 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Module G2P Converter for Persian Focusing on Relations between Words
Aug 02, 2022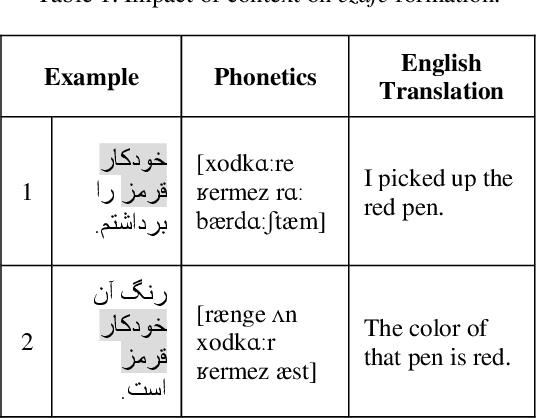
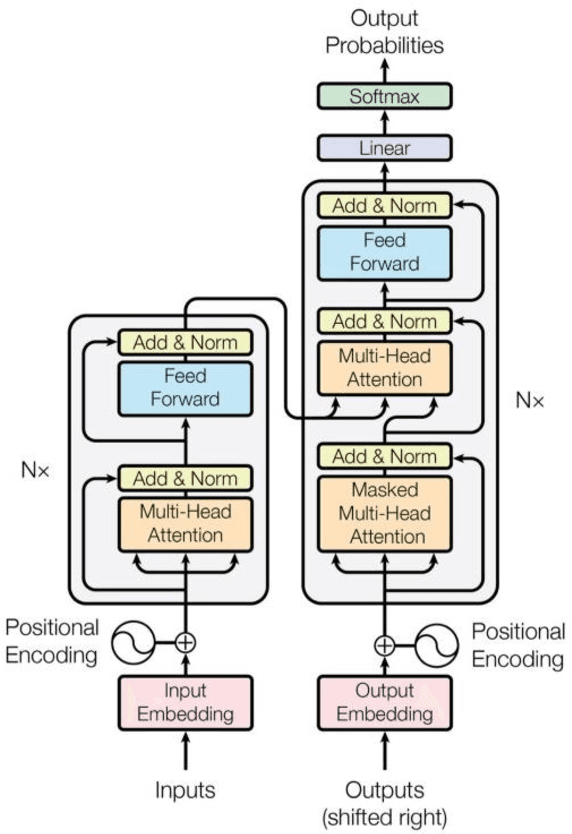
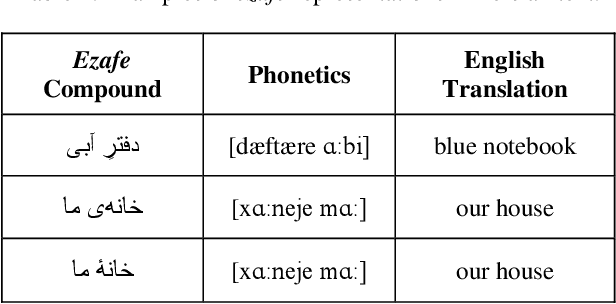
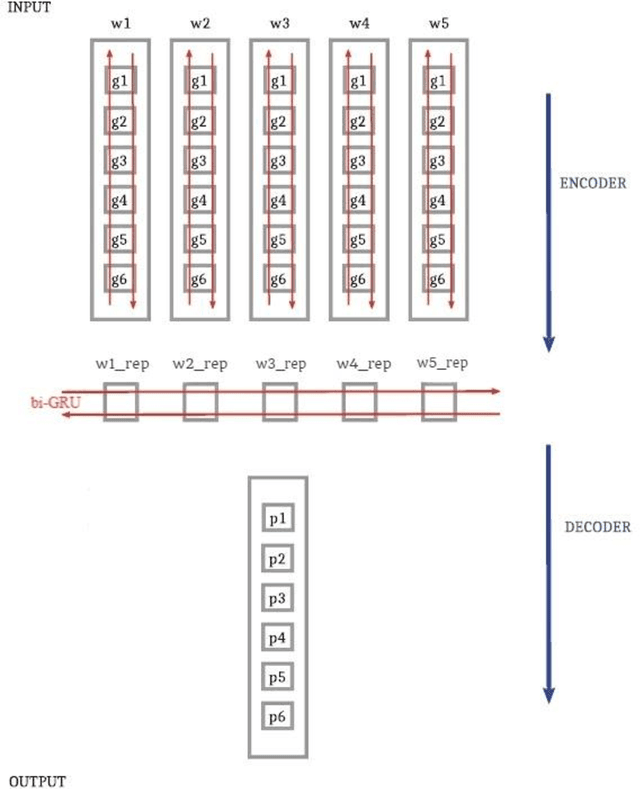
In this paper, we investigate the application of end-to-end and multi-module frameworks for G2P conversion for the Persian language. The results demonstrate that our proposed multi-module G2P system outperforms our end-to-end systems in terms of accuracy and speed. The system consists of a pronunciation dictionary as our look-up table, along with separate models to handle homographs, OOVs and ezafe in Persian created using GRU and Transformer architectures. The system is sequence-level rather than word-level, which allows it to effectively capture the unwritten relations between words (cross-word information) necessary for homograph disambiguation and ezafe recognition without the need for any pre-processing. After evaluation, our system achieved a 94.48% word-level accuracy, outperforming the previous G2P systems for Persian.