 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Steered Response Power Method for Sound Source Localization With Generic Acoustic Models
Sep 19, 2025The steered response power (SRP) method is one of the most popular approaches for acoustic source localization with microphone arrays. It is often based on simplifying acoustic assumptions, such as an omnidirectional sound source in the far field of the microphone array(s), free field propagation, and spatially uncorrelated noise. In reality, however, there are many acoustic scenarios where such assumptions are violated. This paper proposes a generalization of the conventional SRP method that allows to apply generic acoustic models for localization with arbitrary microphone constellations. These models may consider, for instance, level differences in distributed microphones, the directivity of sources and receivers, or acoustic shadowing effects. Moreover, also measured acoustic transfer functions may be applied as acoustic model. We show that the delay-and-sum beamforming of the conventional SRP is not optimal for localization with generic acoustic models. To this end, we propose a generalized SRP beamforming criterion that considers generic acoustic models and spatially correlated noise, and derive an optimal SRP beamformer. Furthermore, we propose and analyze appropriate frequency weightings. Unlike the conventional SRP, the proposed method can jointly exploit observed level and time differences between the microphone signals to infer the source location. Realistic simulations of three different microphone setups with speech under various noise conditions indicate that the proposed method can significantly reduce the mean localization error compared to the conventional SRP and, in particular, a reduction of more than 60% can be archived in noisy conditions.
Auralization based on multi-perspective ambisonic room impulse responses
Dec 06, 2023Most often, virtual acoustic rendering employs real-time updated room acoustic simulations to accomplish auralization for a variable listener perspective. As an alternative, we propose and test a technique to interpolate room impulse responses, specifically Ambisonic room impulse responses (ARIRs) available at a grid of spatially distributed receiver perspectives, measured or simulated in a desired acoustic environment. In particular, we extrapolate a triplet of neighboring ARIRs to the variable listener perspective, preceding their linear interpolation. The extrapolation is achieved by decomposing each ARIR into localized sound events and re-assigning their direction, time, and level to what could be observed at the listener perspective, with as much temporal, directional, and perspective context as possible. We propose to undertake this decomposition in two levels: Peaks in the early ARIRs are decomposed into jointly localized sound events, based on time differences of arrival observed in either an ARIR triplet, or all ARIRs observing the direct sound. Sound events that could not be jointly localized are treated as residuals whose less precise localization utilizes direction-of-arrival detection and the estimated time of arrival. For the interpolated rendering, suitable parameter settings are found by evaluating the proposed method in a listening experiment, using both measured and simulated ARIR data sets, under static and time-varying conditions.
* 18 pages, published in Acta Acustica (Open Access), datasets are available via https://paperswithcode.com/dataset/cube-b-format-ambisonic-rir-dataset and https://paperswithcode.com/dataset/variable-perspective-arir-rendering-listening
Head Orientation Estimation with Distributed Microphones Using Speech Radiation Patterns
Dec 04, 2023



Determining the head orientation of a talker is not only beneficial for various speech signal processing applications, such as source localization or speech enhancement, but also facilitates intuitive voice control and interaction with smart environments or modern car assistants. Most approaches for head orientation estimation are based on visual cues. However, this requires camera systems which often are not available. We present an approach which purely uses audio signals captured with only a few distributed microphones around the talker. Specifically, we propose a novel method that directly incorporates measured or modeled speech radiation patterns to infer the talker's orientation during active speech periods based on a cosine similarity measure. Moreover, an automatic gain adjustment technique is proposed for uncalibrated, irregular microphone setups, such as ad-hoc sensor networks. In experiments with signals recorded in both anechoic and reverberant environments, the proposed method outperforms state-of-the-art approaches, using either measured or modeled speech radiation patterns.
The PerspectiveLiberator -- an upmixing 6DoF rendering plugin for single-perspective Ambisonic room impulse responses
Oct 10, 2022
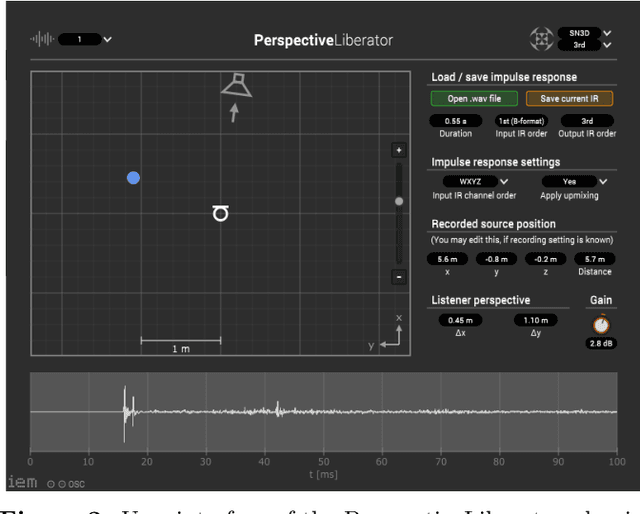
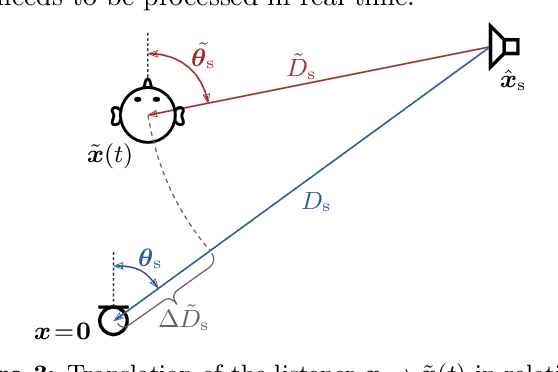
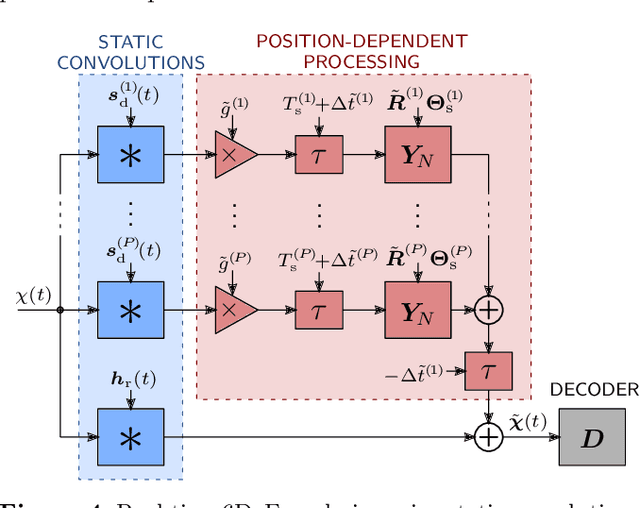
Nowadays, virtual reality interfaces allow the user to change perspectives in six degrees of freedom (6DoF) virtually, and consistently with the visual part, the acoustic perspective needs to be updated interactively. Single-perspective rendering with dynamic head rotation already works quite reliably with upmixed first-order Ambisonic room impulse responses (ASDM, SIRR, etc.). This contribution presents a plugin to free the virtual perspective from the measured one by real-time perspective extrapolation: The PerspectiveLiberator. The plugin permits selecting between two different algorithms for directional resolution enhancement (ASDM, 4DE). And for its main task of convolution-based 6DoF rendering, the plugin detects and localizes prominent directional sound events in the early Ambisonic room impulse response and re-encodes them with direction, time of arrival, and level adapted to the variable perspective of the virtual listener. The diffuse residual is enhanced in directional resolution but remains unaffected by translatory movement to preserve as much of the original room impression as possible.
* 4 pages, submitted to conference: DAGA 2021, Vienna, Austria, 2021
Model-based estimation of in-car-communication feedback applied to speech zone detection
Oct 07, 2022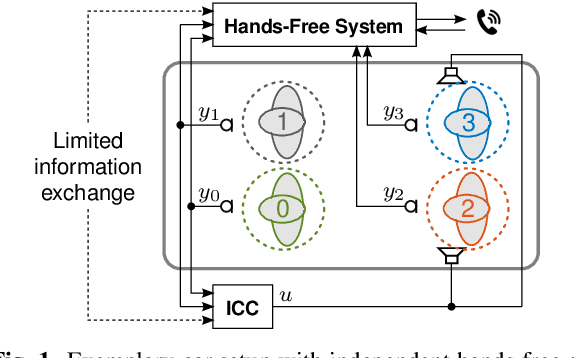


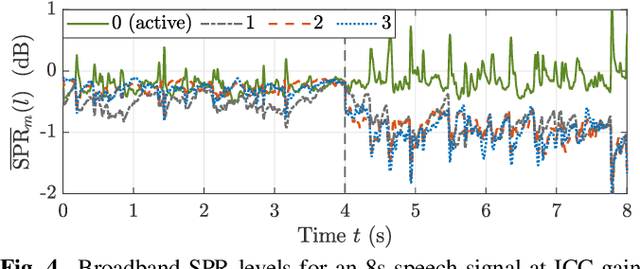
Modern cars provide versatile tools to enhance speech communication. While an in-car communication (ICC) system aims at enhancing communication between the passengers by playing back desired speech via loudspeakers in the car, these loudspeaker signals may disturb a speech enhancement system required for hands-free telephony and automatic speech recognition. In this paper, we focus on speech zone detection, i.e. detecting which passenger in the car is speaking, which is a crucial component of the speech enhancement system. We propose a model-based feedback estimation method to improve robustness of speech zone detection against ICC feedback. Specifically, since the zone detection system typically does not have access to the ICC loudspeaker signals, the proposed method estimates the feedback signal from the observed microphone signals based on a free-field propagation model between the loudspeakers and the microphones as well as the ICC gain. We propose an efficient recursive implementation in the short-time Fourier transform domain using convolutive transfer functions. A realistic simulation study indicates that the proposed method allows to increase the ICC gain by about 6dB while still achieving robust speech zone detection results.