 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePsychAdapter: Adapting LLM Transformers to Reflect Traits, Personality and Mental Health
Dec 22, 2024



Artificial intelligence-based language generators are now a part of most people's lives. However, by default, they tend to generate "average" language without reflecting the ways in which people differ. Here, we propose a lightweight modification to the standard language model transformer architecture - "PsychAdapter" - that uses empirically derived trait-language patterns to generate natural language for specified personality, demographic, and mental health characteristics (with or without prompting). We applied PsychAdapters to modify OpenAI's GPT-2, Google's Gemma, and Meta's Llama 3 and found generated text to reflect the desired traits. For example, expert raters evaluated PsychAdapter's generated text output and found it matched intended trait levels with 87.3% average accuracy for Big Five personalities, and 96.7% for depression and life satisfaction. PsychAdapter is a novel method to introduce psychological behavior patterns into language models at the foundation level, independent of prompting, by influencing every transformer layer. This approach can create chatbots with specific personality profiles, clinical training tools that mirror language associated with psychological conditionals, and machine translations that match an authors reading or education level without taking up LLM context windows. PsychAdapter also allows for the exploration psychological constructs through natural language expression, extending the natural language processing toolkit to study human psychology.
Empirical Evaluation of Pre-trained Transformers for Human-Level NLP: The Role of Sample Size and Dimensionality
May 07, 2021
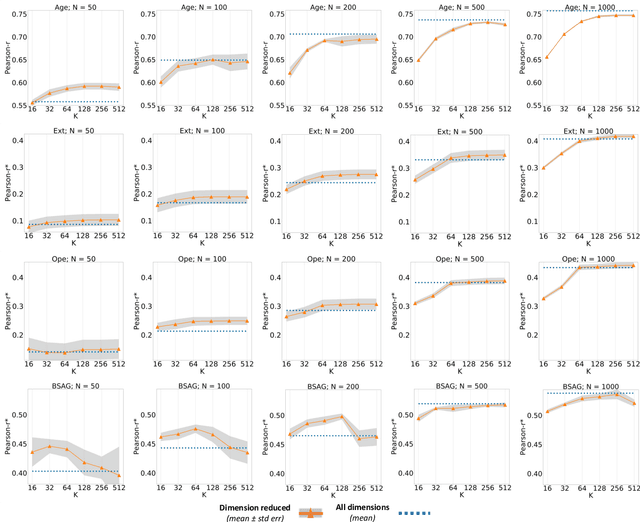
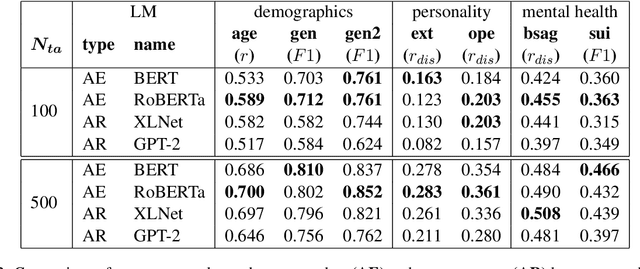
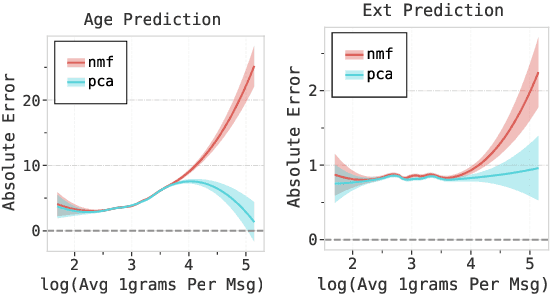
In human-level NLP tasks, such as predicting mental health, personality, or demographics, the number of observations is often smaller than the standard 768+ hidden state sizes of each layer within modern transformer-based language models, limiting the ability to effectively leverage transformers. Here, we provide a systematic study on the role of dimension reduction methods (principal components analysis, factorization techniques, or multi-layer auto-encoders) as well as the dimensionality of embedding vectors and sample sizes as a function of predictive performance. We first find that fine-tuning large models with a limited amount of data pose a significant difficulty which can be overcome with a pre-trained dimension reduction regime. RoBERTa consistently achieves top performance in human-level tasks, with PCA giving benefit over other reduction methods in better handling users that write longer texts. Finally, we observe that a majority of the tasks achieve results comparable to the best performance with just $\frac{1}{12}$ of the embedding dimensions.
Unrolling of Deep Graph Total Variation for Image Denoising
Oct 21, 2020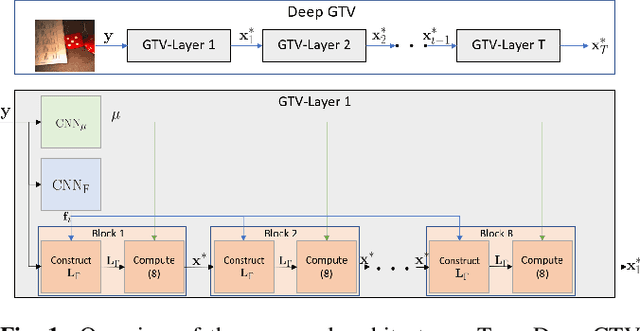
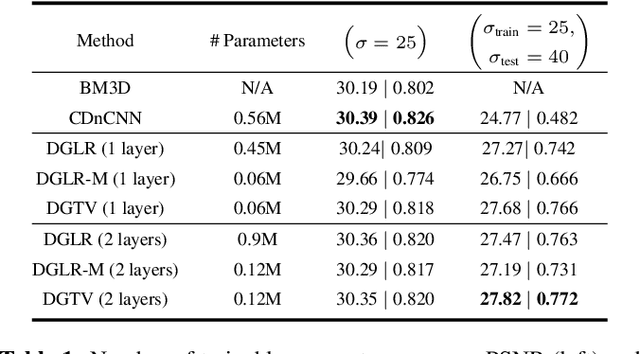
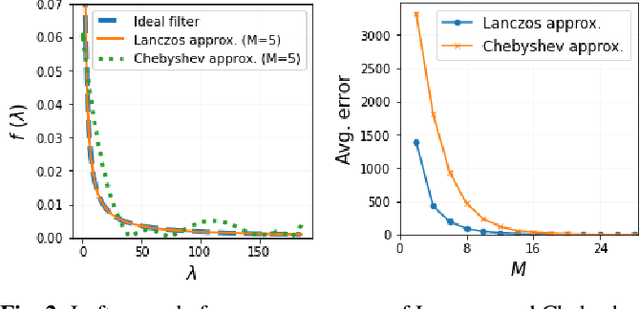

While deep learning (DL) architectures like convolutional neural networks (CNNs) have enabled effective solutions in image denoising, in general their implementations overly rely on training data, lack interpretability, and require tuning of a large parameter set. In this paper, we combine classical graph signal filtering with deep feature learning into a competitive hybrid design---one that utilizes interpretable analytical low-pass graph filters and employs 80% fewer network parameters than state-of-the-art DL denoising scheme DnCNN. Specifically, to construct a suitable similarity graph for graph spectral filtering, we first adopt a CNN to learn feature representations per pixel, and then compute feature distances to establish edge weights. Given a constructed graph, we next formulate a convex optimization problem for denoising using a graph total variation (GTV) prior. Via a $l_1$ graph Laplacian reformulation, we interpret its solution in an iterative procedure as a graph low-pass filter and derive its frequency response. For fast filter implementation, we realize this response using a Lanczos approximation. Experimental results show that in the case of statistical mistmatch, our algorithm outperformed DnCNN by up to 3dB in PSNR.