 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Human-Centered Language Modeling: Is it Better to Model Groups, Individual Traits, or Both?
Jan 23, 2024



Natural language processing has made progress in incorporating human context into its models, but whether it is more effective to use group-wise attributes (e.g., over-45-year-olds) or model individuals remains open. Group attributes are technically easier but coarse: not all 45-year-olds write the same way. In contrast, modeling individuals captures the complexity of each person's identity. It allows for a more personalized representation, but we may have to model an infinite number of users and require data that may be impossible to get. We compare modeling human context via group attributes, individual users, and combined approaches. Combining group and individual features significantly benefits user-level regression tasks like age estimation or personality assessment from a user's documents. Modeling individual users significantly improves the performance of single document-level classification tasks like stance and topic detection. We also find that individual-user modeling does well even without user's historical data.
Robust language-based mental health assessments in time and space through social media
Feb 25, 2023Compared to physical health, population mental health measurement in the U.S. is very coarse-grained. Currently, in the largest population surveys, such as those carried out by the Centers for Disease Control or Gallup, mental health is only broadly captured through "mentally unhealthy days" or "sadness", and limited to relatively infrequent state or metropolitan estimates. Through the large scale analysis of social media data, robust estimation of population mental health is feasible at much higher resolutions, up to weekly estimates for counties. In the present work, we validate a pipeline that uses a sample of 1.2 billion Tweets from 2 million geo-located users to estimate mental health changes for the two leading mental health conditions, depression and anxiety. We find moderate to large associations between the language-based mental health assessments and survey scores from Gallup for multiple levels of granularity, down to the county-week (fixed effects $\beta = .25$ to $1.58$; $p<.001$). Language-based assessment allows for the cost-effective and scalable monitoring of population mental health at weekly time scales. Such spatially fine-grained time series are well suited to monitor effects of societal events and policies as well as enable quasi-experimental study designs in population health and other disciplines. Beyond mental health in the U.S., this method generalizes to a broad set of psychological outcomes and allows for community measurement in under-resourced settings where no traditional survey measures - but social media data - are available.
Human Language Modeling
May 10, 2022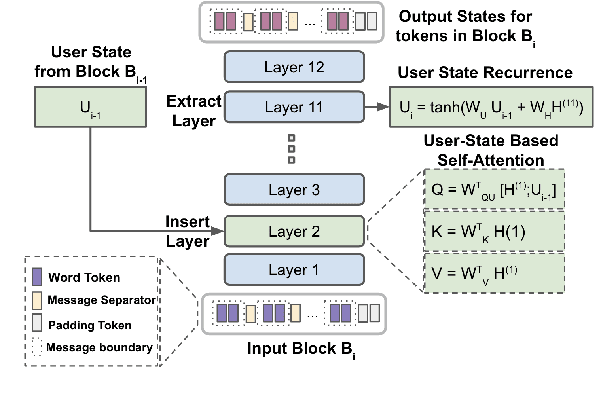
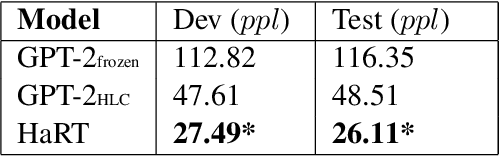
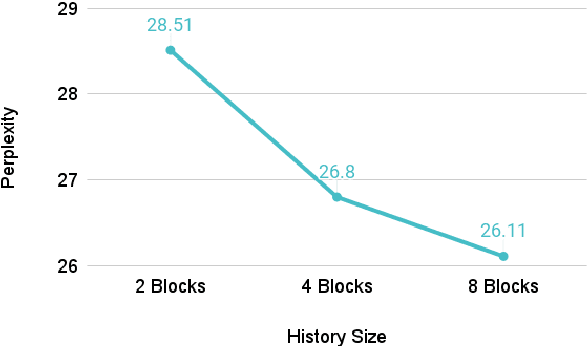
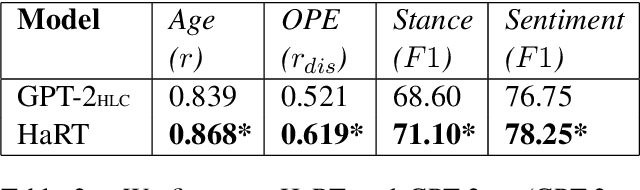
Natural language is generated by people, yet traditional language modeling views words or documents as if generated independently. Here, we propose human language modeling (HuLM), a hierarchical extension to the language modeling problem whereby a human-level exists to connect sequences of documents (e.g. social media messages) and capture the notion that human language is moderated by changing human states. We introduce, HaRT, a large-scale transformer model for the HuLM task, pre-trained on approximately 100,000 social media users, and demonstrate its effectiveness in terms of both language modeling (perplexity) for social media and fine-tuning for 4 downstream tasks spanning document- and user-levels: stance detection, sentiment classification, age estimation, and personality assessment. Results on all tasks meet or surpass the current state-of-the-art.
MeLT: Message-Level Transformer with Masked Document Representations as Pre-Training for Stance Detection
Sep 16, 2021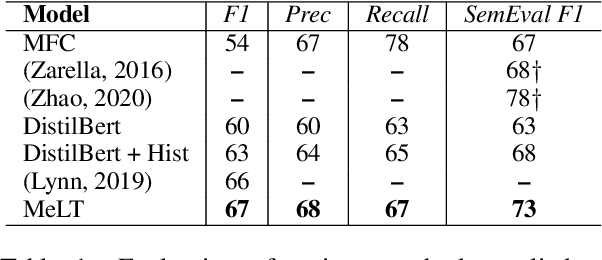
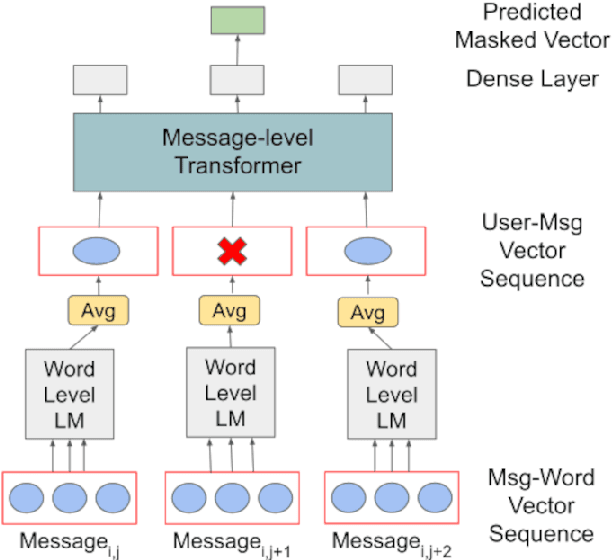
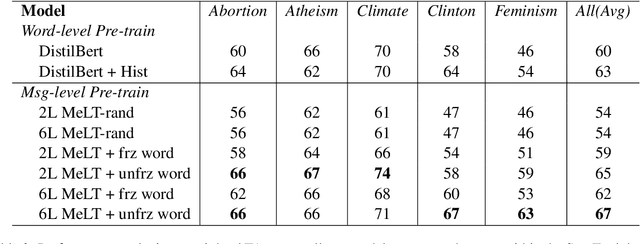
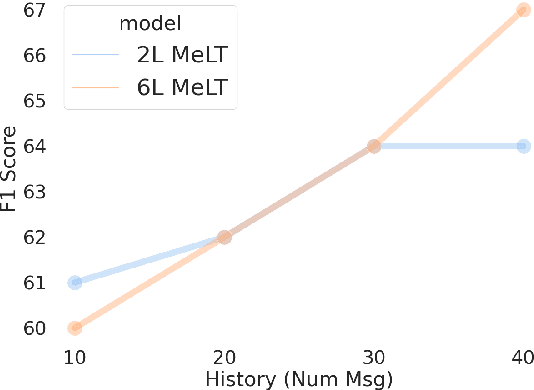
Much of natural language processing is focused on leveraging large capacity language models, typically trained over single messages with a task of predicting one or more tokens. However, modeling human language at higher-levels of context (i.e., sequences of messages) is under-explored. In stance detection and other social media tasks where the goal is to predict an attribute of a message, we have contextual data that is loosely semantically connected by authorship. Here, we introduce Message-Level Transformer (MeLT) -- a hierarchical message-encoder pre-trained over Twitter and applied to the task of stance prediction. We focus on stance prediction as a task benefiting from knowing the context of the message (i.e., the sequence of previous messages). The model is trained using a variant of masked-language modeling; where instead of predicting tokens, it seeks to generate an entire masked (aggregated) message vector via reconstruction loss. We find that applying this pre-trained masked message-level transformer to the downstream task of stance detection achieves F1 performance of 67%.