 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePsychAdapter: Adapting LLM Transformers to Reflect Traits, Personality and Mental Health
Dec 22, 2024



Artificial intelligence-based language generators are now a part of most people's lives. However, by default, they tend to generate "average" language without reflecting the ways in which people differ. Here, we propose a lightweight modification to the standard language model transformer architecture - "PsychAdapter" - that uses empirically derived trait-language patterns to generate natural language for specified personality, demographic, and mental health characteristics (with or without prompting). We applied PsychAdapters to modify OpenAI's GPT-2, Google's Gemma, and Meta's Llama 3 and found generated text to reflect the desired traits. For example, expert raters evaluated PsychAdapter's generated text output and found it matched intended trait levels with 87.3% average accuracy for Big Five personalities, and 96.7% for depression and life satisfaction. PsychAdapter is a novel method to introduce psychological behavior patterns into language models at the foundation level, independent of prompting, by influencing every transformer layer. This approach can create chatbots with specific personality profiles, clinical training tools that mirror language associated with psychological conditionals, and machine translations that match an authors reading or education level without taking up LLM context windows. PsychAdapter also allows for the exploration psychological constructs through natural language expression, extending the natural language processing toolkit to study human psychology.
HOIST-Former: Hand-held Objects Identification, Segmentation, and Tracking in the Wild
Apr 22, 2024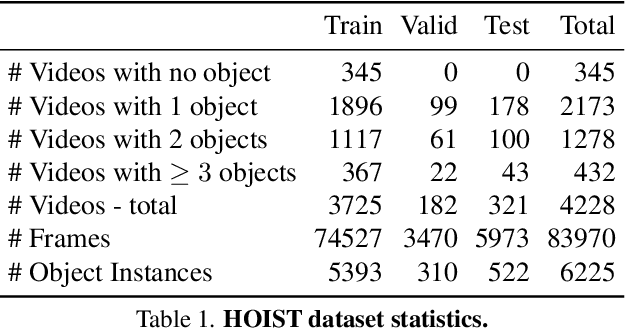
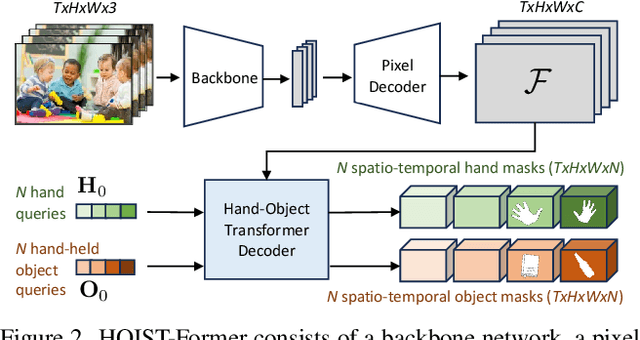
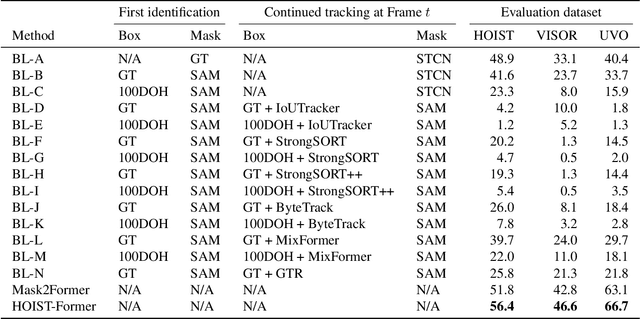
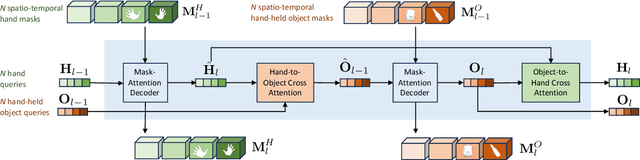
We address the challenging task of identifying, segmenting, and tracking hand-held objects, which is crucial for applications such as human action segmentation and performance evaluation. This task is particularly challenging due to heavy occlusion, rapid motion, and the transitory nature of objects being hand-held, where an object may be held, released, and subsequently picked up again. To tackle these challenges, we have developed a novel transformer-based architecture called HOIST-Former. HOIST-Former is adept at spatially and temporally segmenting hands and objects by iteratively pooling features from each other, ensuring that the processes of identification, segmentation, and tracking of hand-held objects depend on the hands' positions and their contextual appearance. We further refine HOIST-Former with a contact loss that focuses on areas where hands are in contact with objects. Moreover, we also contribute an in-the-wild video dataset called HOIST, which comprises 4,125 videos complete with bounding boxes, segmentation masks, and tracking IDs for hand-held objects. Through experiments on the HOIST dataset and two additional public datasets, we demonstrate the efficacy of HOIST-Former in segmenting and tracking hand-held objects.