 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-resource Information Extraction with the European Clinical Case Corpus
Mar 26, 2025We present E3C-3.0, a multilingual dataset in the medical domain, comprising clinical cases annotated with diseases and test-result relations. The dataset includes both native texts in five languages (English, French, Italian, Spanish and Basque) and texts translated and projected from the English source into five target languages (Greek, Italian, Polish, Slovak, and Slovenian). A semi-automatic approach has been implemented, including automatic annotation projection based on Large Language Models (LLMs) and human revision. We present several experiments showing that current state-of-the-art LLMs can benefit from being fine-tuned on the E3C-3.0 dataset. We also show that transfer learning in different languages is very effective, mitigating the scarcity of data. Finally, we compare performance both on native data and on projected data. We release the data at https://huggingface.co/collections/NLP-FBK/e3c-projected-676a7d6221608d60e4e9fd89 .
HeartBERT: A Self-Supervised ECG Embedding Model for Efficient and Effective Medical Signal Analysis
Nov 08, 2024The HeartBert model is introduced with three primary objectives: reducing the need for labeled data, minimizing computational resources, and simultaneously improving performance in machine learning systems that analyze Electrocardiogram (ECG) signals. Inspired by Bidirectional Encoder Representations from Transformers (BERT) in natural language processing and enhanced with a self-supervised learning approach, the HeartBert model-built on the RoBERTa architecture-generates sophisticated embeddings tailored for ECG-based projects in the medical domain. To demonstrate the versatility, generalizability, and efficiency of the proposed model, two key downstream tasks have been selected: sleep stage detection and heartbeat classification. HeartBERT-based systems, utilizing bidirectional LSTM heads, are designed to address complex challenges. A series of practical experiments have been conducted to demonstrate the superiority and advancements of HeartBERT, particularly in terms of its ability to perform well with smaller training datasets, reduced learning parameters, and effective performance compared to rival models. The code and data are publicly available at https://github.com/ecgResearch/HeartBert.
Managing multi-facet bias in collaborative filtering recommender systems
Feb 21, 2023



Due to the extensive growth of information available online, recommender systems play a more significant role in serving people's interests. Traditional recommender systems mostly use an accuracy-focused approach to produce recommendations. Today's research suggests that this single-dimension approach can lead the system to be biased against a series of items with certain attributes. Biased recommendations across groups of items can endanger the interests of item providers along with causing user dissatisfaction with the system. This study aims to manage a new type of intersectional bias regarding the geographical origin and popularity of items in the output of state-of-the-art collaborative filtering recommender algorithms. We introduce an algorithm called MFAIR, a multi-facet post-processing bias mitigation algorithm to alleviate these biases. Extensive experiments on two real-world datasets of movies and books, enriched with the items' continents of production, show that the proposed algorithm strikes a reasonable balance between accuracy and both types of the mentioned biases. According to the results, our proposed approach outperforms a well-known competitor with no or only a slight loss of efficiency.
Multi-Module G2P Converter for Persian Focusing on Relations between Words
Aug 02, 2022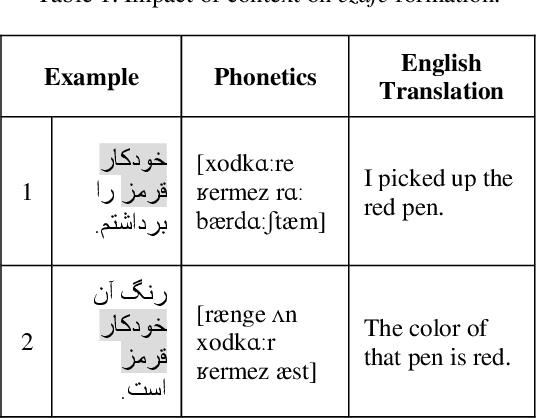
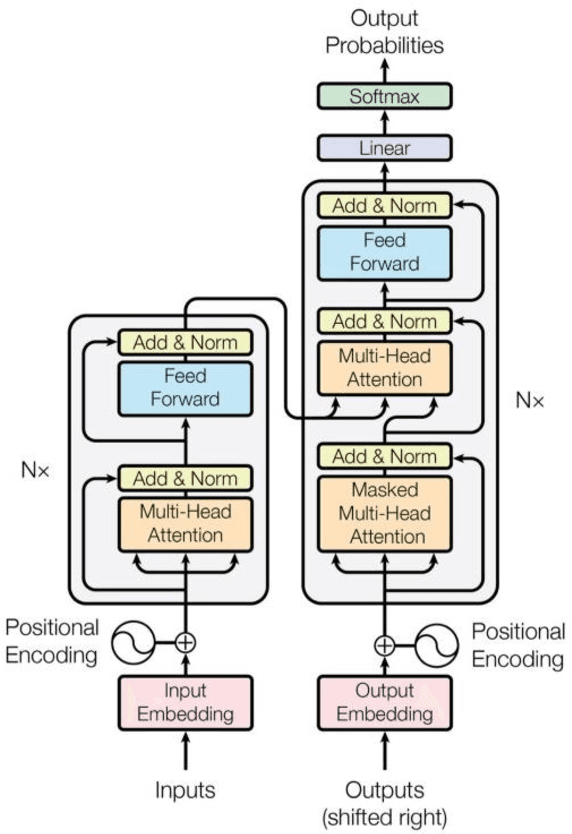
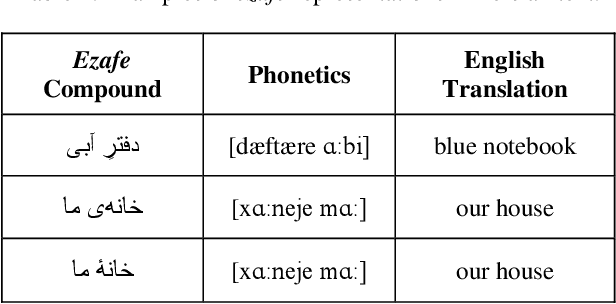
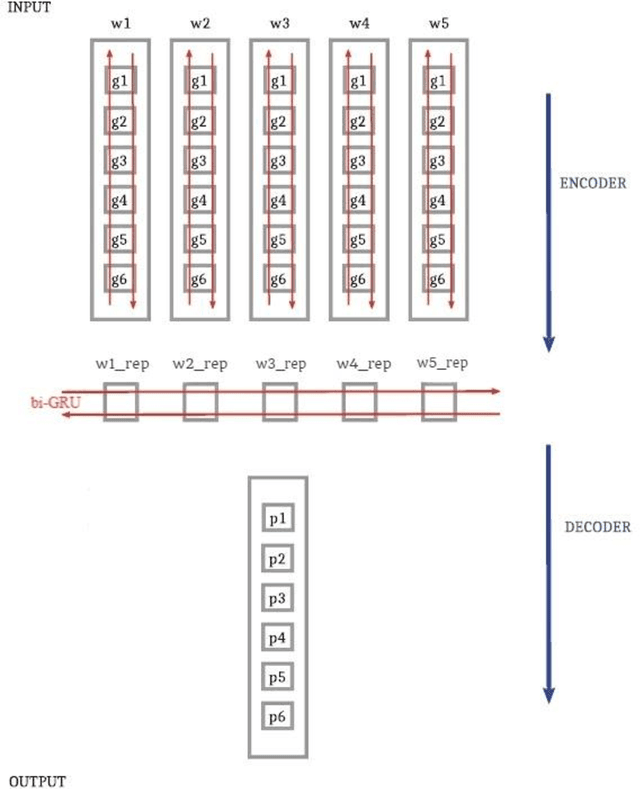
In this paper, we investigate the application of end-to-end and multi-module frameworks for G2P conversion for the Persian language. The results demonstrate that our proposed multi-module G2P system outperforms our end-to-end systems in terms of accuracy and speed. The system consists of a pronunciation dictionary as our look-up table, along with separate models to handle homographs, OOVs and ezafe in Persian created using GRU and Transformer architectures. The system is sequence-level rather than word-level, which allows it to effectively capture the unwritten relations between words (cross-word information) necessary for homograph disambiguation and ezafe recognition without the need for any pre-processing. After evaluation, our system achieved a 94.48% word-level accuracy, outperforming the previous G2P systems for Persian.