 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Multichannel Wiener Filtering for Wireless Acoustic Sensor Networks
Mar 10, 2026In a wireless acoustic sensor network (WASN), devices (i.e., nodes) can collaborate through distributed algorithms to collectively perform audio signal processing tasks. This paper focuses on the distributed estimation of node-specific desired speech signals using network-wide Wiener filtering. The objective is to match the performance of a centralized system that would have access to all microphone signals, while reducing the communication bandwidth usage of the algorithm. Existing solutions, such as the distributed adaptive node-specific signal estimation (DANSE) algorithm, converge towards the multichannel Wiener filter (MWF) which solves a centralized linear minimum mean square error (LMMSE) signal estimation problem. However, they do so iteratively, which can be slow and impractical. Many solutions also assume that all nodes observe the same set of sources of interest, which is often not the case in practice. To overcome these limitations, we propose the distributed multichannel Wiener filter (dMWF) for fully connected WASNs. The dMWF is non-iterative and optimal even when nodes observe different sets of sources. In this algorithm, nodes exchange neighbor-pair-specific, low-dimensional (fused) signals estimating the contribution of sources observed by both nodes in the pair. We formally prove the optimality of dMWF and demonstrate its performance in simulated speech enhancement experiments. The proposed algorithm is shown to outperform DANSE in terms of objective metrics after short operation times, highlighting the benefit of its iterationless design.
FUTON: Fourier Tensor Network for Implicit Neural Representations
Feb 13, 2026Implicit neural representations (INRs) have emerged as powerful tools for encoding signals, yet dominant MLP-based designs often suffer from slow convergence, overfitting to noise, and poor extrapolation. We introduce FUTON (Fourier Tensor Network), which models signals as generalized Fourier series whose coefficients are parameterized by a low-rank tensor decomposition. FUTON implicitly expresses signals as weighted combinations of orthonormal, separable basis functions, combining complementary inductive biases: Fourier bases capture smoothness and periodicity, while the low-rank parameterization enforces low-dimensional spectral structure. We provide theoretical guarantees through a universal approximation theorem and derive an inference algorithm with complexity linear in the spectral resolution and the input dimension. On image and volume representation, FUTON consistently outperforms state-of-the-art MLP-based INRs while training 2--5$\times$ faster. On inverse problems such as image denoising and super-resolution, FUTON generalizes better and converges faster.
Master-Assisted Distributed Uplink Operation for Cell-Free Massive MIMO Networks
Jan 27, 2026Cell-free massive multiple-input-multiple-output is considered a promising technology for the next generation of wireless communication networks. The main idea is to distribute a large number of access points (APs) in a geographical region to serve the user equipments (UEs) cooperatively. In the uplink, one of two types of operations is often adopted: centralized or distributed. In centralized operation, channel estimation and data decoding are performed at the central processing unit (CPU), whereas in distributed operation, channel estimation occurs at the APs and data detection at the CPU. In this paper, we propose a novel uplink operation, termed Master-Assisted Distributed Uplink Operation (MADUO), where each UE is assigned a master AP, which receives soft data estimates from the other APs and decodes the data using its local signals and the received data estimates. Numerical experiments demonstrate that the proposed operation performs comparably to the centralized operation and balances fronthaul signaling and computational complexity.
Quantization-free Lossy Image Compression Using Integer Matrix Factorization
Aug 22, 2024



Lossy image compression is essential for efficient transmission and storage. Traditional compression methods mainly rely on discrete cosine transform (DCT) or singular value decomposition (SVD), both of which represent image data in continuous domains and therefore necessitate carefully designed quantizers. Notably, SVD-based methods are more sensitive to quantization errors than DCT-based methods like JPEG. To address this issue, we introduce a variant of integer matrix factorization (IMF) to develop a novel quantization-free lossy image compression method. IMF provides a low-rank representation of the image data as a product of two smaller factor matrices with bounded integer elements, thereby eliminating the need for quantization. We propose an efficient, provably convergent iterative algorithm for IMF using a block coordinate descent (BCD) scheme, with subproblems having closed-form solutions. Our experiments on the Kodak and CLIC 2024 datasets demonstrate that our IMF compression method consistently outperforms JPEG at low bit rates below 0.25 bits per pixel (bpp) and remains comparable at higher bit rates. We also assessed our method's capability to preserve visual semantics by evaluating an ImageNet pre-trained classifier on compressed images. Remarkably, our method improved top-1 accuracy by over 5 percentage points compared to JPEG at bit rates under 0.25 bpp. The project is available at https://github.com/pashtari/lrf .
One-Shot Distributed Node-Specific Signal Estimation with Non-Overlapping Latent Subspaces in Acoustic Sensor Networks
Aug 07, 2024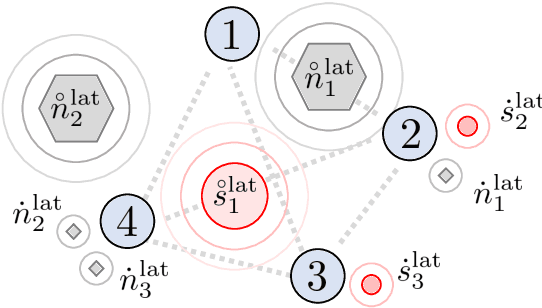
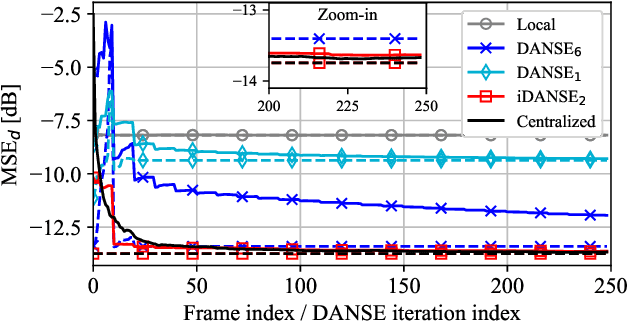
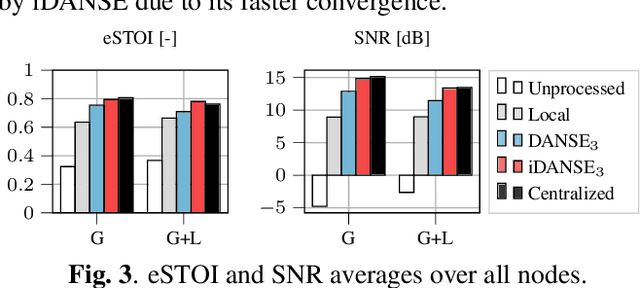
A one-shot algorithm called iterationless DANSE (iDANSE) is introduced to perform distributed adaptive node-specific signal estimation (DANSE) in a fully connected wireless acoustic sensor network (WASN) deployed in an environment with non-overlapping latent signal subspaces. The iDANSE algorithm matches the performance of a centralized algorithm in a single processing cycle while devices exchange fused versions of their multichannel local microphone signals. Key advantages of iDANSE over currently available solutions are its iterationless nature, which favors deployment in real-time applications, and the fact that devices can exchange fewer fused signals than the number of latent sources in the environment. The proposed method is validated in numerical simulations including a speech enhancement scenario.
Zeroth-order Asynchronous Learning with Bounded Delays with a Use-case in Resource Allocation in Communication Networks
Nov 08, 2023Distributed optimization has experienced a significant surge in interest due to its wide-ranging applications in distributed learning and adaptation. While various scenarios, such as shared-memory, local-memory, and consensus-based approaches, have been extensively studied in isolation, there remains a need for further exploration of their interconnections. This paper specifically concentrates on a scenario where agents collaborate toward a unified mission while potentially having distinct tasks. Each agent's actions can potentially impact other agents through interactions. Within this context, the objective for the agents is to optimize their local parameters based on the aggregate of local reward functions, where only local zeroth-order oracles are available. Notably, the learning process is asynchronous, meaning that agents update and query their zeroth-order oracles asynchronously while communicating with other agents subject to bounded but possibly random communication delays. This paper presents theoretical convergence analyses and establishes a convergence rate for the proposed approach. Furthermore, it addresses the relevant issue of deep learning-based resource allocation in communication networks and conducts numerical experiments in which agents, acting as transmitters, collaboratively train their individual (possibly unique) policies to maximize a common performance metric.
A Deep Learning Based Resource Allocator for Communication Systems with Dynamic User Utility Demands
Nov 08, 2023



Deep learning (DL) based resource allocation (RA) has recently gained a lot of attention due to its performance efficiency. However, most of the related studies assume an ideal case where the number of users and their utility demands, e.g., data rate constraints, are fixed and the designed DL based RA scheme exploits a policy trained only for these fixed parameters. A computationally complex policy retraining is required whenever these parameters change. Therefore, in this paper, a DL based resource allocator (ALCOR) is introduced, which allows users to freely adjust their utility demands based on, e.g., their application layer. ALCOR employs deep neural networks (DNNs), as the policy, in an iterative optimization algorithm. The optimization algorithm aims to optimize the on-off status of users in a time-sharing problem to satisfy their utility demands in expectation. The policy performs unconstrained RA (URA) -- RA without taking into account user utility demands -- among active users to maximize the sum utility (SU) at each time instant. Based on the chosen URA scheme, ALCOR can perform RA in a model-based or model-free manner and in a centralized or distributed scenario. Derived convergence analyses provide guarantees for the convergence of ALCOR, and numerical experiments corroborate its effectiveness.
SPIRAL: A Superlinearly Convergent Incremental Proximal Algorithm for Nonconvex Finite Sum Minimization
Jul 17, 2022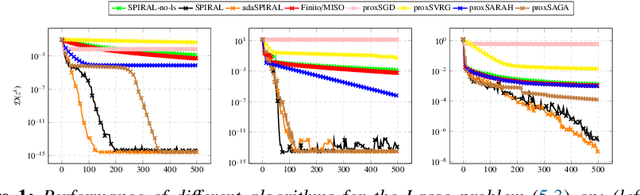
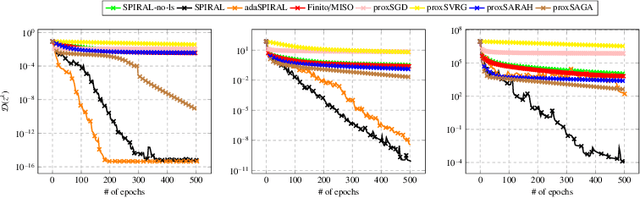

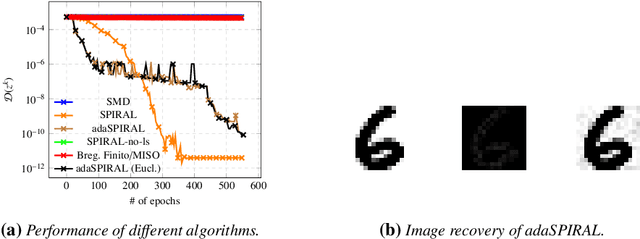
We introduce SPIRAL, a SuPerlinearly convergent Incremental pRoximal ALgorithm, for solving nonconvex regularized finite sum problems under a relative smoothness assumption. In the spirit of SVRG and SARAH, each iteration of SPIRAL consists of an inner and an outer loop. It combines incremental and full (proximal) gradient updates with a linesearch. It is shown that when using quasi-Newton directions, superlinear convergence is attained under mild assumptions at the limit points. More importantly, thanks to said linesearch, global convergence is ensured while it is shown that unit stepsize will be eventually always accepted. Simulation results on different convex, nonconvex, and non-Lipschitz differentiable problems show that our algorithm as well as its adaptive variant are competitive to the state of the art.