 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Multichannel Wiener Filtering for Wireless Acoustic Sensor Networks
Mar 10, 2026In a wireless acoustic sensor network (WASN), devices (i.e., nodes) can collaborate through distributed algorithms to collectively perform audio signal processing tasks. This paper focuses on the distributed estimation of node-specific desired speech signals using network-wide Wiener filtering. The objective is to match the performance of a centralized system that would have access to all microphone signals, while reducing the communication bandwidth usage of the algorithm. Existing solutions, such as the distributed adaptive node-specific signal estimation (DANSE) algorithm, converge towards the multichannel Wiener filter (MWF) which solves a centralized linear minimum mean square error (LMMSE) signal estimation problem. However, they do so iteratively, which can be slow and impractical. Many solutions also assume that all nodes observe the same set of sources of interest, which is often not the case in practice. To overcome these limitations, we propose the distributed multichannel Wiener filter (dMWF) for fully connected WASNs. The dMWF is non-iterative and optimal even when nodes observe different sets of sources. In this algorithm, nodes exchange neighbor-pair-specific, low-dimensional (fused) signals estimating the contribution of sources observed by both nodes in the pair. We formally prove the optimality of dMWF and demonstrate its performance in simulated speech enhancement experiments. The proposed algorithm is shown to outperform DANSE in terms of objective metrics after short operation times, highlighting the benefit of its iterationless design.
Master-Assisted Channel Estimation for Cell-Free Massive MIMO Networks
Feb 27, 2026Cell-free massive-multiple-input-multiple-output (CFmMIMO) is a key enabler for sixth-generation (6G) wireless communication networks, where distributed access points (APs) jointly serve user equipments (UEs). In commonly adopted channel models for CFmMIMO networks, inter-AP channel correlation is assumed to be absent, thereby eliminating the potential benefits of centralized processing. However, by carefully designing the pilot transmission phase, the AP received signals during pilot transmission can become correlated, and thus, centralization can improve channel estimation performance, despite the absence of inter-AP channel correlation. In this paper, we propose a channel estimation scheme, termed master-assisted channel estimation (MACE), that aims to leverage inter-AP signal correlation by means of partially centralized processing and hence improve channel estimation performance. In MACE, a subset of APs fuse and forward their received pilot signals to a master AP, which then performs channel estimation using the fused signals together with its locally received signals. This scheme strikes a balance between local and fully centralized processing by leveraging inter-AP signal correlation, while reducing fronthaul signaling and computational complexity. Numerical experiments demonstrate that MACE consistently outperforms local channel estimation, where inter-AP signal correlation is neglected.
Sequential Processing Strategies in Fronthaul Constrained Cell-Free Massive MIMO Networks
Jan 28, 2026In a cell-free massive MIMO (CFmMIMO) network with a daisy-chain fronthaul, the amount of information that each access point (AP) needs to communicate with the next AP in the chain is determined by the location of the AP in the sequential fronthaul. Therefore, we propose two sequential processing strategies to combat the adverse effect of fronthaul compression on the sum of users' spectral efficiency (SE): 1) linearly increasing fronthaul capacity allocation among APs and 2) Two-Path users' signal estimation. The two strategies show superior performance in terms of sum SE compared to the equal fronthaul capacity allocation and Single-Path sequential signal estimation.
Master-Assisted Distributed Uplink Operation for Cell-Free Massive MIMO Networks
Jan 27, 2026Cell-free massive multiple-input-multiple-output is considered a promising technology for the next generation of wireless communication networks. The main idea is to distribute a large number of access points (APs) in a geographical region to serve the user equipments (UEs) cooperatively. In the uplink, one of two types of operations is often adopted: centralized or distributed. In centralized operation, channel estimation and data decoding are performed at the central processing unit (CPU), whereas in distributed operation, channel estimation occurs at the APs and data detection at the CPU. In this paper, we propose a novel uplink operation, termed Master-Assisted Distributed Uplink Operation (MADUO), where each UE is assigned a master AP, which receives soft data estimates from the other APs and decodes the data using its local signals and the received data estimates. Numerical experiments demonstrate that the proposed operation performs comparably to the centralized operation and balances fronthaul signaling and computational complexity.
A Comparative Analysis of Generalised Echo and Interference Cancelling and Extended Multichannel Wiener Filtering for Combined Noise Reduction and Acoustic Echo Cancellation
Mar 05, 2025
Two algorithms for combined acoustic echo cancellation (AEC) and noise reduction (NR) are analysed, namely the generalised echo and interference canceller (GEIC) and the extended multichannel Wiener filter (MWFext). Previously, these algorithms have been examined for linear echo paths, and assuming access to voice activity detectors (VADs) that separately detect desired speech and echo activity. However, algorithms implementing VADs may introduce detection errors. Therefore, in this paper, the previous analyses are extended by 1) modelling general nonlinear echo paths by means of the generalised Bussgang decomposition, and 2) modelling VAD error effects in each specific algorithm, thereby also allowing to model specific VAD assumptions. It is found and verified with simulations that, generally, the MWFext achieves a higher NR performance, while the GEIC achieves a more robust AEC performance.
Integrated Minimum Mean Squared Error Algorithms for Combined Acoustic Echo Cancellation and Noise Reduction
Dec 05, 2024



In many speech recording applications, noise and acoustic echo corrupt the desired speech. Consequently, combined noise reduction (NR) and acoustic echo cancellation (AEC) is required. Generally, a cascade approach is followed, i.e., the AEC and NR are designed in isolation by selecting a separate signal model, formulating a separate cost function, and using a separate solution strategy. The AEC and NR are then cascaded one after the other, not accounting for their interaction. In this paper, however, an integrated approach is proposed to consider this interaction in a general multi-microphone/multi-loudspeaker setup. Therefore, a single signal model of either the microphone signal vector or the extended signal vector, obtained by stacking microphone and loudspeaker signals, is selected, a single mean squared error cost function is formulated, and a common solution strategy is used. Using this microphone signal model, a multi channel Wiener filter (MWF) is derived. Using the extended signal model, an extended MWF (MWFext) is derived, and several equivalent expressions are found, which nevertheless are interpretable as cascade algorithms. Specifically, the MWFext is shown to be equivalent to algorithms where the AEC precedes the NR (AEC NR), the NR precedes the AEC (NR-AEC), and the extended NR (NRext) precedes the AEC and post-filter (PF) (NRext-AECPF). Under rank-deficiency conditions the MWFext is non-unique, such that this equivalence amounts to the expressions being specific, not necessarily minimum-norm solutions for this MWFext. The practical performances nonetheless differ due to non-stationarities and imperfect correlation matrix estimation, resulting in the AEC-NR and NRext-AEC-PF attaining best overall performance.
One-Shot Distributed Node-Specific Signal Estimation with Non-Overlapping Latent Subspaces in Acoustic Sensor Networks
Aug 07, 2024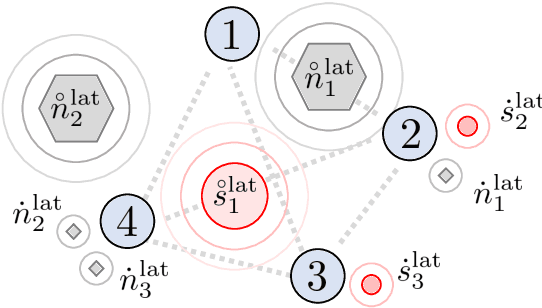
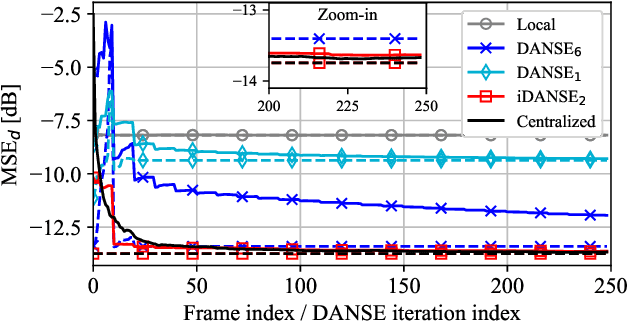
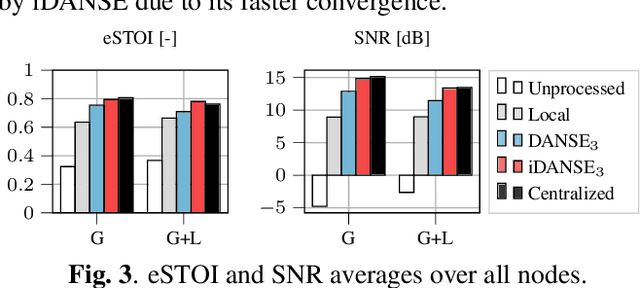
A one-shot algorithm called iterationless DANSE (iDANSE) is introduced to perform distributed adaptive node-specific signal estimation (DANSE) in a fully connected wireless acoustic sensor network (WASN) deployed in an environment with non-overlapping latent signal subspaces. The iDANSE algorithm matches the performance of a centralized algorithm in a single processing cycle while devices exchange fused versions of their multichannel local microphone signals. Key advantages of iDANSE over currently available solutions are its iterationless nature, which favors deployment in real-time applications, and the fact that devices can exchange fewer fused signals than the number of latent sources in the environment. The proposed method is validated in numerical simulations including a speech enhancement scenario.
Cell-free Massive MIMO with Sequential Fronthaul Architecture and Limited Memory Access Points
Jul 31, 2024



Cell-free massive multiple-input multiple-output (CFmMIMO) is a paradigm that can improve users' spectral efficiency (SE) far beyond traditional cellular networks. Increased spatial diversity in CFmMIMO is achieved by spreading the antennas into small access points (APs), which cooperate to serve the users. Sequential fronthaul topologies in CFmMIMO, such as the daisy chain and multi-branch tree topology, have gained considerable attention recently. In such a processing architecture, each AP must store its received signal vector in the memory until it receives the relevant information from the previous AP in the sequence to refine the estimate of the users' signal vector in the uplink. In this paper, we adopt vector-wise and element-wise compression on the raw or pre-processed received signal vectors to store them in the memory. We investigate the impact of the limited memory capacity in the APs on the optimal number of APs. We show that with no memory constraint, having single-antenna APs is optimal, especially as the number of users grows. However, a limited memory at the APs restricts the depth of the sequential processing pipeline. Furthermore, we investigate the relation between the memory capacity at the APs and the rate of the fronthaul link.
Topology-Independent GEVD-Based Distributed Adaptive Node-Specific Signal Estimation in Ad-Hoc Wireless Acoustic Sensor Networks
Jul 19, 2024A low-rank approximation-based version of the topology-independent distributed adaptive node-specific signal estimation (TI-DANSE) algorithm is introduced, using a generalized eigenvalue decomposition (GEVD) for application in ad-hoc wireless acoustic sensor networks. This TI-GEVD-DANSE algorithm as well as the original TI-DANSE algorithm exhibit a non-strict convergence, which can lead to numerical instability over time, particularly in scenarios where the estimation of accurate spatial covariance matrices is challenging. An adaptive filter coefficient normalization strategy is proposed to mitigate this issue and enable the stable performance of TI-(GEVD-)DANSE. The method is validated in numerical simulations including dynamic acoustic scenarios, demonstrating the importance of the additional normalization.
Cascaded noise reduction and acoustic echo cancellation based on an extended noise reduction
Jun 13, 2024In many speech recording applications, the recorded desired speech is corrupted by both noise and acoustic echo, such that combined noise reduction (NR) and acoustic echo cancellation (AEC) is called for. A common cascaded design corresponds to NR filters preceding AEC filters. These NR filters aim at reducing the near-end room noise (and possibly partially the echo) and operate on the microphones only, consequently requiring the AEC filters to model both the echo paths and the NR filters. In this paper, however, we propose a design with extended NR (NRext) filters preceding AEC filters under the assumption of the echo paths being additive maps, thus preserving the addition operation. Here, the NRext filters aim at reducing both the near-end room noise and the far-end room noise component in the echo, and operate on both the microphones and loudspeakers. We show that the succeeding AEC filters remarkably become independent of the NRext filters, such that the AEC filters are only required to model the echo paths, improving the AEC performance. Further, the degrees of freedom in the NRext filters scale with the number of loudspeakers, which is not the case for the NR filters, resulting in an improved NR performance.