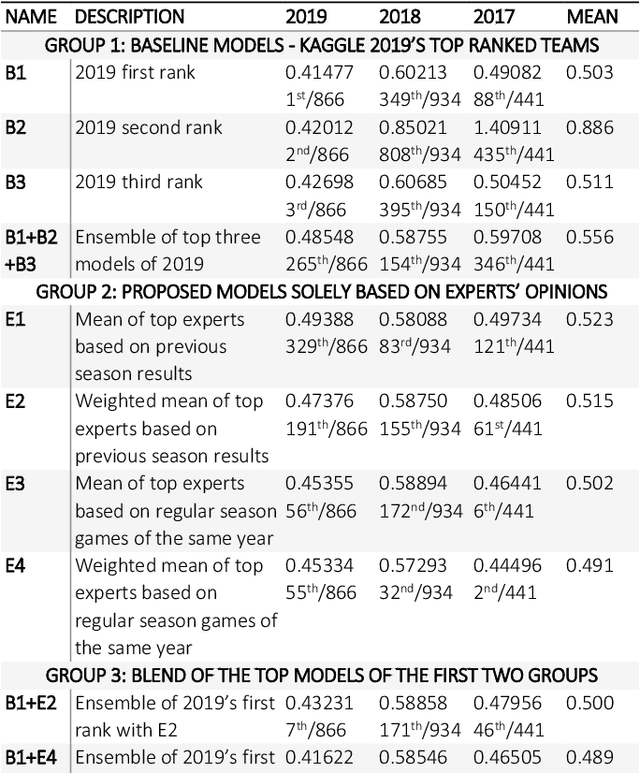
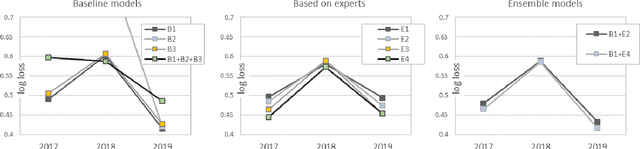
In machine learning tasks, especially in the tasks of prediction, scientists tend to rely solely on available historical data and disregard unproven insights, such as experts' opinions, polls, and betting odds. In this paper, we propose a general three-step framework for utilizing experts' insights in machine learning tasks and build four concrete models for a sports game prediction case study. For the case study, we have chosen the task of predicting NCAA Men's Basketball games, which has been the focus of a group of Kaggle competitions in recent years. Results highly suggest that the good performance and high scores of the past models are a result of chance, and not because of a good-performing and stable model. Furthermore, our proposed models can achieve more steady results with lower log loss average (best at 0.489) compared to the top solutions of the 2019 competition (>0.503), and reach the top 1%, 10% and 1% in the 2017, 2018 and 2019 leaderboards, respectively.
ColBERT: Using BERT Sentence Embedding for Humor Detection
Apr 27, 2020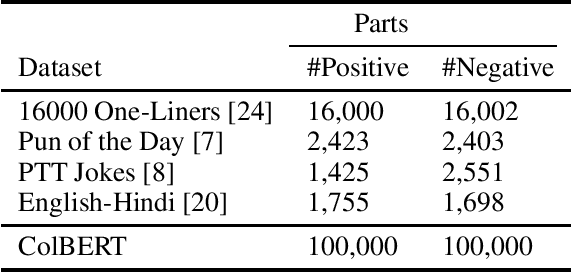

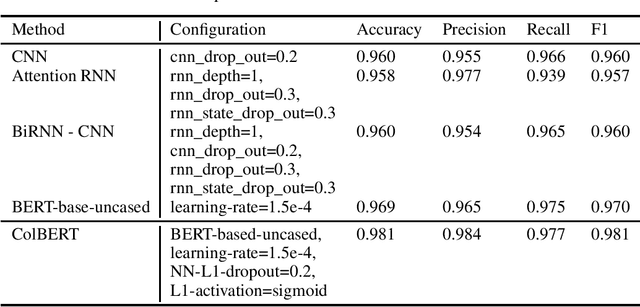
Automatic humor detection has interesting use cases in modern technologies, such as chatbots and personal assistants. In this paper, we describe a novel approach for detecting humor in short texts using BERT sentence embedding. Our proposed model uses BERT to generate tokens and sentence embedding for texts. It sends embedding outputs as input to a two-layered neural network that predicts the target value. For evaluation, we created a new dataset for humor detection consisting of 200k formal short texts (100k positive, 100k negative). Experimental results show an accuracy of 98.1 percent for the proposed method, 2.1 percent improvement compared to the best CNN and RNN models and 1.1 percent better than a fine-tuned BERT model. In addition, the combination of RNN-CNN was not successful in this task compared to the CNN model.
Predicting Subjective Features from Questions on QA Websites using BERT
Mar 25, 2020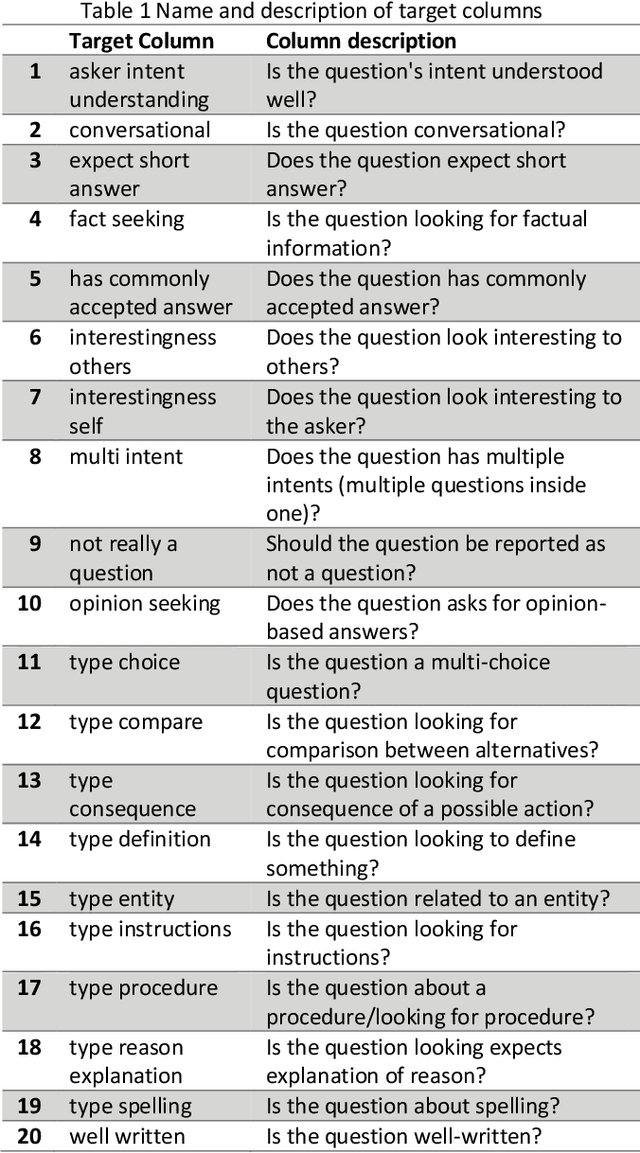
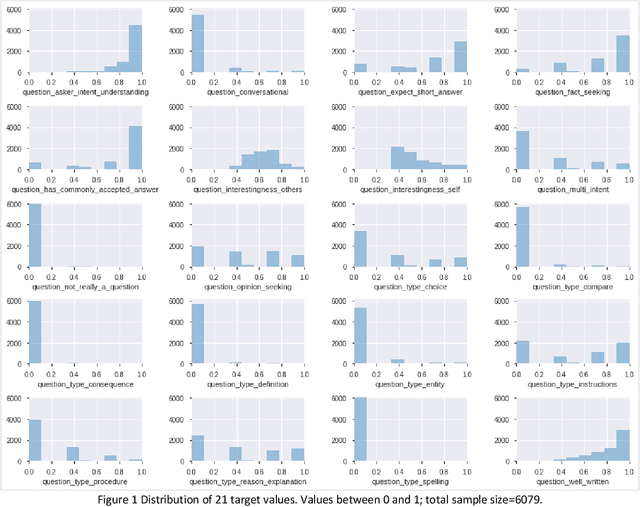
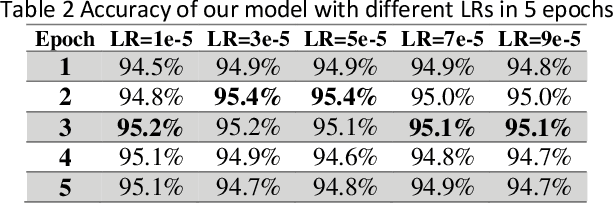
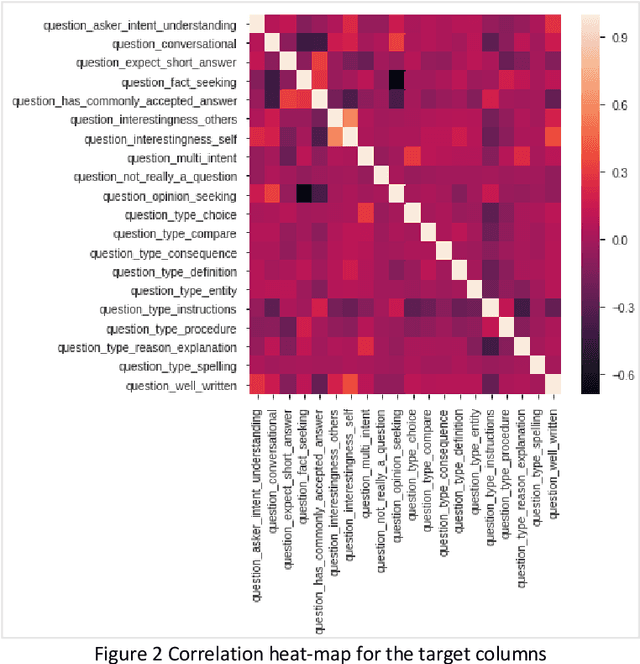
Community Question-Answering websites, such as StackOverflow and Quora, expect users to follow specific guidelines in order to maintain content quality. These systems mainly rely on community reports for assessing contents, which has serious problems such as the slow handling of violations, the loss of normal and experienced users' time, the low quality of some reports, and discouraging feedback to new users. Therefore, with the overall goal of providing solutions for automating moderation actions in Q&A websites, we aim to provide a model to predict 20 quality or subjective aspects of questions in QA websites. To this end, we used data gathered by the CrowdSource team at Google Research in 2019 and fine-tuned pre-trained BERT model on our problem. Based on evaluation by Mean-Squared-Error (MSE), model achieved the value of 0.046 after 2 epochs of training, which did not improve substantially in the next ones. Results confirm that by simple fine-tuning, we can achieve accurate models in little time and on less amount of data.
A Comprehensive Analysis of Twitter Trending Topics
Jul 21, 2019
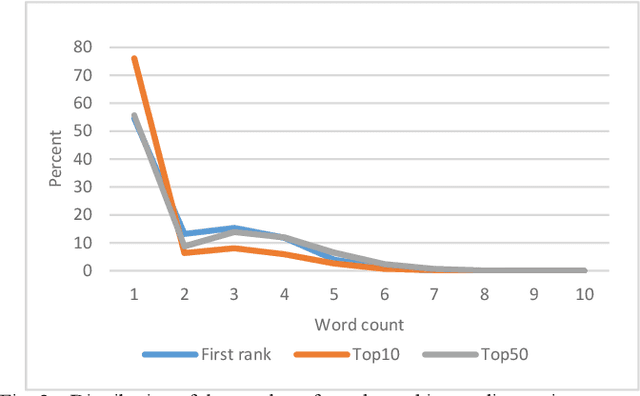

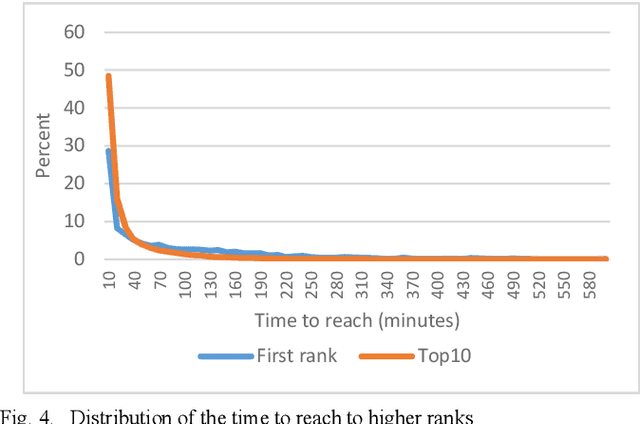
Twitter is among the most used microblogging and online social networking services. In Twitter, a name, phrase, or topic that is mentioned at a greater rate than others is called a "trending topic" or simply "trend". Twitter trends has shown their powerful ability in many public events, elections and market changes. Nevertheless, there has been very few works focusing on understanding the dynamics of these trending topics. In this article, we thoroughly examined the Twitter's trending topics of 2018. To this end, we accessed Twitter's trends API for the full year of 2018 and devised six criteria to analyze our dataset. These six criteria are: lexical analysis, time to reach, trend reoccurrence, trending time, tweets count, and language analysis. In addition to providing general statistics and top trending topics regarding each criterion, we computed several distributions that explain this bulk of data.
* 6 pages, 8 figures, 3 tables, conference paper