 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficientNet-Absolute Zero for Continuous Speech Keyword Spotting
Paper and Code
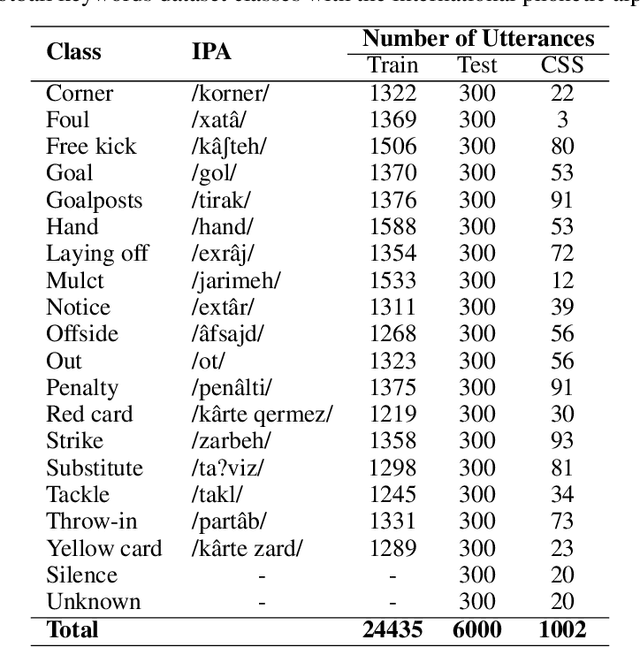
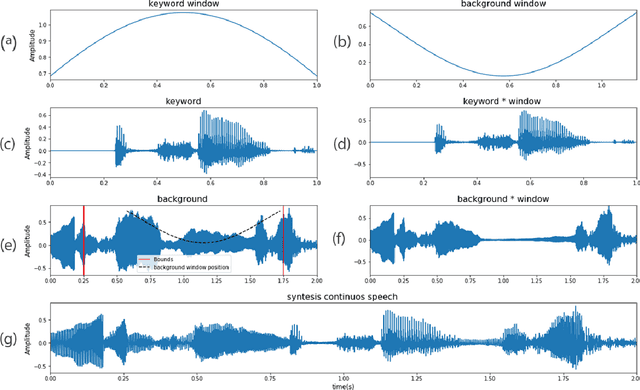
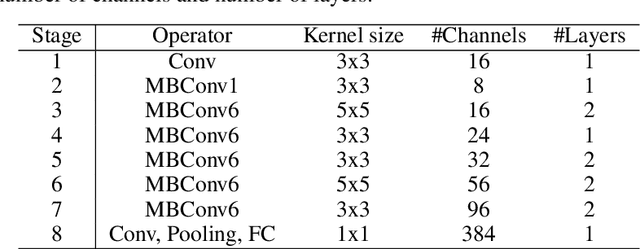
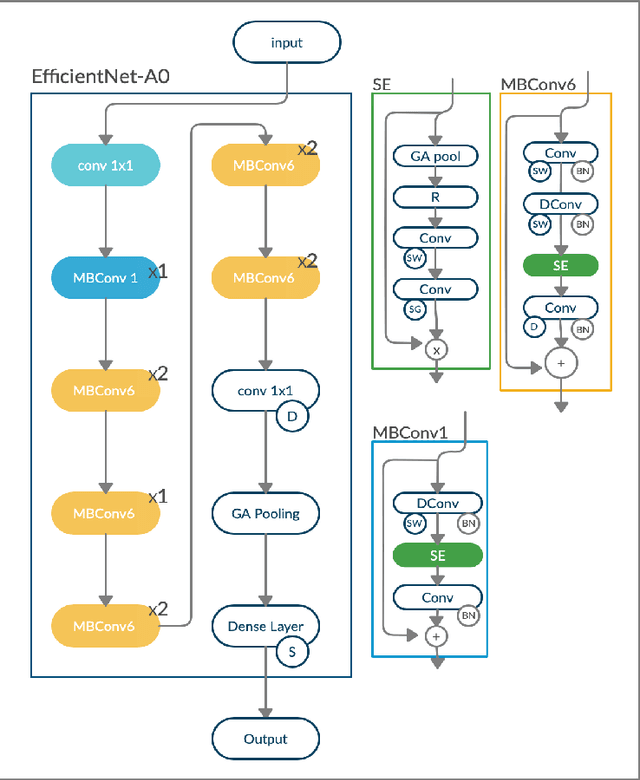
Keyword spotting is a process of finding some specific words or phrases in recorded speeches by computers. Deep neural network algorithms, as a powerful engine, can handle this problem if they are trained over an appropriate dataset. To this end, the football keyword dataset (FKD), as a new keyword spotting dataset in Persian, is collected with crowdsourcing. This dataset contains nearly 31000 samples in 18 classes. The continuous speech synthesis method proposed to made FKD usable in the practical application which works with continuous speeches. Besides, we proposed a lightweight architecture called EfficientNet-A0 (absolute zero) by applying the compound scaling method on EfficientNet-B0 for keyword spotting task. Finally, the proposed architecture is evaluated with various models. It is realized that EfficientNet-A0 and Resnet models outperform other models on this dataset.