 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing LLM-Based Code Generation with Complexity Metrics: A Feedback-Driven Approach
May 29, 2025Automatic code generation has gained significant momentum with the advent of Large Language Models (LLMs) such as GPT-4. Although many studies focus on improving the effectiveness of LLMs for code generation, very limited work tries to understand the generated code's characteristics and leverage that to improve failed cases. In this paper, as the most straightforward characteristic of code, we investigate the relationship between code complexity and the success of LLM generated code. Using a large set of standard complexity metrics, we first conduct an empirical analysis to explore their correlation with LLM's performance on code generation (i.e., Pass@1). Using logistic regression models, we identify which complexity metrics are most predictive of code correctness. Building on these findings, we propose an iterative feedback method, where LLMs are prompted to generate correct code based on complexity metrics from previous failed outputs. We validate our approach across multiple benchmarks (i.e., HumanEval, MBPP, LeetCode, and BigCodeBench) and various LLMs (i.e., GPT-4o, GPT-3.5 Turbo, Llama 3.1, and GPT-o3 mini), comparing the results with two baseline methods: (a) zero-shot generation, and (b) iterative execution-based feedback without our code complexity insights. Experiment results show that our approach makes notable improvements, particularly with a smaller LLM (GPT3.5 Turbo), where, e.g., Pass@1 increased by 35.71% compared to the baseline's improvement of 12.5% on the HumanEval dataset. The study expands experiments to BigCodeBench and integrates the method with the Reflexion code generation agent, leading to Pass@1 improvements of 20% (GPT-4o) and 23.07% (GPT-o3 mini). The results highlight that complexity-aware feedback enhances both direct LLM prompting and agent-based workflows.
Deep-Bench: Deep Learning Benchmark Dataset for Code Generation
Feb 26, 2025



Deep learning (DL) has revolutionized areas such as computer vision, natural language processing, and more. However, developing DL systems is challenging due to the complexity of DL workflows. Large Language Models (LLMs), such as GPT, Claude, Llama, Mistral, etc., have emerged as promising tools to assist in DL code generation, offering potential solutions to these challenges. Despite this, existing benchmarks such as DS-1000 are limited, as they primarily focus on small DL code snippets related to pre/post-processing tasks and lack a comprehensive coverage of the full DL pipeline, including different DL phases and input data types. To address this, we introduce DeepBench, a novel benchmark dataset designed for function-level DL code generation. DeepBench categorizes DL problems based on three key aspects: phases such as pre-processing, model construction, and training; tasks, including classification, regression, and recommendation; and input data types such as tabular, image, and text. GPT-4o -- the state-of-the-art LLM -- achieved 31% accuracy on DeepBench, significantly lower than its 60% on DS-1000. We observed similar difficulty for other LLMs (e.g., 28% vs. 54% for Claude, 21% vs. 41% for LLaMA, and 15% vs. 20% for Mistral). This result underscores DeepBench's greater complexity. We also construct a taxonomy of issues and bugs found in LLM-generated DL code, which highlights the distinct challenges that LLMs face when generating DL code compared to general code. Furthermore, our analysis also reveals substantial performance variations across categories, with differences of up to 7% among phases and 37% among tasks. These disparities suggest that DeepBench offers valuable insights into the LLMs' performance and areas for potential improvement in the DL domain.
VALTEST: Automated Validation of Language Model Generated Test Cases
Nov 13, 2024Large Language Models (LLMs) have demonstrated significant potential in automating software testing, specifically in generating unit test cases. However, the validation of LLM-generated test cases remains a challenge, particularly when the ground truth is unavailable. This paper introduces VALTEST, a novel framework designed to automatically validate test cases generated by LLMs by leveraging token probabilities. We evaluate VALTEST using nine test suites generated from three datasets (HumanEval, MBPP, and LeetCode) across three LLMs (GPT-4o, GPT-3.5-turbo, and LLama3.1 8b). By extracting statistical features from token probabilities, we train a machine learning model to predict test case validity. VALTEST increases the validity rate of test cases by 6.2% to 24%, depending on the dataset and LLM. Our results suggest that token probabilities are reliable indicators for distinguishing between valid and invalid test cases, which provides a robust solution for improving the correctness of LLM-generated test cases in software testing. In addition, we found that replacing the identified invalid test cases by VALTEST, using a Chain-of-Thought prompting results in a more effective test suite while keeping the high validity rates.
EPiC: Cost-effective Search-based Prompt Engineering of LLMs for Code Generation
Aug 20, 2024



Large Language Models (LLMs) have seen increasing use in various software development tasks, especially in code generation. The most advanced recent methods attempt to incorporate feedback from code execution into prompts to help guide LLMs in generating correct code, in an iterative process. While effective, these methods could be costly and time-consuming due to numerous interactions with the LLM and the extensive token usage. To address this issue, we propose an alternative approach named Evolutionary Prompt Engineering for Code (EPiC), which leverages a lightweight evolutionary algorithm to evolve the original prompts toward better ones that produce high-quality code, with minimal interactions with LLM. Our evaluation against state-of-the-art (SOTA) LLM-based code generation models shows that EPiC outperforms all the baselines in terms of cost-effectiveness.
A Novel Experts Advice Aggregation Framework Using Deep Reinforcement Learning for Portfolio Management
Dec 29, 2022

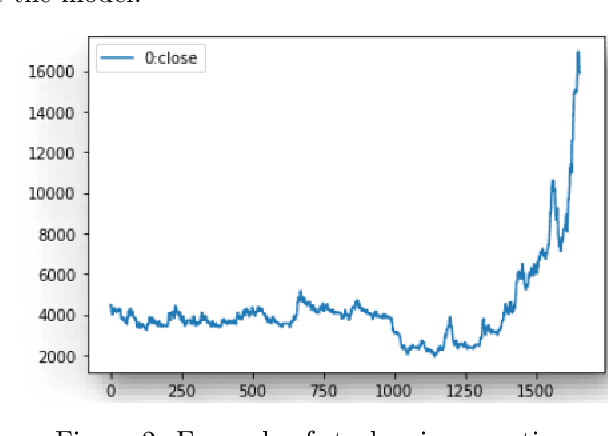

Solving portfolio management problems using deep reinforcement learning has been getting much attention in finance for a few years. We have proposed a new method using experts signals and historical price data to feed into our reinforcement learning framework. Although experts signals have been used in previous works in the field of finance, as far as we know, it is the first time this method, in tandem with deep RL, is used to solve the financial portfolio management problem. Our proposed framework consists of a convolutional network for aggregating signals, another convolutional network for historical price data, and a vanilla network. We used the Proximal Policy Optimization algorithm as the agent to process the reward and take action in the environment. The results suggested that, on average, our framework could gain 90 percent of the profit earned by the best expert.