 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHOIST-Former: Hand-held Objects Identification, Segmentation, and Tracking in the Wild
Paper and Code
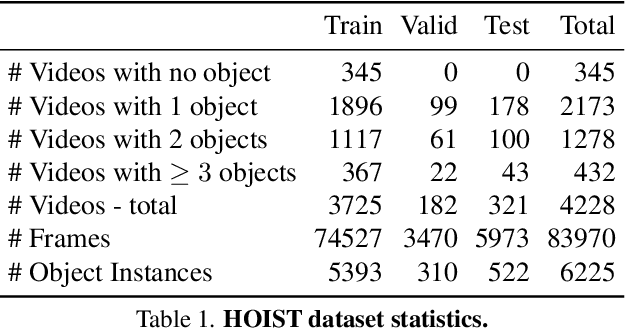
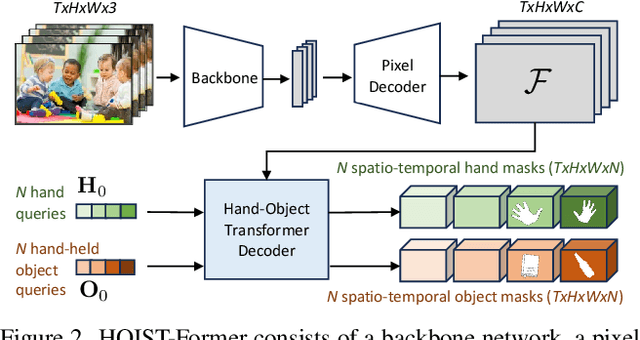
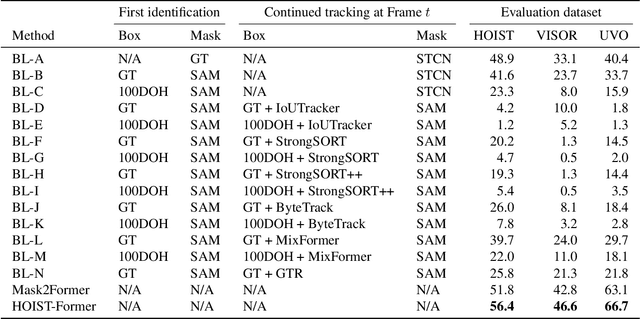
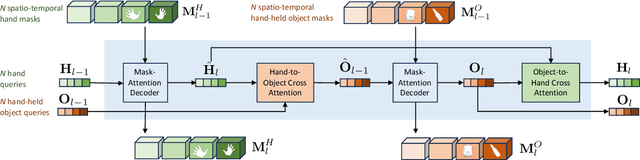
We address the challenging task of identifying, segmenting, and tracking hand-held objects, which is crucial for applications such as human action segmentation and performance evaluation. This task is particularly challenging due to heavy occlusion, rapid motion, and the transitory nature of objects being hand-held, where an object may be held, released, and subsequently picked up again. To tackle these challenges, we have developed a novel transformer-based architecture called HOIST-Former. HOIST-Former is adept at spatially and temporally segmenting hands and objects by iteratively pooling features from each other, ensuring that the processes of identification, segmentation, and tracking of hand-held objects depend on the hands' positions and their contextual appearance. We further refine HOIST-Former with a contact loss that focuses on areas where hands are in contact with objects. Moreover, we also contribute an in-the-wild video dataset called HOIST, which comprises 4,125 videos complete with bounding boxes, segmentation masks, and tracking IDs for hand-held objects. Through experiments on the HOIST dataset and two additional public datasets, we demonstrate the efficacy of HOIST-Former in segmenting and tracking hand-held objects.