 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Word Sequences to Behavioral Sequences: Adapting Modeling and Evaluation Paradigms for Longitudinal NLP
Jan 12, 2026While NLP typically treats documents as independent and unordered samples, in longitudinal studies, this assumption rarely holds: documents are nested within authors and ordered in time, forming person-indexed, time-ordered $\textit{behavioral sequences}$. Here, we demonstrate the need for and propose a longitudinal modeling and evaluation paradigm that consequently updates four parts of the NLP pipeline: (1) evaluation splits aligned to generalization over people ($\textit{cross-sectional}$) and/or time ($\textit{prospective}$); (2) accuracy metrics separating between-person differences from within-person dynamics; (3) sequence inputs to incorporate history by default; and (4) model internals that support different $\textit{coarseness}$ of latent state over histories (pooled summaries, explicit dynamics, or interaction-based models). We demonstrate the issues ensued by traditional pipeline and our proposed improvements on a dataset of 17k daily diary transcripts paired with PTSD symptom severity from 238 participants, finding that traditional document-level evaluation can yield substantially different and sometimes reversed conclusions compared to our ecologically valid modeling and evaluation. We tie our results to a broader discussion motivating a shift from word-sequence evaluation toward $\textit{behavior-sequence}$ paradigms for NLP.
Discourse Relation Embeddings: Representing the Relations between Discourse Segments in Social Media
May 04, 2021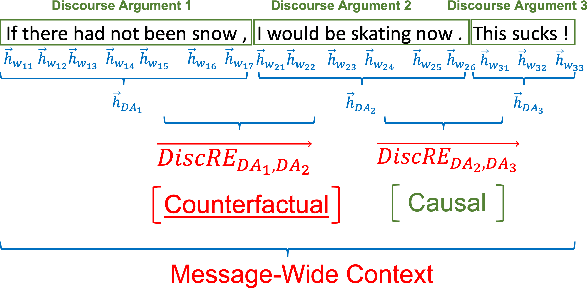
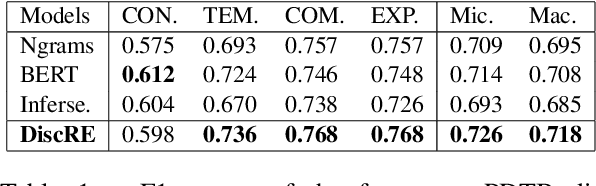
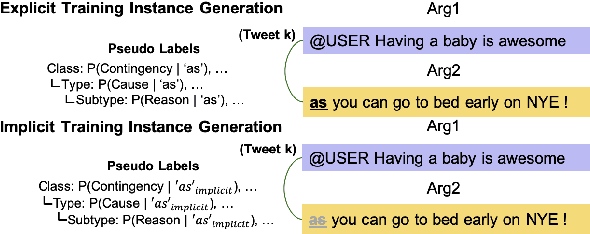
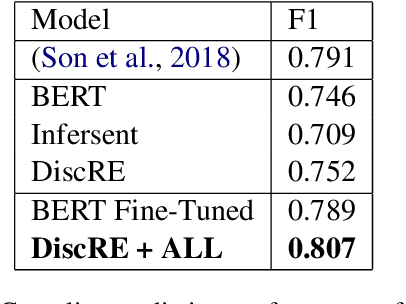
Discourse relations are typically modeled as a discrete class that characterizes the relation between segments of text (e.g. causal explanations, expansions). However, such predefined discrete classes limits the universe of potential relationships and their nuanced differences. Analogous to contextual word embeddings, we propose representing discourse relations as points in high dimensional continuous space. However, unlike words, discourse relations often have no surface form (relations are between two segments, often with no word or phrase in that gap) which presents a challenge for existing embedding techniques. We present a novel method for automatically creating discourse relation embeddings (DiscRE), addressing the embedding challenge through a weakly supervised, multitask approach to learn diverse and nuanced relations between discourse segments in social media. Results show DiscRE can: (1) obtain the best performance on Twitter discourse relation classification task (macro F1=0.76) (2) improve the state of the art in social media causality prediction (from F1=.79 to .81), (3) perform beyond modern sentence and contextual word embeddings at traditional discourse relation classification, and (4) capture novel nuanced relations (e.g. relations semantically at the intersection of causal explanations and counterfactuals).
World Trade Center responders in their own words: Predicting PTSD symptom trajectories with AI-based language analyses of interviews
Nov 12, 2020

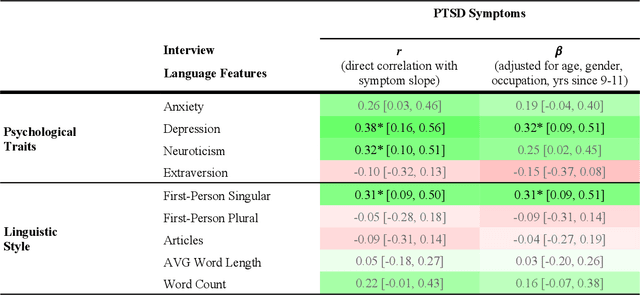

Background: Oral histories from 9/11 responders to the World Trade Center (WTC) attacks provide rich narratives about distress and resilience. Artificial Intelligence (AI) models promise to detect psychopathology in natural language, but they have been evaluated primarily in non-clinical settings using social media. This study sought to test the ability of AI-based language assessments to predict PTSD symptom trajectories among responders. Methods: Participants were 124 responders whose health was monitored at the Stony Brook WTC Health and Wellness Program who completed oral history interviews about their initial WTC experiences. PTSD symptom severity was measured longitudinally using the PTSD Checklist (PCL) for up to 7 years post-interview. AI-based indicators were computed for depression, anxiety, neuroticism, and extraversion along with dictionary-based measures of linguistic and interpersonal style. Linear regression and multilevel models estimated associations of AI indicators with concurrent and subsequent PTSD symptom severity (significance adjusted by false discovery rate). Results: Cross-sectionally, greater depressive language (beta=0.32; p=0.043) and first-person singular usage (beta=0.31; p=0.044) were associated with increased symptom severity. Longitudinally, anxious language predicted future worsening in PCL scores (beta=0.31; p=0.031), whereas first-person plural usage (beta=-0.37; p=0.007) and longer words usage (beta=-0.36; p=0.007) predicted improvement. Conclusions: This is the first study to demonstrate the value of AI in understanding PTSD in a vulnerable population. Future studies should extend this application to other trauma exposures and to other demographic groups, especially under-represented minorities.