 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTARS: Self-supervised Tuning for 3D Action Recognition in Skeleton Sequences
Jul 15, 2024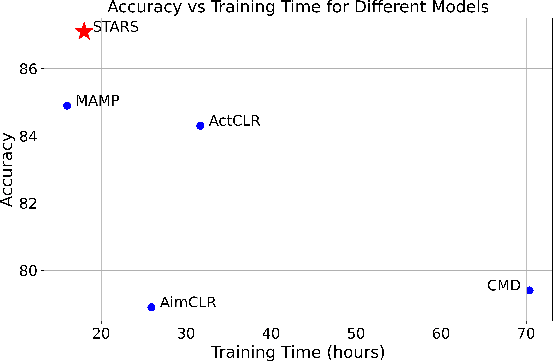
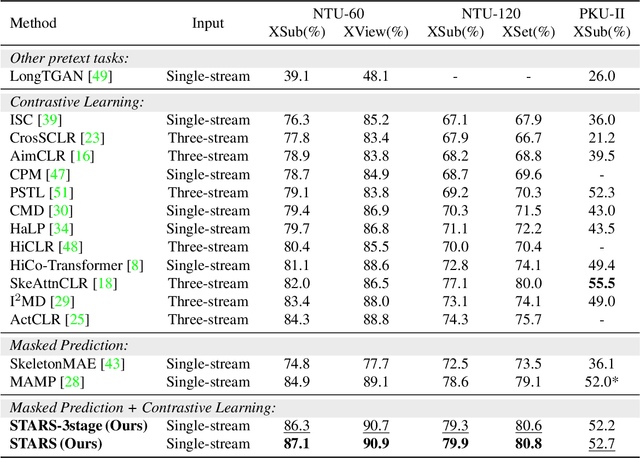
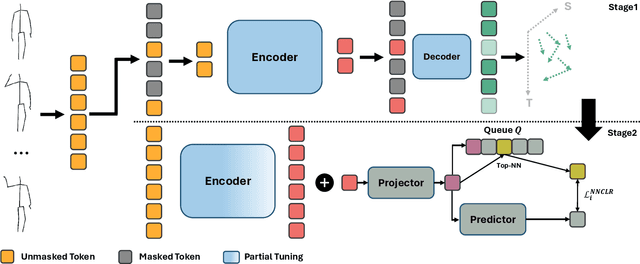
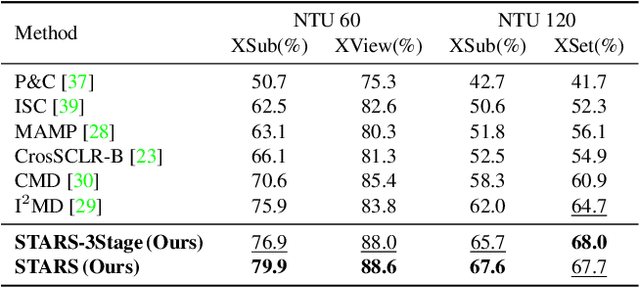
Self-supervised pretraining methods with masked prediction demonstrate remarkable within-dataset performance in skeleton-based action recognition. However, we show that, unlike contrastive learning approaches, they do not produce well-separated clusters. Additionally, these methods struggle with generalization in few-shot settings. To address these issues, we propose Self-supervised Tuning for 3D Action Recognition in Skeleton sequences (STARS). Specifically, STARS first uses a masked prediction stage using an encoder-decoder architecture. It then employs nearest-neighbor contrastive learning to partially tune the weights of the encoder, enhancing the formation of semantic clusters for different actions. By tuning the encoder for a few epochs, and without using hand-crafted data augmentations, STARS achieves state-of-the-art self-supervised results in various benchmarks, including NTU-60, NTU-120, and PKU-MMD. In addition, STARS exhibits significantly better results than masked prediction models in few-shot settings, where the model has not seen the actions throughout pretraining. Project page: https://soroushmehraban.github.io/stars/
Enhancing Landmark Detection in Cluttered Real-World Scenarios with Vision Transformers
Aug 25, 2023
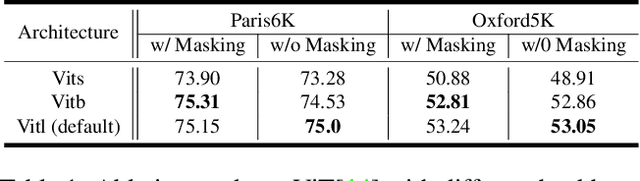
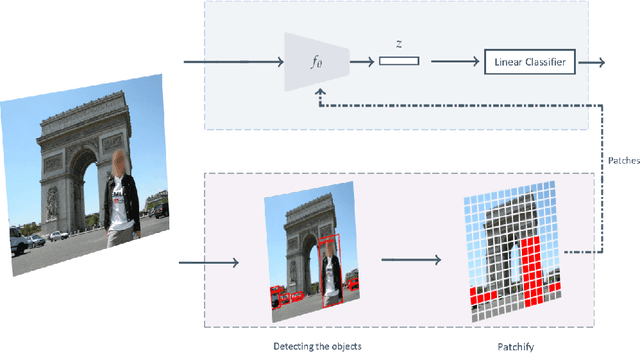

Visual place recognition tasks often encounter significant challenges in landmark detection due to the presence of irrelevant objects such as humans, cars, and trees, despite the remarkable progress achieved by previous models, especially in the context of transformers. To address this issue, we propose a novel method that effectively leverages the strengths of vision transformers. By employing a meticulous selection process, our approach identifies and isolates specific patches within the image that correspond to occluding objects. To evaluate the efficacy of our method, we created augmented datasets and conducted comprehensive testing. The results demonstrate the superior accuracy achieved by our proposed approach. This research contributes to the advancement of landmark detection in visual place recognition and shows the potential of leveraging vision transformers to overcome challenges posed by cluttered real-world scenarios.
Mitigating Bias: Enhancing Image Classification by Improving Model Explanations
Jul 10, 2023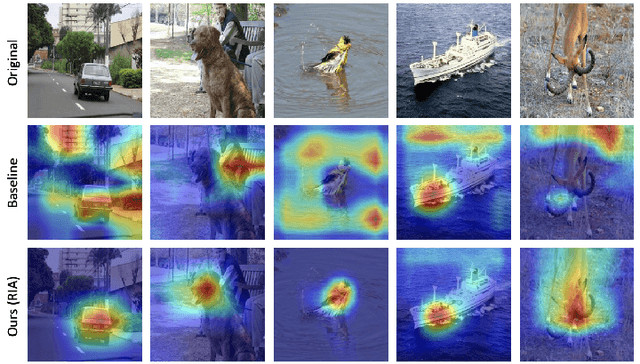
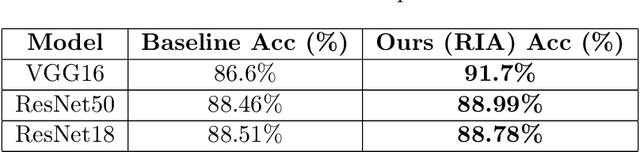
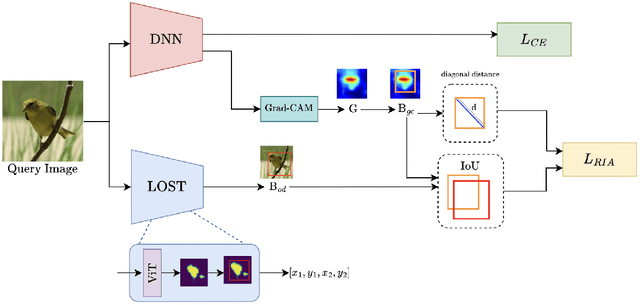

Deep learning models have demonstrated remarkable capabilities in learning complex patterns and concepts from training data. However, recent findings indicate that these models tend to rely heavily on simple and easily discernible features present in the background of images rather than the main concepts or objects they are intended to classify. This phenomenon poses a challenge to image classifiers as the crucial elements of interest in images may be overshadowed. In this paper, we propose a novel approach to address this issue and improve the learning of main concepts by image classifiers. Our central idea revolves around concurrently guiding the model's attention toward the foreground during the classification task. By emphasizing the foreground, which encapsulates the primary objects of interest, we aim to shift the focus of the model away from the dominant influence of the background. To accomplish this, we introduce a mechanism that encourages the model to allocate sufficient attention to the foreground. We investigate various strategies, including modifying the loss function or incorporating additional architectural components, to enable the classifier to effectively capture the primary concept within an image. Additionally, we explore the impact of different foreground attention mechanisms on model performance and provide insights into their effectiveness. Through extensive experimentation on benchmark datasets, we demonstrate the efficacy of our proposed approach in improving the classification accuracy of image classifiers. Our findings highlight the importance of foreground attention in enhancing model understanding and representation of the main concepts within images. The results of this study contribute to advancing the field of image classification and provide valuable insights for developing more robust and accurate deep-learning models.