 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeconver: A Deconvolutional Network for Medical Image Segmentation
Apr 01, 2025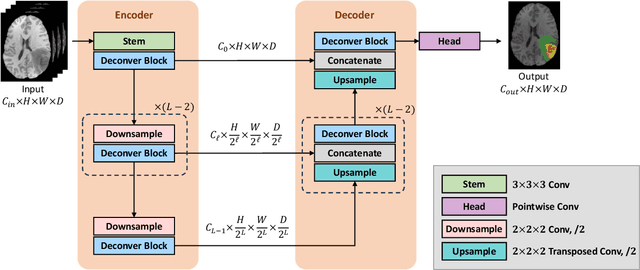
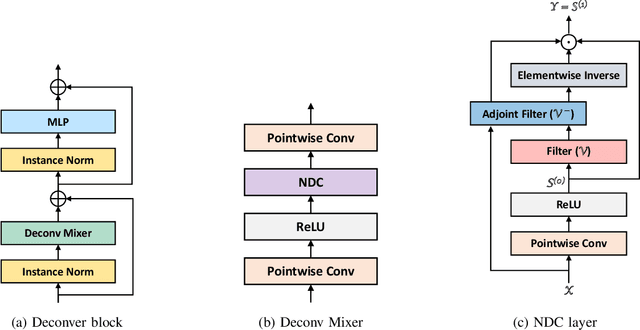
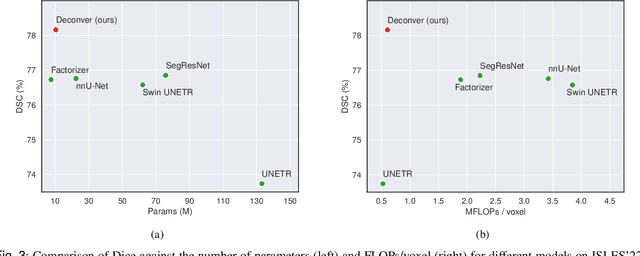
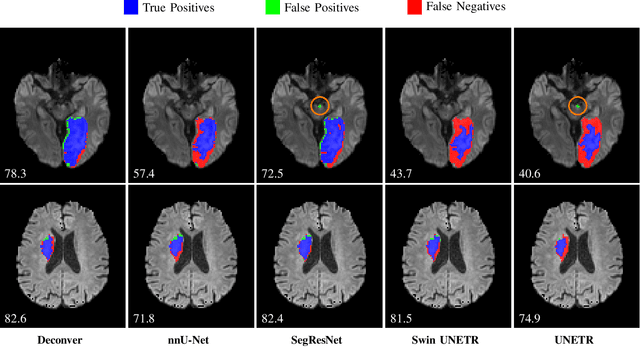
While convolutional neural networks (CNNs) and vision transformers (ViTs) have advanced medical image segmentation, they face inherent limitations such as local receptive fields in CNNs and high computational complexity in ViTs. This paper introduces Deconver, a novel network that integrates traditional deconvolution techniques from image restoration as a core learnable component within a U-shaped architecture. Deconver replaces computationally expensive attention mechanisms with efficient nonnegative deconvolution (NDC) operations, enabling the restoration of high-frequency details while suppressing artifacts. Key innovations include a backpropagation-friendly NDC layer based on a provably monotonic update rule and a parameter-efficient design. Evaluated across four datasets (ISLES'22, BraTS'23, GlaS, FIVES) covering both 2D and 3D segmentation tasks, Deconver achieves state-of-the-art performance in Dice scores and Hausdorff distance while reducing computational costs (FLOPs) by up to 90% compared to leading baselines. By bridging traditional image restoration with deep learning, this work offers a practical solution for high-precision segmentation in resource-constrained clinical workflows. The project is available at https://github.com/pashtari/deconver.
Quantization-free Lossy Image Compression Using Integer Matrix Factorization
Aug 22, 2024



Lossy image compression is essential for efficient transmission and storage. Traditional compression methods mainly rely on discrete cosine transform (DCT) or singular value decomposition (SVD), both of which represent image data in continuous domains and therefore necessitate carefully designed quantizers. Notably, SVD-based methods are more sensitive to quantization errors than DCT-based methods like JPEG. To address this issue, we introduce a variant of integer matrix factorization (IMF) to develop a novel quantization-free lossy image compression method. IMF provides a low-rank representation of the image data as a product of two smaller factor matrices with bounded integer elements, thereby eliminating the need for quantization. We propose an efficient, provably convergent iterative algorithm for IMF using a block coordinate descent (BCD) scheme, with subproblems having closed-form solutions. Our experiments on the Kodak and CLIC 2024 datasets demonstrate that our IMF compression method consistently outperforms JPEG at low bit rates below 0.25 bits per pixel (bpp) and remains comparable at higher bit rates. We also assessed our method's capability to preserve visual semantics by evaluating an ImageNet pre-trained classifier on compressed images. Remarkably, our method improved top-1 accuracy by over 5 percentage points compared to JPEG at bit rates under 0.25 bpp. The project is available at https://github.com/pashtari/lrf .
A Robust Ensemble Algorithm for Ischemic Stroke Lesion Segmentation: Generalizability and Clinical Utility Beyond the ISLES Challenge
Apr 03, 2024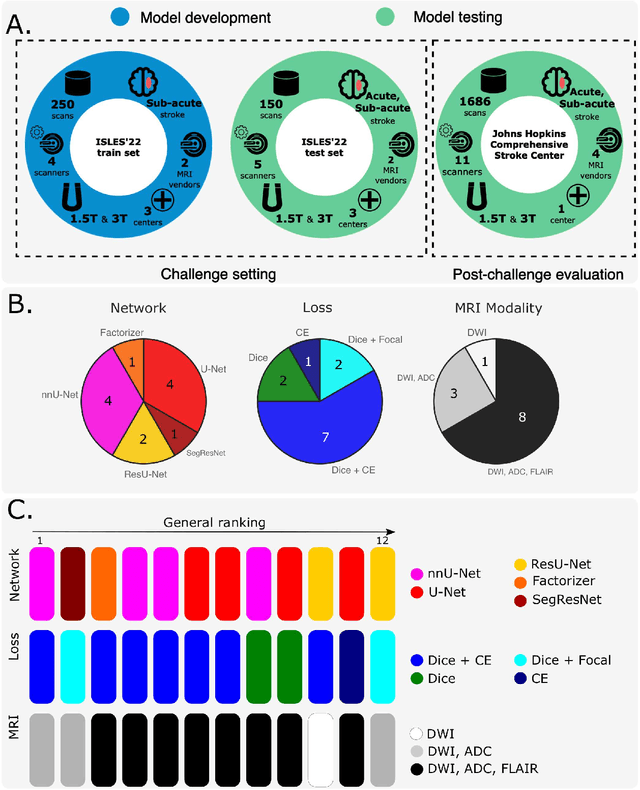
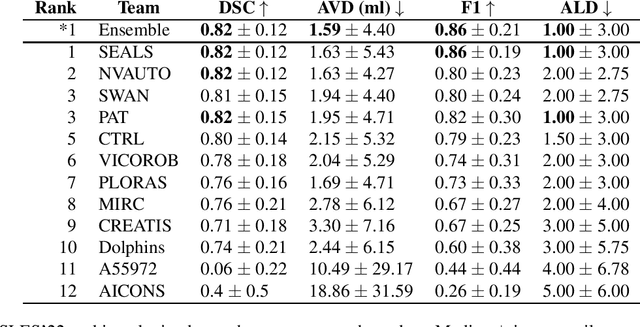
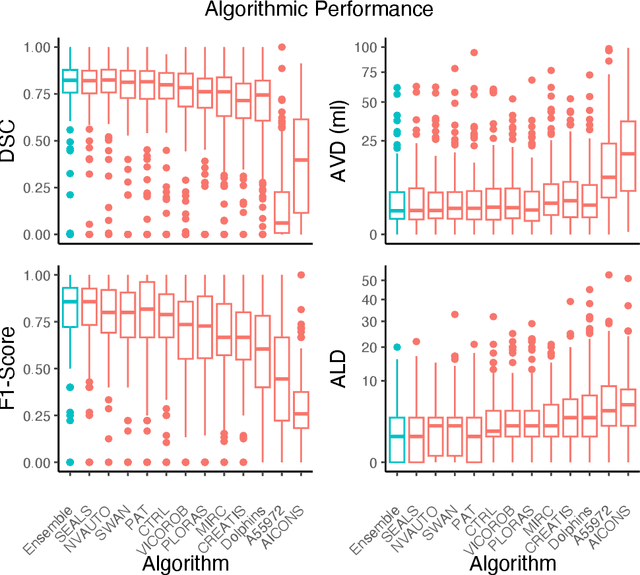
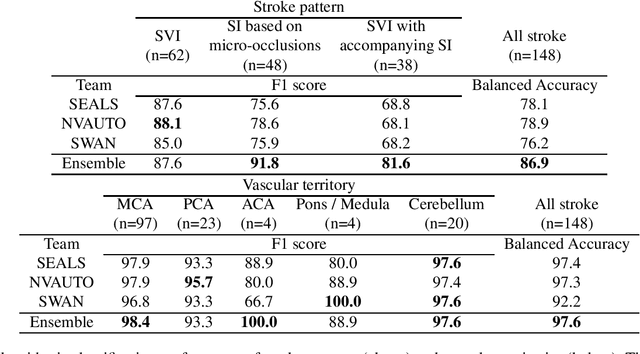
Diffusion-weighted MRI (DWI) is essential for stroke diagnosis, treatment decisions, and prognosis. However, image and disease variability hinder the development of generalizable AI algorithms with clinical value. We address this gap by presenting a novel ensemble algorithm derived from the 2022 Ischemic Stroke Lesion Segmentation (ISLES) challenge. ISLES'22 provided 400 patient scans with ischemic stroke from various medical centers, facilitating the development of a wide range of cutting-edge segmentation algorithms by the research community. Through collaboration with leading teams, we combined top-performing algorithms into an ensemble model that overcomes the limitations of individual solutions. Our ensemble model achieved superior ischemic lesion detection and segmentation accuracy on our internal test set compared to individual algorithms. This accuracy generalized well across diverse image and disease variables. Furthermore, the model excelled in extracting clinical biomarkers. Notably, in a Turing-like test, neuroradiologists consistently preferred the algorithm's segmentations over manual expert efforts, highlighting increased comprehensiveness and precision. Validation using a real-world external dataset (N=1686) confirmed the model's generalizability. The algorithm's outputs also demonstrated strong correlations with clinical scores (admission NIHSS and 90-day mRS) on par with or exceeding expert-derived results, underlining its clinical relevance. This study offers two key findings. First, we present an ensemble algorithm (https://github.com/Tabrisrei/ISLES22_Ensemble) that detects and segments ischemic stroke lesions on DWI across diverse scenarios on par with expert (neuro)radiologists. Second, we show the potential for biomedical challenge outputs to extend beyond the challenge's initial objectives, demonstrating their real-world clinical applicability.
Factorizer: A Scalable Interpretable Approach to Context Modeling for Medical Image Segmentation
Feb 28, 2022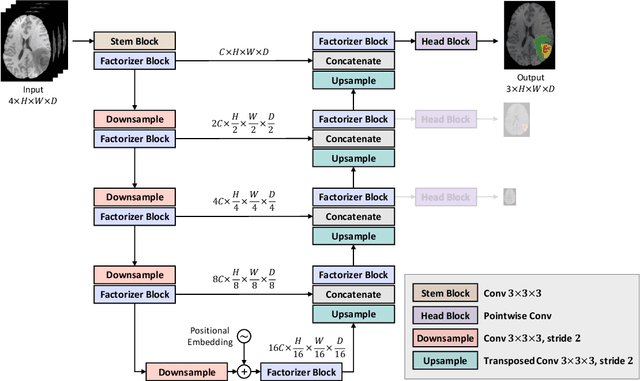
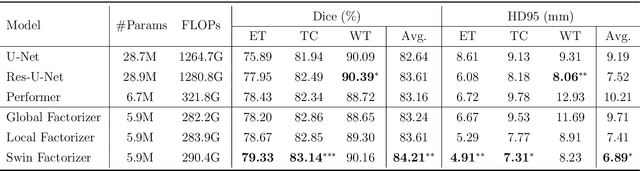

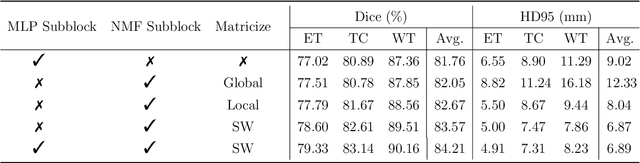
Convolutional Neural Networks (CNNs) with U-shaped architectures have dominated medical image segmentation, which is crucial for various clinical purposes. However, the inherent locality of convolution makes CNNs fail to fully exploit global context, essential for better recognition of some structures, e.g., brain lesions. Transformers have recently proved promising performance on vision tasks, including semantic segmentation, mainly due to their capability of modeling long-range dependencies. Nevertheless, the quadratic complexity of attention makes existing Transformer-based models use self-attention layers only after somehow reducing the image resolution, which limits the ability to capture global contexts present at higher resolutions. Therefore, this work introduces a family of models, dubbed Factorizer, which leverages the power of low-rank matrix factorization for constructing an end-to-end segmentation model. Specifically, we propose a linearly scalable approach to context modeling, formulating Nonnegative Matrix Factorization (NMF) as a differentiable layer integrated into a U-shaped architecture. The shifted window technique is also utilized in combination with NMF to effectively aggregate local information. Factorizers compete favorably with CNNs and Transformers in terms of accuracy, scalability, and interpretability, achieving state-of-the-art results on the BraTS dataset for brain tumor segmentation, with Dice scores of 79.33%, 83.14%, and 90.16% for enhancing tumor, tumor core, and whole tumor, respectively. Highly meaningful NMF components give an additional interpretability advantage to Factorizers over CNNs and Transformers. Moreover, our ablation studies reveal a distinctive feature of Factorizers that enables a significant speed-up in inference for a trained Factorizer without any extra steps and without sacrificing much accuracy.
Supervised Fuzzy Partitioning
Oct 22, 2018
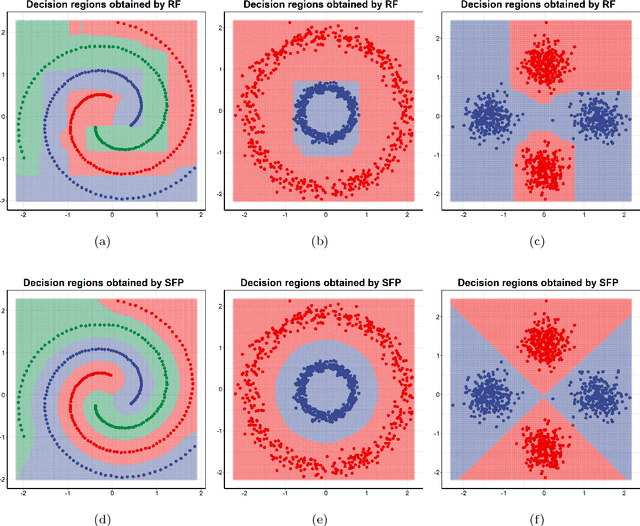
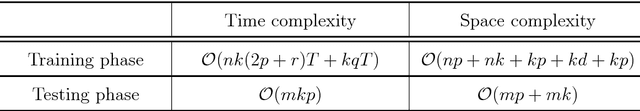
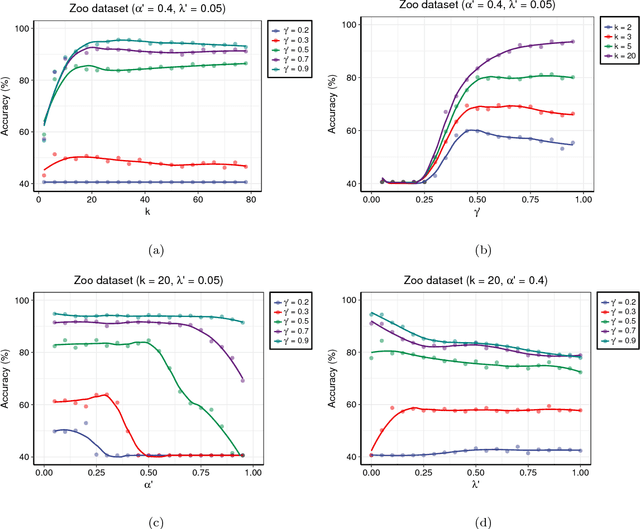
Centroid-based methods including k-means and fuzzy c-means are known as effective and easy-to-implement approaches to clustering purposes in many applications. However, these algorithms cannot be directly applied to supervised tasks. This paper thus presents a generative model extending the centroid-based clustering approach to be applicable to classification and regression tasks. Given an arbitrary loss function, the proposed approach, termed Supervised Fuzzy Partitioning (SFP), incorporates labels information into its objective function through a surrogate term penalizing the empirical risk. Entropy-based regularization is also employed to fuzzify the partition and to weight features, enabling the method to capture more complex patterns, identify significant features, and yield better performance facing high-dimensional data. An iterative algorithm based on block coordinate descent scheme is formulated to efficiently find a local optimum. Extensive classification experiments on synthetic, real-world, and high-dimensional datasets demonstrate that the predictive performance of SFP is competitive with state-of-the-art algorithms such as random forest and SVM. The SFP has a major advantage over such methods, in that it not only leads to a flexible, nonlinear model but also can exploit any convex loss function in the training phase without compromising computational efficiency.