 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniCTokens: Boosting Personalized Understanding and Generation via Unified Concept Tokens
May 20, 2025Personalized models have demonstrated remarkable success in understanding and generating concepts provided by users. However, existing methods use separate concept tokens for understanding and generation, treating these tasks in isolation. This may result in limitations for generating images with complex prompts. For example, given the concept $\langle bo\rangle$, generating "$\langle bo\rangle$ wearing its hat" without additional textual descriptions of its hat. We call this kind of generation personalized knowledge-driven generation. To address the limitation, we present UniCTokens, a novel framework that effectively integrates personalized information into a unified vision language model (VLM) for understanding and generation. UniCTokens trains a set of unified concept tokens to leverage complementary semantics, boosting two personalized tasks. Moreover, we propose a progressive training strategy with three stages: understanding warm-up, bootstrapping generation from understanding, and deepening understanding from generation to enhance mutual benefits between both tasks. To quantitatively evaluate the unified VLM personalization, we present UnifyBench, the first benchmark for assessing concept understanding, concept generation, and knowledge-driven generation. Experimental results on UnifyBench indicate that UniCTokens shows competitive performance compared to leading methods in concept understanding, concept generation, and achieving state-of-the-art results in personalized knowledge-driven generation. Our research demonstrates that enhanced understanding improves generation, and the generation process can yield valuable insights into understanding. Our code and dataset will be released at: \href{https://github.com/arctanxarc/UniCTokens}{https://github.com/arctanxarc/UniCTokens}.
TemporalBench: Benchmarking Fine-grained Temporal Understanding for Multimodal Video Models
Oct 15, 2024



Understanding fine-grained temporal dynamics is crucial for multimodal video comprehension and generation. Due to the lack of fine-grained temporal annotations, existing video benchmarks mostly resemble static image benchmarks and are incompetent at evaluating models for temporal understanding. In this paper, we introduce TemporalBench, a new benchmark dedicated to evaluating fine-grained temporal understanding in videos. TemporalBench consists of ~10K video question-answer pairs, derived from ~2K high-quality human annotations detailing the temporal dynamics in video clips. As a result, our benchmark provides a unique testbed for evaluating various temporal understanding and reasoning abilities such as action frequency, motion magnitude, event order, etc. Moreover, it enables evaluations on various tasks like both video question answering and captioning, both short and long video understanding, as well as different models such as multimodal video embedding models and text generation models. Results show that state-of-the-art models like GPT-4o achieve only 38.5% question answering accuracy on TemporalBench, demonstrating a significant gap (~30%) between humans and AI in temporal understanding. Furthermore, we notice a critical pitfall for multi-choice QA where LLMs can detect the subtle changes in negative captions and find a centralized description as a cue for its prediction, where we propose Multiple Binary Accuracy (MBA) to correct such bias. We hope that TemporalBench can foster research on improving models' temporal reasoning capabilities. Both dataset and evaluation code will be made available.
VGBench: Evaluating Large Language Models on Vector Graphics Understanding and Generation
Jul 15, 2024In the realm of vision models, the primary mode of representation is using pixels to rasterize the visual world. Yet this is not always the best or unique way to represent visual content, especially for designers and artists who depict the world using geometry primitives such as polygons. Vector graphics (VG), on the other hand, offer a textual representation of visual content, which can be more concise and powerful for content like cartoons or sketches. Recent studies have shown promising results on processing vector graphics with capable Large Language Models (LLMs). However, such works focus solely on qualitative results, understanding, or a specific type of vector graphics. We propose VGBench, a comprehensive benchmark for LLMs on handling vector graphics through diverse aspects, including (a) both visual understanding and generation, (b) evaluation of various vector graphics formats, (c) diverse question types, (d) wide range of prompting techniques, (e) under multiple LLMs. Evaluating on our collected 4279 understanding and 5845 generation samples, we find that LLMs show strong capability on both aspects while exhibiting less desirable performance on low-level formats (SVG). Both data and evaluation pipeline will be open-sourced at https://vgbench.github.io.
LLM as Dataset Analyst: Subpopulation Structure Discovery with Large Language Model
May 03, 2024



The distribution of subpopulations is an important property hidden within a dataset. Uncovering and analyzing the subpopulation distribution within datasets provides a comprehensive understanding of the datasets, standing as a powerful tool beneficial to various downstream tasks, including Dataset Subpopulation Organization, Subpopulation Shift, and Slice Discovery. Despite its importance, there has been no work that systematically explores the subpopulation distribution of datasets to our knowledge. To address the limitation and solve all the mentioned tasks in a unified way, we introduce a novel concept of subpopulation structures to represent, analyze, and utilize subpopulation distributions within datasets. To characterize the structures in an interpretable manner, we propose the Subpopulation Structure Discovery with Large Language Models (SSD-LLM) framework, which employs world knowledge and instruction-following capabilities of Large Language Models (LLMs) to linguistically analyze informative image captions and summarize the structures. Furthermore, we propose complete workflows to address downstream tasks, named Task-specific Tuning, showcasing the application of the discovered structure to a spectrum of subpopulation-related tasks, including dataset subpopulation organization, subpopulation shift, and slice discovery. Furthermore, we propose complete workflows to address downstream tasks, named Task-specific Tuning, showcasing the application of the discovered structure to a spectrum of subpopulation-related tasks, including dataset subpopulation organization, subpopulation shift, and slice discovery.
Draw-and-Understand: Leveraging Visual Prompts to Enable MLLMs to Comprehend What You Want
Apr 01, 2024
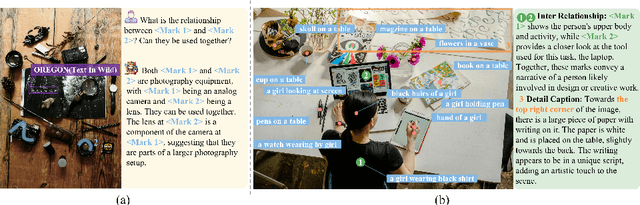
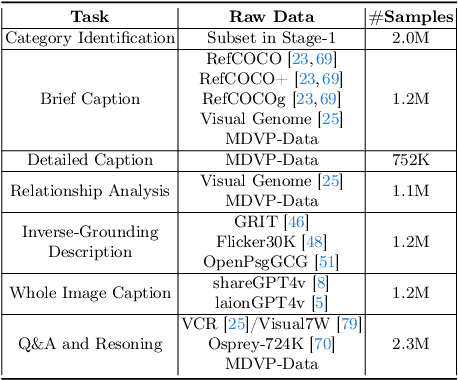

The interaction between humans and artificial intelligence (AI) is a crucial factor that reflects the effectiveness of multimodal large language models (MLLMs). However, current MLLMs primarily focus on image-level comprehension and limit interaction to textual instructions, thereby constraining their flexibility in usage and depth of response. In this paper, we introduce the Draw-and-Understand project: a new model, a multi-domain dataset, and a challenging benchmark for visual prompting. Specifically, we propose SPHINX-V, a new end-to-end trained Multimodal Large Language Model (MLLM) that connects a vision encoder, a visual prompt encoder and an LLM for various visual prompts (points, bounding boxes, and free-form shape) and language understanding. To advance visual prompting research for MLLMs, we introduce MDVP-Data and MDVP-Bench. MDVP-Data features a multi-domain dataset containing 1.6M unique image-visual prompt-text instruction-following samples, including natural images, document images, OCR images, mobile screenshots, web screenshots, and multi-panel images. Furthermore, we present MDVP-Bench, a comprehensive and challenging benchmark to assess a model's capability in understanding visual prompting instructions. Our experiments demonstrate SPHINX-V's impressive multimodal interaction capabilities through visual prompting, revealing significant improvements in detailed pixel-level description and question-answering abilities.
Split & Merge: Unlocking the Potential of Visual Adapters via Sparse Training
Dec 05, 2023With the rapid growth in the scale of pre-trained foundation models, parameter-efficient fine-tuning techniques have gained significant attention, among which Adapter Tuning is the most widely used. Despite achieving efficiency, Adapter Tuning still underperforms full fine-tuning, and the performance improves at the cost of an increase in parameters. Recent efforts address this issue by pruning the original adapters, but it also introduces training instability and suboptimal performance on certain datasets. Motivated by this, we propose Mixture of Sparse Adapters, or MoSA, as a novel Adapter Tuning method to fully unleash the potential of each parameter in the adapter. We first split the standard adapter into multiple non-overlapping modules, then stochastically activate modules for sparse training, and finally merge them to form a complete adapter after tuning. In this way, MoSA can achieve significantly better performance than standard adapters without any additional computational or storage overhead. Furthermore, we propose a hierarchical sparse strategy to better leverage limited training data. Extensive experiments on a series of 27 visual tasks demonstrate that MoSA consistently outperforms other Adapter Tuning methods as well as other baselines by a significant margin. Furthermore, in two challenging scenarios with low-resource and multi-task settings, MoSA achieves satisfactory results, further demonstrating the effectiveness of our design. Our code will be released.