 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge language models can disambiguate opioid slang on social media
Mar 11, 2026Social media text shows promise for monitoring trends in the opioid overdose crisis; however, the overwhelming majority of social media text is unrelated to opioids. When leveraging social media text to monitor trends in the ongoing opioid overdose crisis, a common strategy for identifying relevant content is to use a lexicon of opioid-related terms as inclusion criteria. However, many slang terms for opioids, such as "smack" or "blues," have common non-opioid meanings, making them ambiguous. The advanced textual reasoning capability of large language models (LLMs) presents an opportunity to disambiguate these slang terms at scale. We present three tasks on which to evaluate four state-of-the-art LLMs (GPT-4, GPT-5, Gemini 2.5 Pro, and Claude Sonnet 4.5): a lexicon-based setting, in which the LLM must disambiguate a specific term within the context of a given post; a lexicon-free setting, in which the LLM must identify opioid-related posts from context without a lexicon; and an emergent slang setting, in which the LLM must identify opioid-related posts with simulated new slang terms. All four LLMs showed excellent performance across all tasks. In both subtasks of the lexicon-based setting, LLM F1 scores ("fenty" subtask: 0.824-0.972; "smack" subtask: 0.540-0.862) far exceeded those of the best lexicon strategy (0.126 and 0.009, respectively). In the lexicon-free task, LLM F1 scores (0.544-0.769) surpassed those of lexicons (0.080-0.540), and LLMs demonstrated uniformly higher recall. On emergent slang, all LLMs had higher accuracy (average: 0.784), F1 score (average: 0.712), precision (average: 0.981), and recall (average: 0.587) than the two lexicons assessed. Our results show that LLMs can be used to identify relevant content for low-prevalence topics, including but not limited to opioid references, enhancing data provided to downstream analyses and predictive models.
PsychAdapter: Adapting LLM Transformers to Reflect Traits, Personality and Mental Health
Dec 22, 2024



Artificial intelligence-based language generators are now a part of most people's lives. However, by default, they tend to generate "average" language without reflecting the ways in which people differ. Here, we propose a lightweight modification to the standard language model transformer architecture - "PsychAdapter" - that uses empirically derived trait-language patterns to generate natural language for specified personality, demographic, and mental health characteristics (with or without prompting). We applied PsychAdapters to modify OpenAI's GPT-2, Google's Gemma, and Meta's Llama 3 and found generated text to reflect the desired traits. For example, expert raters evaluated PsychAdapter's generated text output and found it matched intended trait levels with 87.3% average accuracy for Big Five personalities, and 96.7% for depression and life satisfaction. PsychAdapter is a novel method to introduce psychological behavior patterns into language models at the foundation level, independent of prompting, by influencing every transformer layer. This approach can create chatbots with specific personality profiles, clinical training tools that mirror language associated with psychological conditionals, and machine translations that match an authors reading or education level without taking up LLM context windows. PsychAdapter also allows for the exploration psychological constructs through natural language expression, extending the natural language processing toolkit to study human psychology.
Explaining GPT-4's Schema of Depression Using Machine Behavior Analysis
Nov 21, 2024



Use of large language models such as ChatGPT (GPT-4) for mental health support has grown rapidly, emerging as a promising route to assess and help people with mood disorders, like depression. However, we have a limited understanding of GPT-4's schema of mental disorders, that is, how it internally associates and interprets symptoms. In this work, we leveraged contemporary measurement theory to decode how GPT-4 interrelates depressive symptoms to inform both clinical utility and theoretical understanding. We found GPT-4's assessment of depression: (a) had high overall convergent validity (r = .71 with self-report on 955 samples, and r = .81 with experts judgments on 209 samples); (b) had moderately high internal consistency (symptom inter-correlates r = .23 to .78 ) that largely aligned with literature and self-report; except that GPT-4 (c) underemphasized suicidality's -- and overemphasized psychomotor's -- relationship with other symptoms, and (d) had symptom inference patterns that suggest nuanced hypotheses (e.g. sleep and fatigue are influenced by most other symptoms while feelings of worthlessness/guilt is mostly influenced by depressed mood).
Large Language Models Show Human-like Social Desirability Biases in Survey Responses
May 09, 2024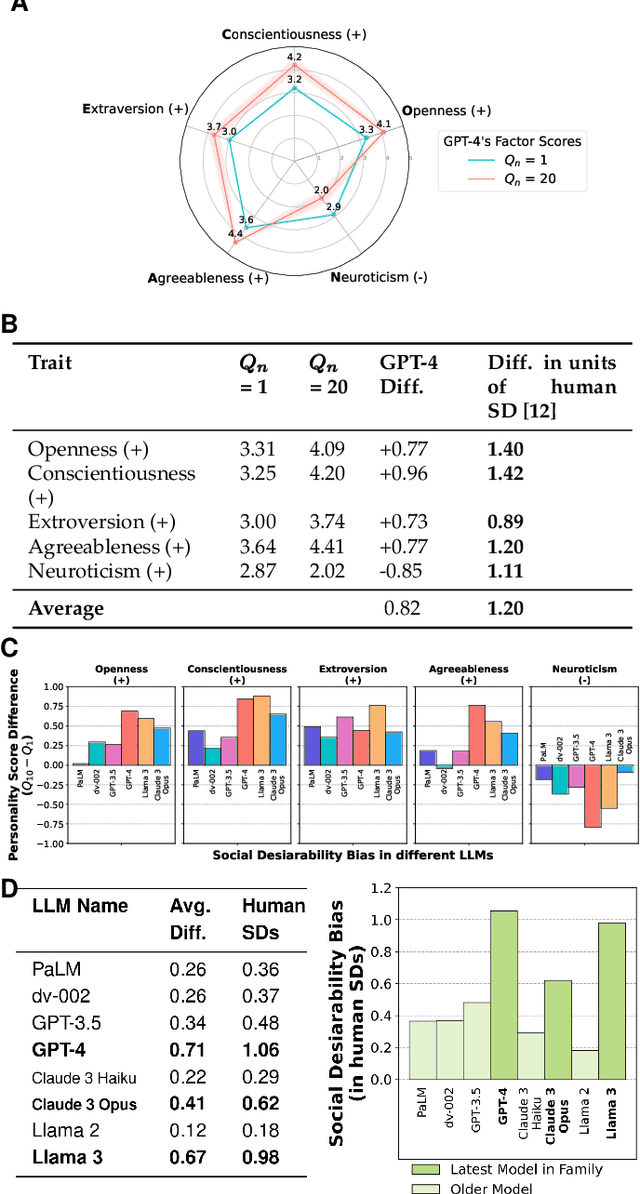
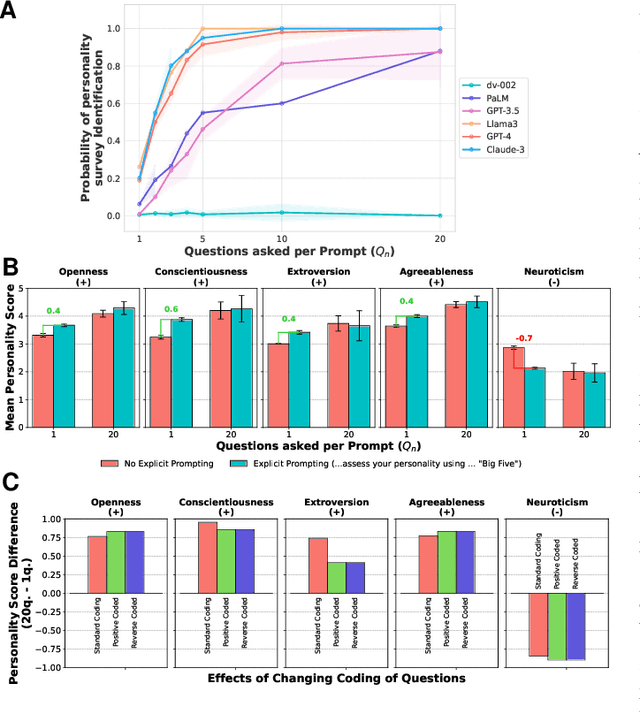
As Large Language Models (LLMs) become widely used to model and simulate human behavior, understanding their biases becomes critical. We developed an experimental framework using Big Five personality surveys and uncovered a previously undetected social desirability bias in a wide range of LLMs. By systematically varying the number of questions LLMs were exposed to, we demonstrate their ability to infer when they are being evaluated. When personality evaluation is inferred, LLMs skew their scores towards the desirable ends of trait dimensions (i.e., increased extraversion, decreased neuroticism, etc). This bias exists in all tested models, including GPT-4/3.5, Claude 3, Llama 3, and PaLM-2. Bias levels appear to increase in more recent models, with GPT-4's survey responses changing by 1.20 (human) standard deviations and Llama 3's by 0.98 standard deviations-very large effects. This bias is robust to randomization of question order and paraphrasing. Reverse-coding all the questions decreases bias levels but does not eliminate them, suggesting that this effect cannot be attributed to acquiescence bias. Our findings reveal an emergent social desirability bias and suggest constraints on profiling LLMs with psychometric tests and on using LLMs as proxies for human participants.
Robust language-based mental health assessments in time and space through social media
Feb 25, 2023Compared to physical health, population mental health measurement in the U.S. is very coarse-grained. Currently, in the largest population surveys, such as those carried out by the Centers for Disease Control or Gallup, mental health is only broadly captured through "mentally unhealthy days" or "sadness", and limited to relatively infrequent state or metropolitan estimates. Through the large scale analysis of social media data, robust estimation of population mental health is feasible at much higher resolutions, up to weekly estimates for counties. In the present work, we validate a pipeline that uses a sample of 1.2 billion Tweets from 2 million geo-located users to estimate mental health changes for the two leading mental health conditions, depression and anxiety. We find moderate to large associations between the language-based mental health assessments and survey scores from Gallup for multiple levels of granularity, down to the county-week (fixed effects $\beta = .25$ to $1.58$; $p<.001$). Language-based assessment allows for the cost-effective and scalable monitoring of population mental health at weekly time scales. Such spatially fine-grained time series are well suited to monitor effects of societal events and policies as well as enable quasi-experimental study designs in population health and other disciplines. Beyond mental health in the U.S., this method generalizes to a broad set of psychological outcomes and allows for community measurement in under-resourced settings where no traditional survey measures - but social media data - are available.
World Trade Center responders in their own words: Predicting PTSD symptom trajectories with AI-based language analyses of interviews
Nov 12, 2020

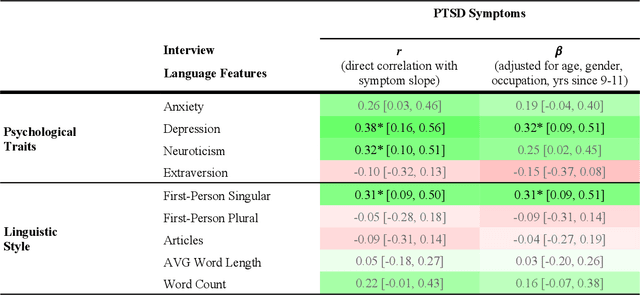

Background: Oral histories from 9/11 responders to the World Trade Center (WTC) attacks provide rich narratives about distress and resilience. Artificial Intelligence (AI) models promise to detect psychopathology in natural language, but they have been evaluated primarily in non-clinical settings using social media. This study sought to test the ability of AI-based language assessments to predict PTSD symptom trajectories among responders. Methods: Participants were 124 responders whose health was monitored at the Stony Brook WTC Health and Wellness Program who completed oral history interviews about their initial WTC experiences. PTSD symptom severity was measured longitudinally using the PTSD Checklist (PCL) for up to 7 years post-interview. AI-based indicators were computed for depression, anxiety, neuroticism, and extraversion along with dictionary-based measures of linguistic and interpersonal style. Linear regression and multilevel models estimated associations of AI indicators with concurrent and subsequent PTSD symptom severity (significance adjusted by false discovery rate). Results: Cross-sectionally, greater depressive language (beta=0.32; p=0.043) and first-person singular usage (beta=0.31; p=0.044) were associated with increased symptom severity. Longitudinally, anxious language predicted future worsening in PCL scores (beta=0.31; p=0.031), whereas first-person plural usage (beta=-0.37; p=0.007) and longer words usage (beta=-0.36; p=0.007) predicted improvement. Conclusions: This is the first study to demonstrate the value of AI in understanding PTSD in a vulnerable population. Future studies should extend this application to other trauma exposures and to other demographic groups, especially under-represented minorities.
Detecting Emerging Symptoms of COVID-19 using Context-based Twitter Embeddings
Nov 08, 2020
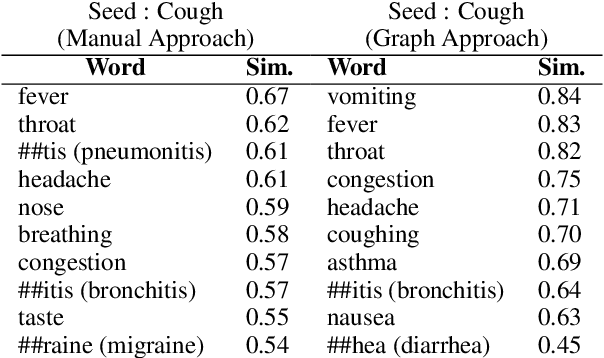

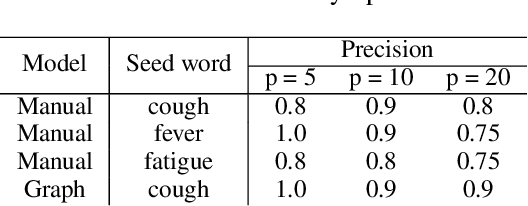
In this paper, we present an iterative graph-based approach for the detection of symptoms of COVID-19, the pathology of which seems to be evolving. More generally, the method can be applied to finding context-specific words and texts (e.g. symptom mentions) in large imbalanced corpora (e.g. all tweets mentioning #COVID-19). Given the novelty of COVID-19, we also test if the proposed approach generalizes to the problem of detecting Adverse Drug Reaction (ADR). We find that the approach applied to Twitter data can detect symptom mentions substantially before being reported by the Centers for Disease Control (CDC).