 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Representations Improve Supervised Learning in Speech Emotion Recognition
Sep 22, 2023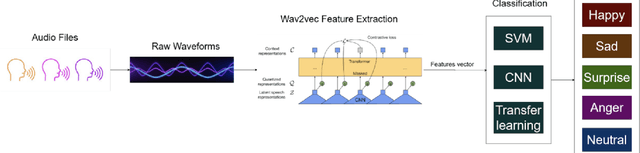



Speech Emotion Recognition (SER) plays a pivotal role in enhancing human-computer interaction by enabling a deeper understanding of emotional states across a wide range of applications, contributing to more empathetic and effective communication. This study proposes an innovative approach that integrates self-supervised feature extraction with supervised classification for emotion recognition from small audio segments. In the preprocessing step, to eliminate the need of crafting audio features, we employed a self-supervised feature extractor, based on the Wav2Vec model, to capture acoustic features from audio data. Then, the output featuremaps of the preprocessing step are fed to a custom designed Convolutional Neural Network (CNN)-based model to perform emotion classification. Utilizing the ShEMO dataset as our testing ground, the proposed method surpasses two baseline methods, i.e. support vector machine classifier and transfer learning of a pretrained CNN. comparing the propose method to the state-of-the-art methods in SER task indicates the superiority of the proposed method. Our findings underscore the pivotal role of deep unsupervised feature learning in elevating the landscape of SER, offering enhanced emotional comprehension in the realm of human-computer interactions.