 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Malicious UAV Detection Using Autoencoder-TSMamba Integration
May 14, 2025Malicious Unmanned Aerial Vehicles (UAVs) present a significant threat to next-generation networks (NGNs), posing risks such as unauthorized surveillance, data theft, and the delivery of hazardous materials. This paper proposes an integrated (AE)-classifier system to detect malicious UAVs. The proposed AE, based on a 4-layer Tri-orientated Spatial Mamba (TSMamba) architecture, effectively captures complex spatial relationships crucial for identifying malicious UAV activities. The first phase involves generating residual values through the AE, which are subsequently processed by a ResNet-based classifier. This classifier leverages the residual values to achieve lower complexity and higher accuracy. Our experiments demonstrate significant improvements in both binary and multi-class classification scenarios, achieving up to 99.8 % recall compared to 96.7 % in the benchmark. Additionally, our method reduces computational complexity, making it more suitable for large-scale deployment. These results highlight the robustness and scalability of our approach, offering an effective solution for malicious UAV detection in NGN environments.
CNN Autoencoder Resizer: A Power-Efficient LoS/NLoS Detector in MIMO-enabled UAV Networks
May 26, 2024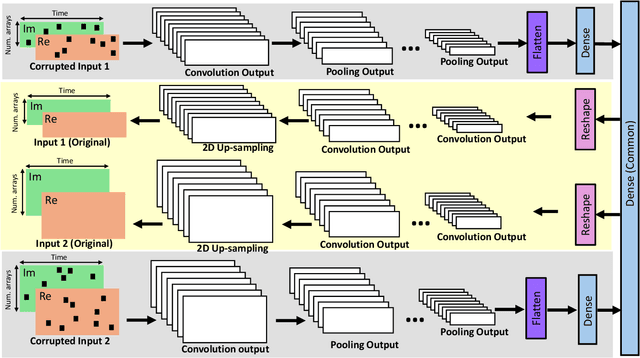

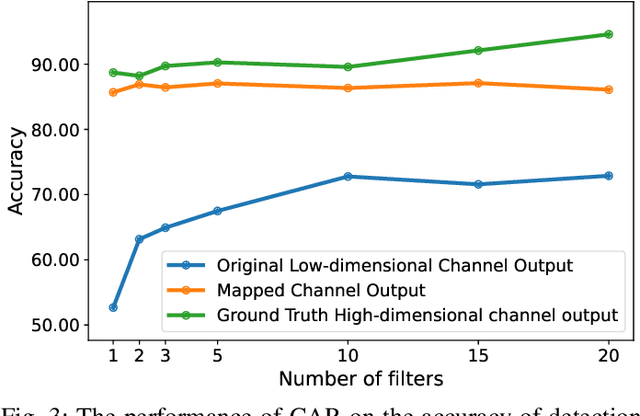
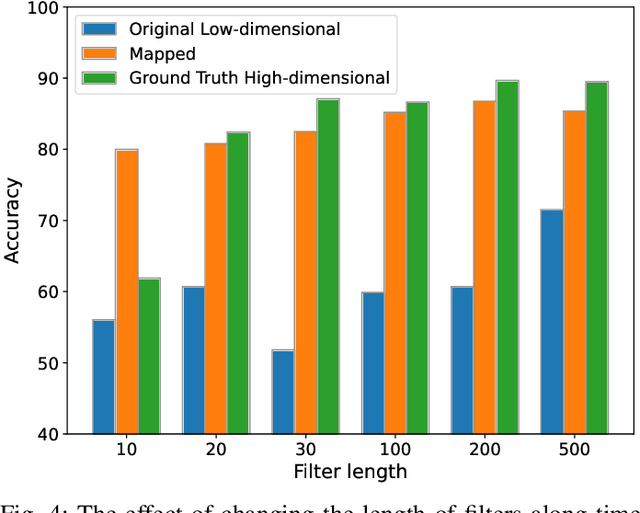
Optimizing the design, performance, and resource efficiency of wireless networks (WNs) necessitates the ability to discern Line of Sight (LoS) and Non-Line of Sight (NLoS) scenarios across diverse applications and environments. Unmanned Aerial Vehicles (UAVs) exhibit significant potential in this regard due to their rapid mobility, aerial capabilities, and payload characteristics. Particularly, UAVs can serve as vital non-terrestrial base stations (NTBS) in the event of terrestrial base station (TBS) failures or downtime. In this paper, we propose CNN autoencoder resizer (CAR) as a framework that improves the accuracy of LoS/NLoS detection without demanding extra power consumption. Our proposed method increases the mean accuracy of detecting LoS/NLoS signals from 66% to 86%, while maintaining consistent power consumption levels. In addition, the resolution provided by CAR shows that it can be employed as a preprocessing tool in other methods to enhance the quality of signals.
Brand Visibility in Packaging: A Deep Learning Approach for Logo Detection, Saliency-Map Prediction, and Logo Placement Analysis
Mar 04, 2024



In the highly competitive area of product marketing, the visibility of brand logos on packaging plays a crucial role in shaping consumer perception, directly influencing the success of the product. This paper introduces a comprehensive framework to measure the brand logo's attention on a packaging design. The proposed method consists of three steps. The first step leverages YOLOv8 for precise logo detection across prominent datasets, FoodLogoDet-1500 and LogoDet-3K. The second step involves modeling the user's visual attention with a novel saliency prediction model tailored for the packaging context. The proposed saliency model combines the visual elements with text maps employing a transformers-based architecture to predict user attention maps. In the third step, by integrating logo detection with a saliency map generation, the framework provides a comprehensive brand attention score. The effectiveness of the proposed method is assessed module by module, ensuring a thorough evaluation of each component. Comparing logo detection and saliency map prediction with state-of-the-art models shows the superiority of the proposed methods. To investigate the robustness of the proposed brand attention score, we collected a unique dataset to examine previous psychophysical hypotheses related to brand visibility. the results show that the brand attention score is in line with all previous studies. Also, we introduced seven new hypotheses to check the impact of position, orientation, presence of person, and other visual elements on brand attention. This research marks a significant stride in the intersection of cognitive psychology, computer vision, and marketing, paving the way for advanced, consumer-centric packaging designs.
Unsupervised Representations Improve Supervised Learning in Speech Emotion Recognition
Sep 22, 2023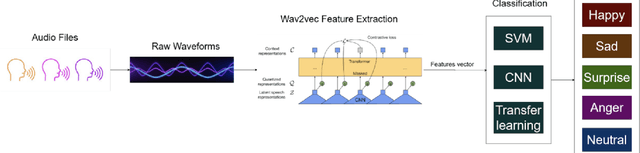



Speech Emotion Recognition (SER) plays a pivotal role in enhancing human-computer interaction by enabling a deeper understanding of emotional states across a wide range of applications, contributing to more empathetic and effective communication. This study proposes an innovative approach that integrates self-supervised feature extraction with supervised classification for emotion recognition from small audio segments. In the preprocessing step, to eliminate the need of crafting audio features, we employed a self-supervised feature extractor, based on the Wav2Vec model, to capture acoustic features from audio data. Then, the output featuremaps of the preprocessing step are fed to a custom designed Convolutional Neural Network (CNN)-based model to perform emotion classification. Utilizing the ShEMO dataset as our testing ground, the proposed method surpasses two baseline methods, i.e. support vector machine classifier and transfer learning of a pretrained CNN. comparing the propose method to the state-of-the-art methods in SER task indicates the superiority of the proposed method. Our findings underscore the pivotal role of deep unsupervised feature learning in elevating the landscape of SER, offering enhanced emotional comprehension in the realm of human-computer interactions.
Soccer Event Detection Using Deep Learning
Feb 08, 2021
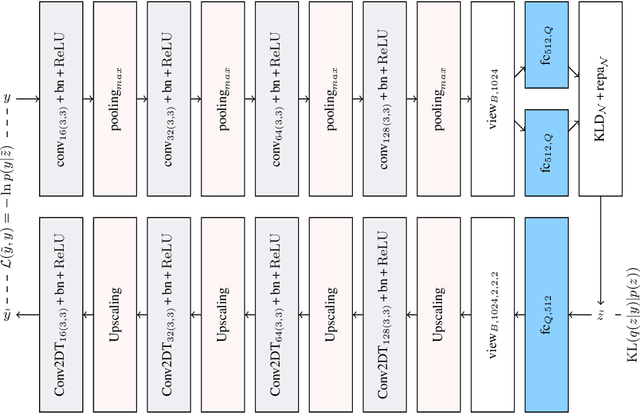
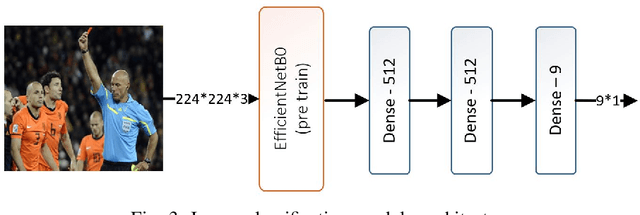
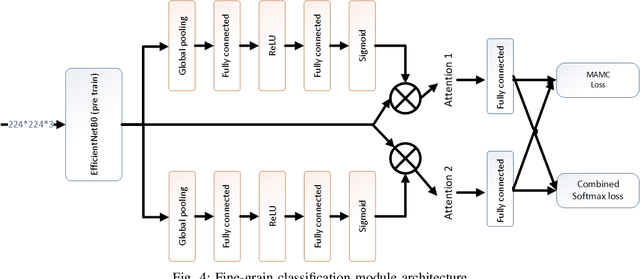
Event detection is an important step in extracting knowledge from the video. In this paper, we propose a deep learning approach to detect events in a soccer match emphasizing the distinction between images of red and yellow cards and the correct detection of the images of selected events from other images. This method includes the following three modules: i) the variational autoencoder (VAE) module to differentiate between soccer images and others image, ii) the image classification module to classify the images of events, and iii) the fine-grain image classification module to classify the images of red and yellow cards. Additionally, a new dataset was introduced for soccer images classification that is employed to train the networks mentioned in the paper. In the final section, 10 UEFA Champions League matches are used to evaluate the networks' performance and precision in detecting the events. The experiments demonstrate that the proposed method achieves better performance than state-of-the-art methods.
Face Manifold: Manifold Learning for Synthetic Face Generation
Oct 04, 2019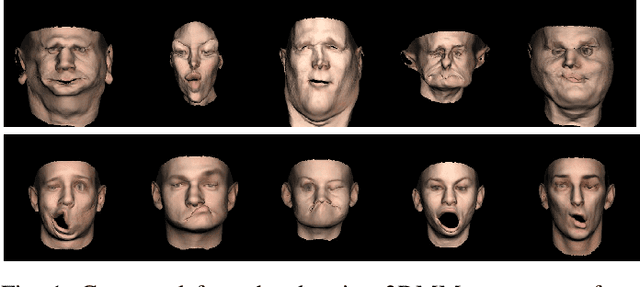
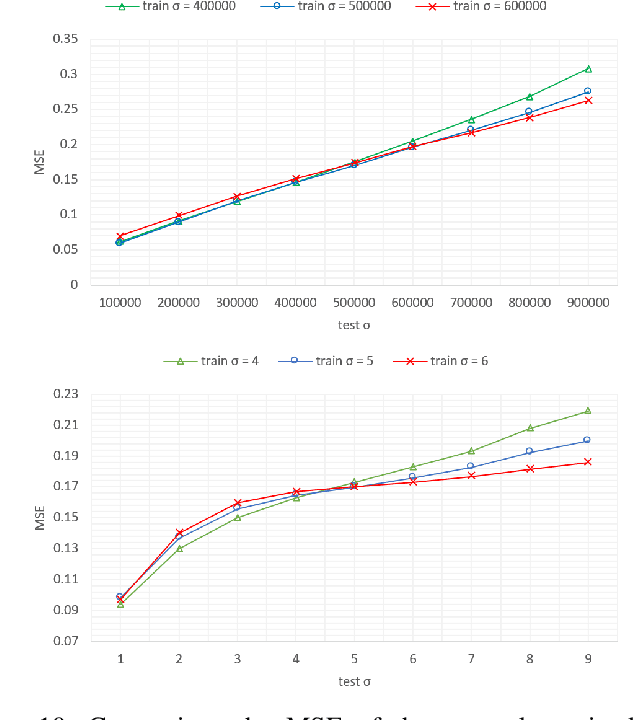

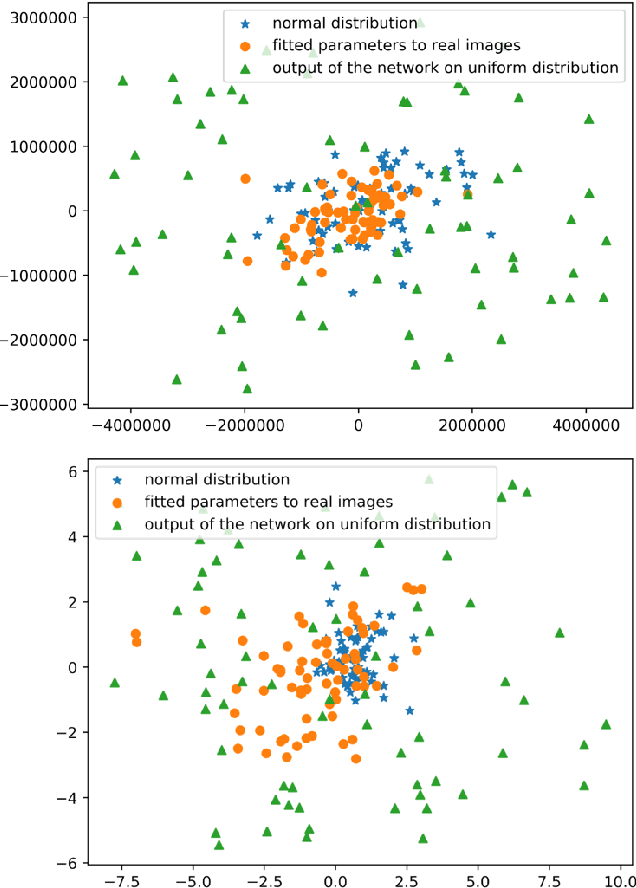
Face is one of the most important things for communication with the world around us. It also forms our identity and expressions. Estimating the face structure is a fundamental task in computer vision with applications in different areas such as face recognition and medical surgeries. Recently, deep learning techniques achieved significant results for 3D face reconstruction from flat images. The main challenge of such techniques is a vital need for large 3D face datasets. Usually, this challenge is handled by synthetic face generation. However, synthetic datasets suffer from the existence of non-possible faces. Here, we propose a face manifold learning method for synthetic diverse face dataset generation. First, the face structure is divided into the shape and expression groups. Then, a fully convolutional autoencoder network is exploited to deal with the non-possible faces, and, simultaneously, preserving the dataset diversity. Simulation results show that the proposed method is capable of denoising highly corrupted faces. The diversity of the generated dataset is evaluated qualitatively and quantitatively and compared to the existing methods. Experiments show that our manifold learning method outperforms the state of the art methods significantly.