 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFUTON: Fourier Tensor Network for Implicit Neural Representations
Feb 13, 2026Implicit neural representations (INRs) have emerged as powerful tools for encoding signals, yet dominant MLP-based designs often suffer from slow convergence, overfitting to noise, and poor extrapolation. We introduce FUTON (Fourier Tensor Network), which models signals as generalized Fourier series whose coefficients are parameterized by a low-rank tensor decomposition. FUTON implicitly expresses signals as weighted combinations of orthonormal, separable basis functions, combining complementary inductive biases: Fourier bases capture smoothness and periodicity, while the low-rank parameterization enforces low-dimensional spectral structure. We provide theoretical guarantees through a universal approximation theorem and derive an inference algorithm with complexity linear in the spectral resolution and the input dimension. On image and volume representation, FUTON consistently outperforms state-of-the-art MLP-based INRs while training 2--5$\times$ faster. On inverse problems such as image denoising and super-resolution, FUTON generalizes better and converges faster.
Deconver: A Deconvolutional Network for Medical Image Segmentation
Apr 01, 2025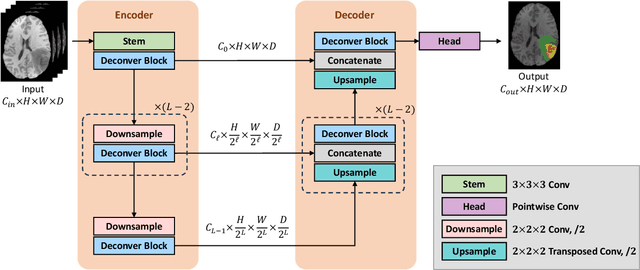
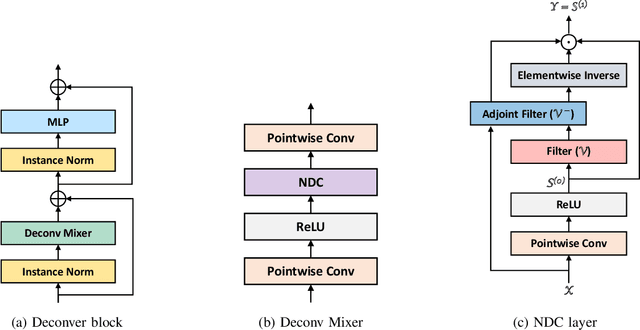
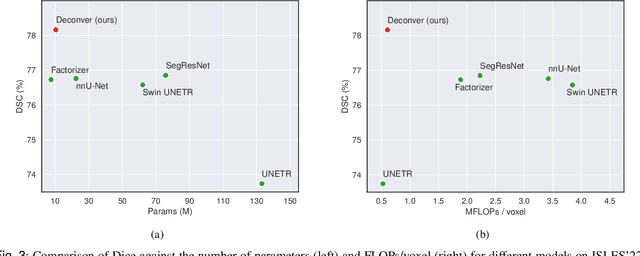
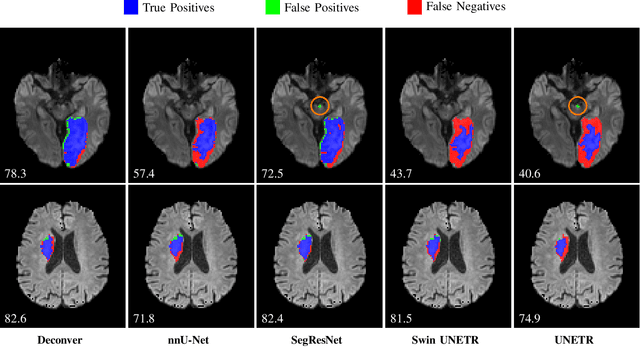
While convolutional neural networks (CNNs) and vision transformers (ViTs) have advanced medical image segmentation, they face inherent limitations such as local receptive fields in CNNs and high computational complexity in ViTs. This paper introduces Deconver, a novel network that integrates traditional deconvolution techniques from image restoration as a core learnable component within a U-shaped architecture. Deconver replaces computationally expensive attention mechanisms with efficient nonnegative deconvolution (NDC) operations, enabling the restoration of high-frequency details while suppressing artifacts. Key innovations include a backpropagation-friendly NDC layer based on a provably monotonic update rule and a parameter-efficient design. Evaluated across four datasets (ISLES'22, BraTS'23, GlaS, FIVES) covering both 2D and 3D segmentation tasks, Deconver achieves state-of-the-art performance in Dice scores and Hausdorff distance while reducing computational costs (FLOPs) by up to 90% compared to leading baselines. By bridging traditional image restoration with deep learning, this work offers a practical solution for high-precision segmentation in resource-constrained clinical workflows. The project is available at https://github.com/pashtari/deconver.
OsmLocator: locating overlapping scatter marks with a non-training generative perspective
Dec 22, 2023Automated mark localization in scatter images, greatly helpful for discovering knowledge and understanding enormous document images and reasoning in visual question answering AI systems, is a highly challenging problem because of the ubiquity of overlapping marks. Locating overlapping marks faces many difficulties such as no texture, less contextual information, hallow shape and tiny size. Here, we formulate it as a combinatorial optimization problem on clustering-based re-visualization from a non-training generative perspective, to locate scatter marks by finding the status of multi-variables when an objective function reaches a minimum. The objective function is constructed on difference between binarized scatter images and corresponding generated re-visualization based on their clustering. Fundamentally, re-visualization tries to generate a new scatter graph only taking a rasterized scatter image as an input, and clustering is employed to provide the information for such re-visualization. This method could stably locate severely-overlapping, variable-size and variable-shape marks in scatter images without dependence of any training dataset or reference. Meanwhile, we propose an adaptive variant of simulated annealing which can works on various connected regions. In addition, we especially built a dataset named SML2023 containing hundreds of scatter images with different markers and various levels of overlapping severity, and tested the proposed method and compared it to existing methods. The results show that it can accurately locate most marks in scatter images with different overlapping severity and marker types, with about 0.3 absolute increase on an assignment-cost-based metric in comparison with state-of-the-art methods. This work is of value to data mining on massive web pages and literatures, and shedding new light on image measurement such as bubble counting.
Self-Supervised Learning as a Means To Reduce the Need for Labeled Data in Medical Image Analysis
Jun 01, 2022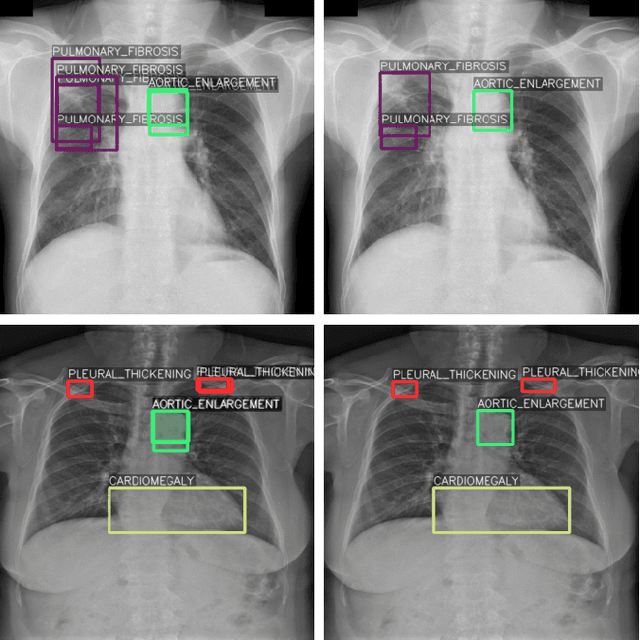
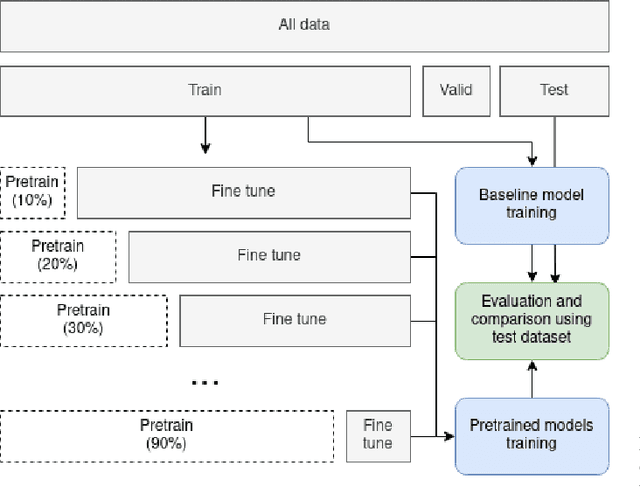
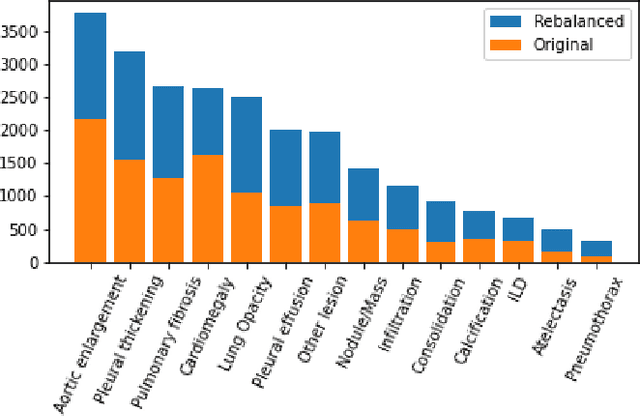
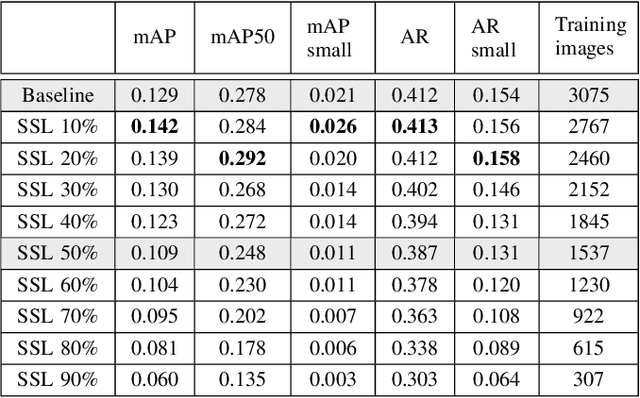
One of the largest problems in medical image processing is the lack of annotated data. Labeling medical images often requires highly trained experts and can be a time-consuming process. In this paper, we evaluate a method of reducing the need for labeled data in medical image object detection by using self-supervised neural network pretraining. We use a dataset of chest X-ray images with bounding box labels for 13 different classes of anomalies. The networks are pretrained on a percentage of the dataset without labels and then fine-tuned on the rest of the dataset. We show that it is possible to achieve similar performance to a fully supervised model in terms of mean average precision and accuracy with only 60\% of the labeled data. We also show that it is possible to increase the maximum performance of a fully-supervised model by adding a self-supervised pretraining step, and this effect can be observed with even a small amount of unlabeled data for pretraining.
Hierarchical Variational Autoencoder for Visual Counterfactuals
Feb 01, 2021



Conditional Variational Auto Encoders (VAE) are gathering significant attention as an Explainable Artificial Intelligence (XAI) tool. The codes in the latent space provide a theoretically sound way to produce counterfactuals, i.e. alterations resulting from an intervention on a targeted semantic feature. To be applied on real images more complex models are needed, such as Hierarchical CVAE. This comes with a challenge as the naive conditioning is no longer effective. In this paper we show how relaxing the effect of the posterior leads to successful counterfactuals and we introduce VAEX an Hierarchical VAE designed for this approach that can visually audit a classifier in applications.
Hierarchical Metric Learning for Optical Remote Sensing Scene Categorization
Aug 01, 2018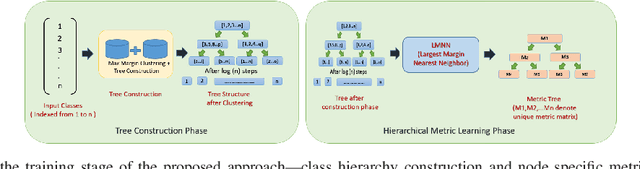
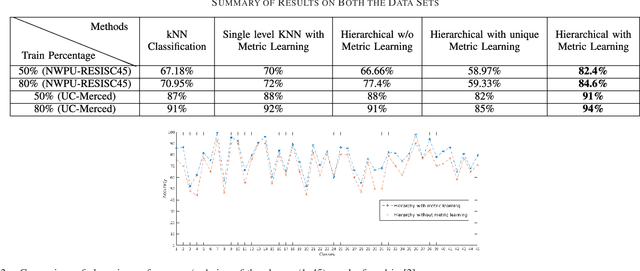
We address the problem of scene classification from optical remote sensing (RS) images based on the paradigm of hierarchical metric learning. Ideally, supervised metric learning strategies learn a projection from a set of training data points so as to minimize intra-class variance while maximizing inter-class separability to the class label space. However, standard metric learning techniques do not incorporate the class interaction information in learning the transformation matrix, which is often considered to be a bottleneck while dealing with fine-grained visual categories. As a remedy, we propose to organize the classes in a hierarchical fashion by exploring their visual similarities and subsequently learn separate distance metric transformations for the classes present at the non-leaf nodes of the tree. We employ an iterative max-margin clustering strategy to obtain the hierarchical organization of the classes. Experiment results obtained on the large-scale NWPU-RESISC45 and the popular UC-Merced datasets demonstrate the efficacy of the proposed hierarchical metric learning based RS scene recognition strategy in comparison to the standard approaches.
Pattern Encoding on the Poincare Sphere
Oct 01, 2014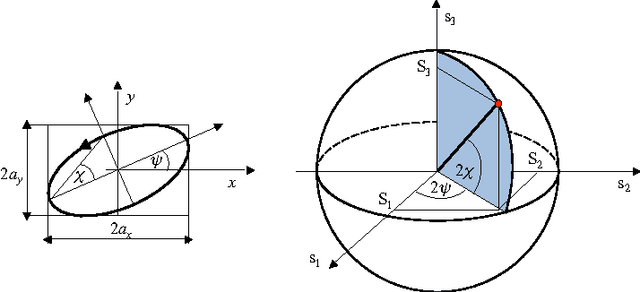
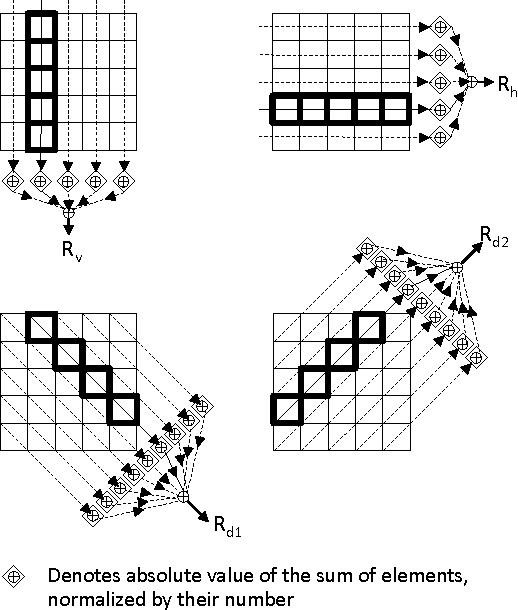
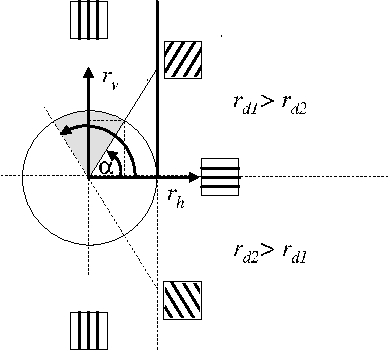
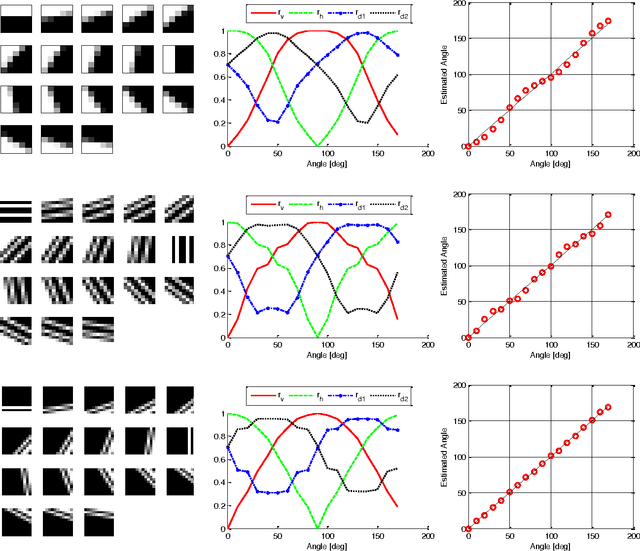
This paper presents a convenient graphical tool for encoding visual patterns (such as image patches and image atoms) as point constellations in a space spanned by perceptual features and with a clear geometrical interpretation. General theory and a practical pattern encoding scheme are presented, inspired by encoding polarization states of a light wave on the Poincare sphere. This new pattern encoding scheme can be useful for many applications in image processing and computer vision. Here, three possible applications are illustrated, in clustering perceptually similar patterns, visualizing properties of learned dictionaries of image atoms and generating new dictionaries of image atoms from spherical codes.