 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Shot Distributed Node-Specific Signal Estimation with Non-Overlapping Latent Subspaces in Acoustic Sensor Networks
Aug 07, 2024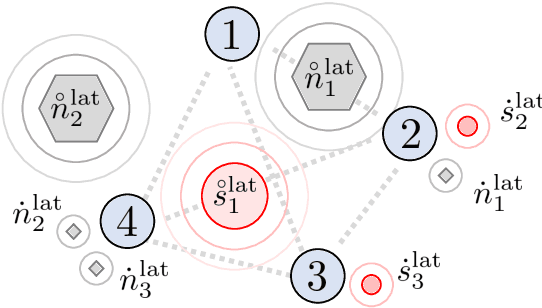
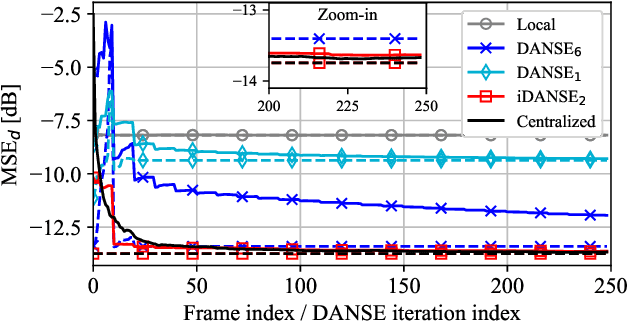
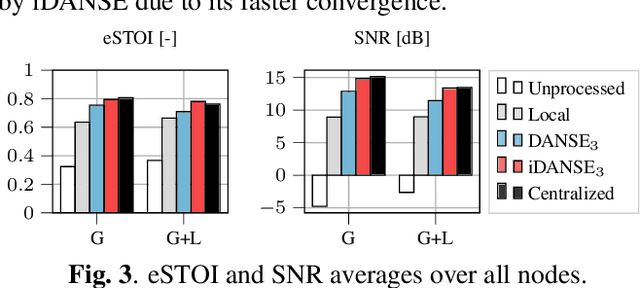
A one-shot algorithm called iterationless DANSE (iDANSE) is introduced to perform distributed adaptive node-specific signal estimation (DANSE) in a fully connected wireless acoustic sensor network (WASN) deployed in an environment with non-overlapping latent signal subspaces. The iDANSE algorithm matches the performance of a centralized algorithm in a single processing cycle while devices exchange fused versions of their multichannel local microphone signals. Key advantages of iDANSE over currently available solutions are its iterationless nature, which favors deployment in real-time applications, and the fact that devices can exchange fewer fused signals than the number of latent sources in the environment. The proposed method is validated in numerical simulations including a speech enhancement scenario.
Topology-Independent GEVD-Based Distributed Adaptive Node-Specific Signal Estimation in Ad-Hoc Wireless Acoustic Sensor Networks
Jul 19, 2024A low-rank approximation-based version of the topology-independent distributed adaptive node-specific signal estimation (TI-DANSE) algorithm is introduced, using a generalized eigenvalue decomposition (GEVD) for application in ad-hoc wireless acoustic sensor networks. This TI-GEVD-DANSE algorithm as well as the original TI-DANSE algorithm exhibit a non-strict convergence, which can lead to numerical instability over time, particularly in scenarios where the estimation of accurate spatial covariance matrices is challenging. An adaptive filter coefficient normalization strategy is proposed to mitigate this issue and enable the stable performance of TI-(GEVD-)DANSE. The method is validated in numerical simulations including dynamic acoustic scenarios, demonstrating the importance of the additional normalization.
Head Orientation Estimation with Distributed Microphones Using Speech Radiation Patterns
Dec 04, 2023



Determining the head orientation of a talker is not only beneficial for various speech signal processing applications, such as source localization or speech enhancement, but also facilitates intuitive voice control and interaction with smart environments or modern car assistants. Most approaches for head orientation estimation are based on visual cues. However, this requires camera systems which often are not available. We present an approach which purely uses audio signals captured with only a few distributed microphones around the talker. Specifically, we propose a novel method that directly incorporates measured or modeled speech radiation patterns to infer the talker's orientation during active speech periods based on a cosine similarity measure. Moreover, an automatic gain adjustment technique is proposed for uncalibrated, irregular microphone setups, such as ad-hoc sensor networks. In experiments with signals recorded in both anechoic and reverberant environments, the proposed method outperforms state-of-the-art approaches, using either measured or modeled speech radiation patterns.
Sampling Rate Offset Estimation and Compensation for Distributed Adaptive Node-Specific Signal Estimation in Wireless Acoustic Sensor Networks
Nov 04, 2022
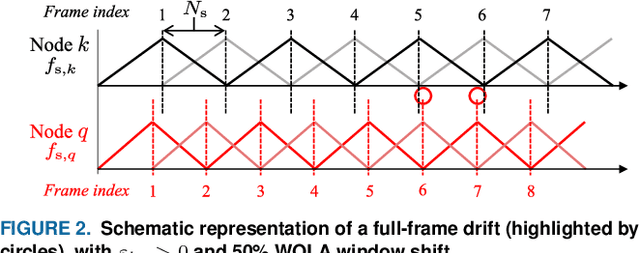
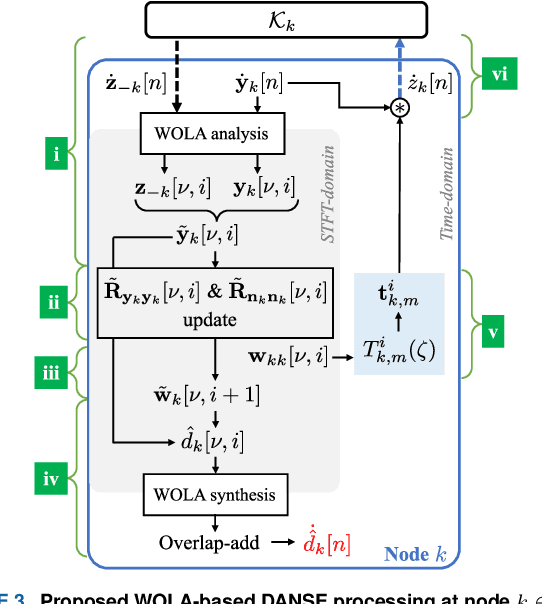

Sampling rate offsets (SROs) between devices in a heterogeneous wireless acoustic sensor network (WASN) can hinder the ability of distributed adaptive algorithms to perform as intended when they rely on coherent signal processing. In this paper, we present an SRO estimation and compensation method to allow the deployment of the distributed adaptive node-specific signal estimation (DANSE) algorithm in WASNs composed of asynchronous devices. The signals available at each node are first utilised in a coherence-drift-based method to blindly estimate SROs which are then compensated for via phase shifts in the frequency domain. A modification of the weighted overlap-add (WOLA) implementation of DANSE is introduced to account for SRO-induced full-sample drifts, permitting per-sample signal transmission via an approximation of the WOLA process as a time-domain convolution. The performance of the proposed algorithm is evaluated in the context of distributed noise reduction for the estimation of a target speech signal in an asynchronous WASN.