 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOsmLocator: locating overlapping scatter marks with a non-training generative perspective
Dec 22, 2023Automated mark localization in scatter images, greatly helpful for discovering knowledge and understanding enormous document images and reasoning in visual question answering AI systems, is a highly challenging problem because of the ubiquity of overlapping marks. Locating overlapping marks faces many difficulties such as no texture, less contextual information, hallow shape and tiny size. Here, we formulate it as a combinatorial optimization problem on clustering-based re-visualization from a non-training generative perspective, to locate scatter marks by finding the status of multi-variables when an objective function reaches a minimum. The objective function is constructed on difference between binarized scatter images and corresponding generated re-visualization based on their clustering. Fundamentally, re-visualization tries to generate a new scatter graph only taking a rasterized scatter image as an input, and clustering is employed to provide the information for such re-visualization. This method could stably locate severely-overlapping, variable-size and variable-shape marks in scatter images without dependence of any training dataset or reference. Meanwhile, we propose an adaptive variant of simulated annealing which can works on various connected regions. In addition, we especially built a dataset named SML2023 containing hundreds of scatter images with different markers and various levels of overlapping severity, and tested the proposed method and compared it to existing methods. The results show that it can accurately locate most marks in scatter images with different overlapping severity and marker types, with about 0.3 absolute increase on an assignment-cost-based metric in comparison with state-of-the-art methods. This work is of value to data mining on massive web pages and literatures, and shedding new light on image measurement such as bubble counting.
Tracking Small and Fast Moving Objects: A Benchmark
Sep 09, 2022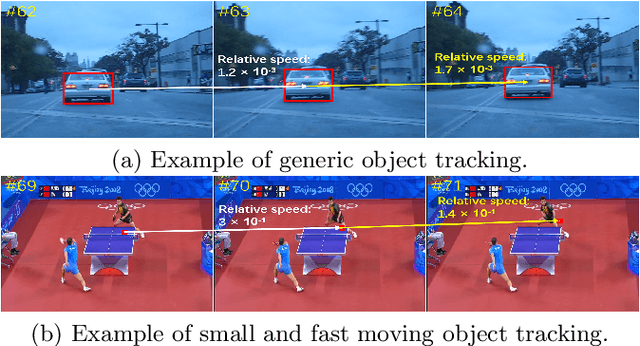
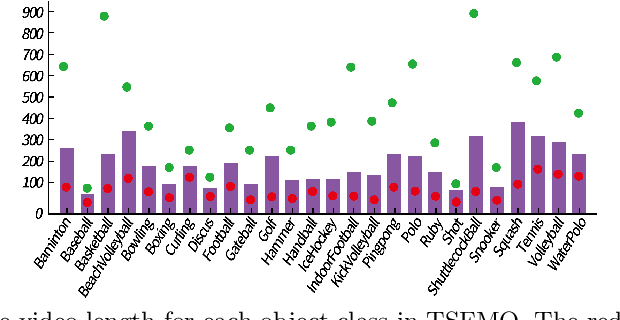


With more and more large-scale datasets available for training, visual tracking has made great progress in recent years. However, current research in the field mainly focuses on tracking generic objects. In this paper, we present TSFMO, a benchmark for \textbf{T}racking \textbf{S}mall and \textbf{F}ast \textbf{M}oving \textbf{O}bjects. This benchmark aims to encourage research in developing novel and accurate methods for this challenging task particularly. TSFMO consists of 250 sequences with about 50k frames in total. Each frame in these sequences is carefully and manually annotated with a bounding box. To the best of our knowledge, TSFMO is the first benchmark dedicated to tracking small and fast moving objects, especially connected to sports. To understand how existing methods perform and to provide comparison for future research on TSFMO, we extensively evaluate 20 state-of-the-art trackers on the benchmark. The evaluation results exhibit that more effort are required to improve tracking small and fast moving objects. Moreover, to encourage future research, we proposed a novel tracker S-KeepTrack which surpasses all 20 evaluated approaches. By releasing TSFMO, we expect to facilitate future researches and applications of tracking small and fast moving objects. The TSFMO and evaluation results as well as S-KeepTrack are available at \url{https://github.com/CodeOfGithub/S-KeepTrack}.