 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrand Visibility in Packaging: A Deep Learning Approach for Logo Detection, Saliency-Map Prediction, and Logo Placement Analysis
Mar 04, 2024



In the highly competitive area of product marketing, the visibility of brand logos on packaging plays a crucial role in shaping consumer perception, directly influencing the success of the product. This paper introduces a comprehensive framework to measure the brand logo's attention on a packaging design. The proposed method consists of three steps. The first step leverages YOLOv8 for precise logo detection across prominent datasets, FoodLogoDet-1500 and LogoDet-3K. The second step involves modeling the user's visual attention with a novel saliency prediction model tailored for the packaging context. The proposed saliency model combines the visual elements with text maps employing a transformers-based architecture to predict user attention maps. In the third step, by integrating logo detection with a saliency map generation, the framework provides a comprehensive brand attention score. The effectiveness of the proposed method is assessed module by module, ensuring a thorough evaluation of each component. Comparing logo detection and saliency map prediction with state-of-the-art models shows the superiority of the proposed methods. To investigate the robustness of the proposed brand attention score, we collected a unique dataset to examine previous psychophysical hypotheses related to brand visibility. the results show that the brand attention score is in line with all previous studies. Also, we introduced seven new hypotheses to check the impact of position, orientation, presence of person, and other visual elements on brand attention. This research marks a significant stride in the intersection of cognitive psychology, computer vision, and marketing, paving the way for advanced, consumer-centric packaging designs.
A Dataset Generation Framework for profiling Disassembly attacks using Side-Channel Leakages and Deep Neural Networks
Aug 12, 2022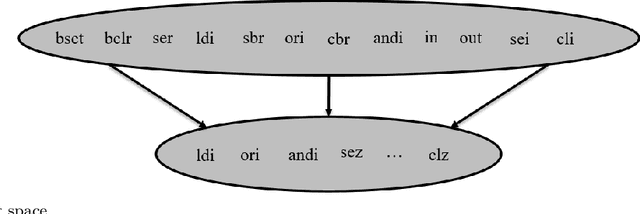
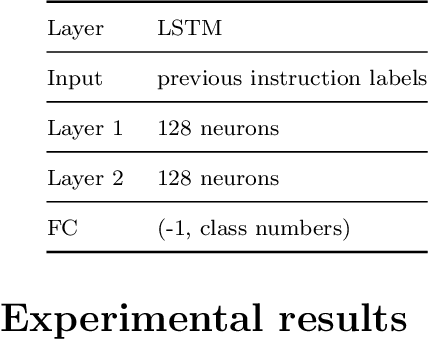
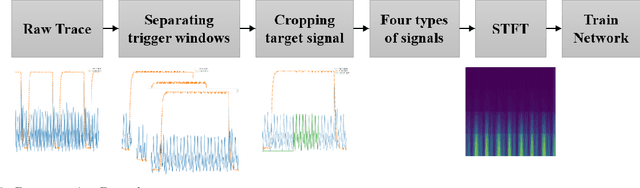
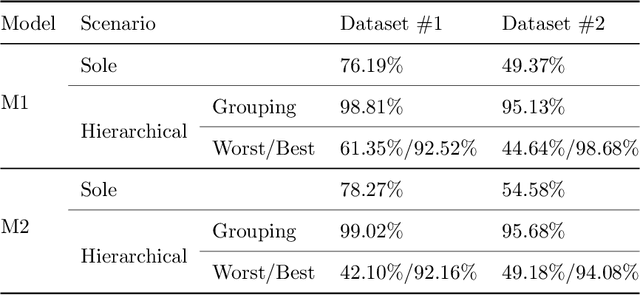
Various studies among side-channel attacks have tried to extract information through leakages from electronic devices to reach the instruction flow of some appliances. However, previous methods highly depend on the resolution of traced data. Obtaining low-noise traces is not always feasible in real attack scenarios. This study proposes two deep models to extract low and high-level features from side-channel traces and classify them to related instructions. We aim to evaluate the accuracy of a side-channel attack on low-resolution data with a more robust feature extractor thanks to neural networks. As inves-tigated, instruction flow in real programs is predictable and follows specific distributions. This leads to proposing a LSTM model to estimate these distributions, which could expedite the reverse engineering process and also raise the accuracy. The proposed model for leakage classification reaches 54.58% accuracy on average and outperforms other existing methods on our datasets. Also, LSTM model reaches 94.39% accuracy for instruction prediction on standard implementation of cryptographic algorithms.
Soccer Event Detection Using Deep Learning
Feb 08, 2021
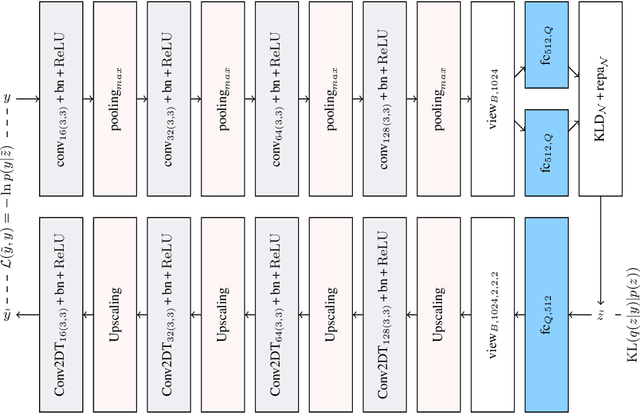
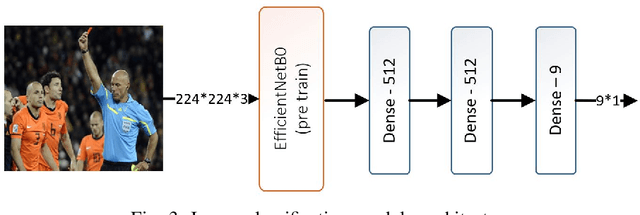
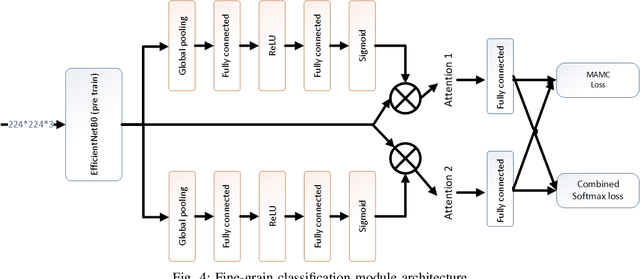
Event detection is an important step in extracting knowledge from the video. In this paper, we propose a deep learning approach to detect events in a soccer match emphasizing the distinction between images of red and yellow cards and the correct detection of the images of selected events from other images. This method includes the following three modules: i) the variational autoencoder (VAE) module to differentiate between soccer images and others image, ii) the image classification module to classify the images of events, and iii) the fine-grain image classification module to classify the images of red and yellow cards. Additionally, a new dataset was introduced for soccer images classification that is employed to train the networks mentioned in the paper. In the final section, 10 UEFA Champions League matches are used to evaluate the networks' performance and precision in detecting the events. The experiments demonstrate that the proposed method achieves better performance than state-of-the-art methods.
EfficientNet-Absolute Zero for Continuous Speech Keyword Spotting
Dec 31, 2020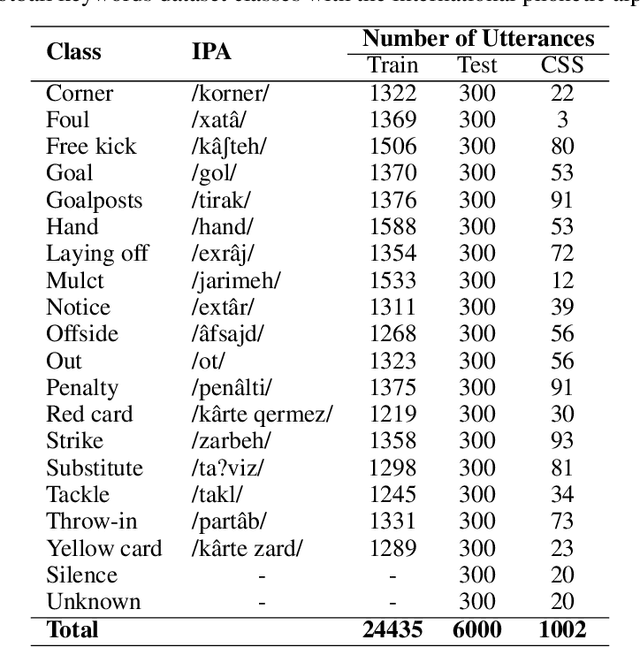
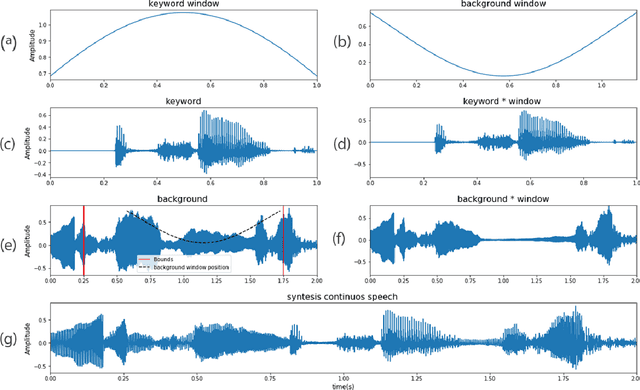
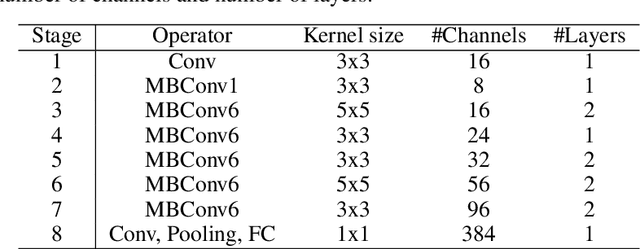
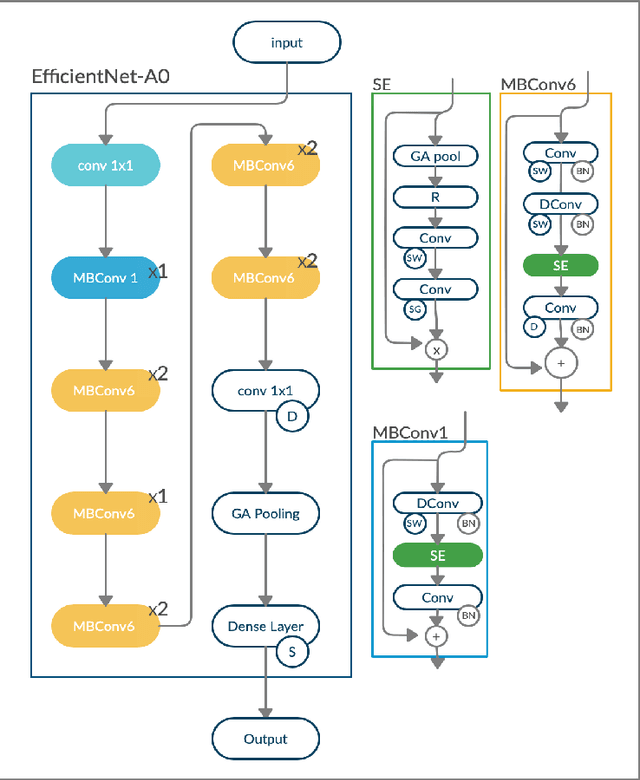
Keyword spotting is a process of finding some specific words or phrases in recorded speeches by computers. Deep neural network algorithms, as a powerful engine, can handle this problem if they are trained over an appropriate dataset. To this end, the football keyword dataset (FKD), as a new keyword spotting dataset in Persian, is collected with crowdsourcing. This dataset contains nearly 31000 samples in 18 classes. The continuous speech synthesis method proposed to made FKD usable in the practical application which works with continuous speeches. Besides, we proposed a lightweight architecture called EfficientNet-A0 (absolute zero) by applying the compound scaling method on EfficientNet-B0 for keyword spotting task. Finally, the proposed architecture is evaluated with various models. It is realized that EfficientNet-A0 and Resnet models outperform other models on this dataset.
Face Manifold: Manifold Learning for Synthetic Face Generation
Oct 04, 2019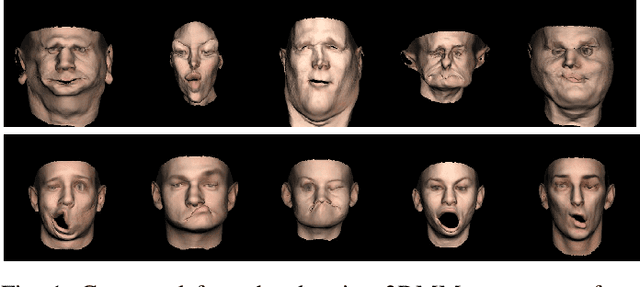
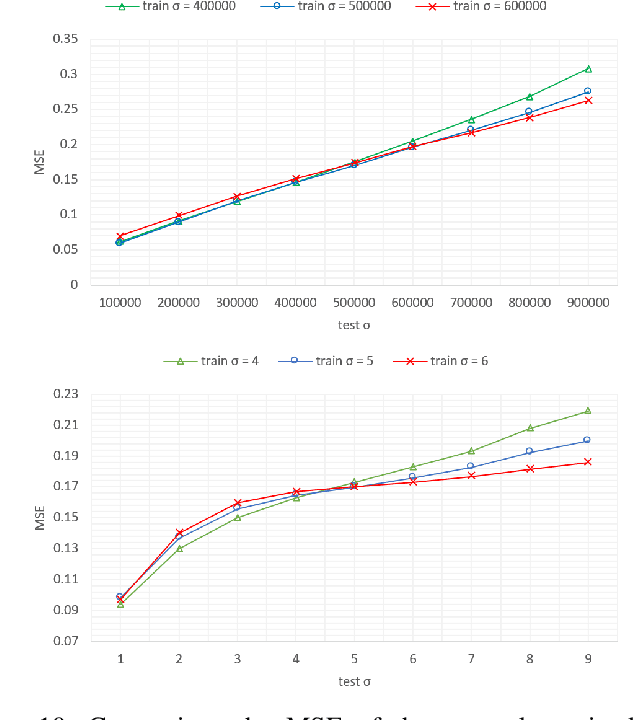

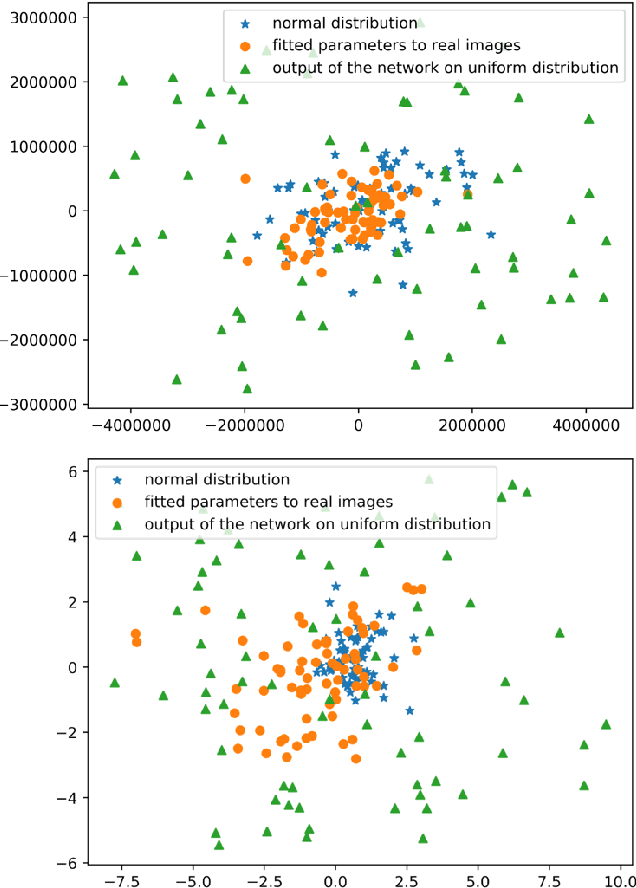
Face is one of the most important things for communication with the world around us. It also forms our identity and expressions. Estimating the face structure is a fundamental task in computer vision with applications in different areas such as face recognition and medical surgeries. Recently, deep learning techniques achieved significant results for 3D face reconstruction from flat images. The main challenge of such techniques is a vital need for large 3D face datasets. Usually, this challenge is handled by synthetic face generation. However, synthetic datasets suffer from the existence of non-possible faces. Here, we propose a face manifold learning method for synthetic diverse face dataset generation. First, the face structure is divided into the shape and expression groups. Then, a fully convolutional autoencoder network is exploited to deal with the non-possible faces, and, simultaneously, preserving the dataset diversity. Simulation results show that the proposed method is capable of denoising highly corrupted faces. The diversity of the generated dataset is evaluated qualitatively and quantitatively and compared to the existing methods. Experiments show that our manifold learning method outperforms the state of the art methods significantly.