 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-BERT: Leveraging Adapters and Prompt Tuning for Low-Resource Multi-Domain Adaptation
Paper and Code
Apr 02, 2024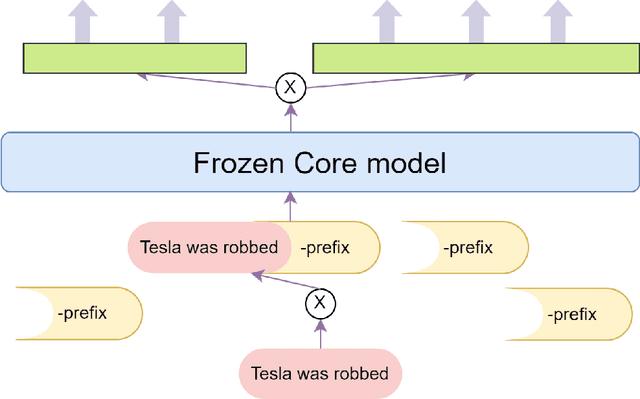



The rapid expansion of texts' volume and diversity presents formidable challenges in multi-domain settings. These challenges are also visible in the Persian name entity recognition (NER) settings. Traditional approaches, either employing a unified model for multiple domains or individual models for each domain, frequently pose significant limitations. Single models often struggle to capture the nuances of diverse domains, while utilizing multiple large models can lead to resource constraints, rendering the training of a model for each domain virtually impractical. Therefore, this paper introduces a novel approach composed of one core model with multiple sets of domain-specific parameters. We utilize techniques such as prompt tuning and adapters, combined with the incorporation of additional layers, to add parameters that we can train for the specific domains. This enables the model to perform comparably to individual models for each domain. Experimental results on different formal and informal datasets show that by employing these added parameters, the proposed model significantly surpasses existing practical models in performance. Remarkably, the proposed model requires only one instance for training and storage, yet achieves outstanding results across all domains, even surpassing the state-of-the-art in some. Moreover, we analyze each adaptation strategy, delineating its strengths, weaknesses, and optimal hyper-parameters for the Persian NER settings. Finally, we introduce a document-based domain detection pipeline tailored for scenarios with unknown text domains, enhancing the adaptability and practicality of this paper in real-world applications.