 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Self-Supervised Learning with Effective Contrastive Units for LiDAR Point Clouds
Sep 10, 2024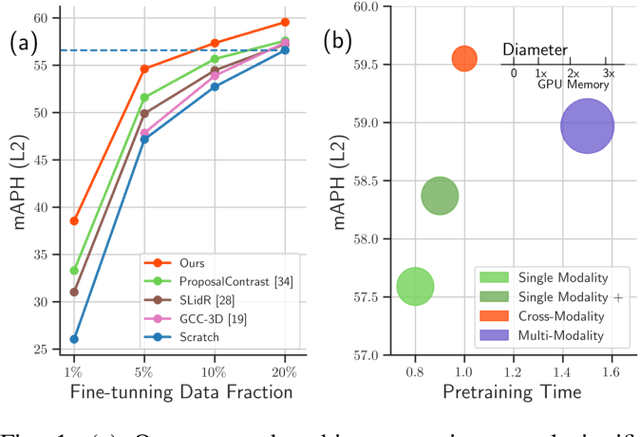
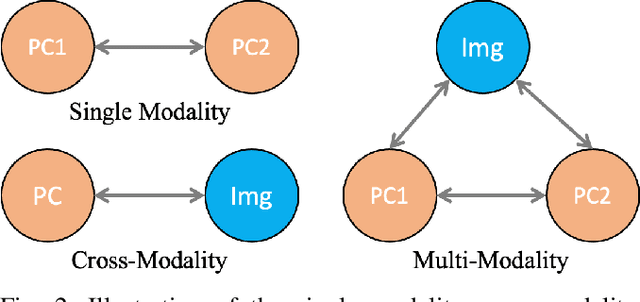
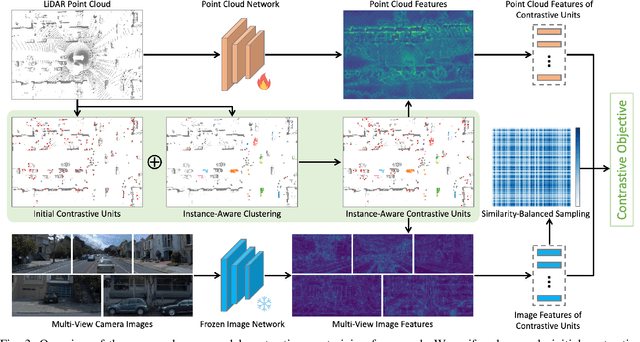

3D perception in LiDAR point clouds is crucial for a self-driving vehicle to properly act in 3D environment. However, manually labeling point clouds is hard and costly. There has been a growing interest in self-supervised pre-training of 3D perception models. Following the success of contrastive learning in images, current methods mostly conduct contrastive pre-training on point clouds only. Yet an autonomous driving vehicle is typically supplied with multiple sensors including cameras and LiDAR. In this context, we systematically study single modality, cross-modality, and multi-modality for contrastive learning of point clouds, and show that cross-modality wins over other alternatives. In addition, considering the huge difference between the training sources in 2D images and 3D point clouds, it remains unclear how to design more effective contrastive units for LiDAR. We therefore propose the instance-aware and similarity-balanced contrastive units that are tailored for self-driving point clouds. Extensive experiments reveal that our approach achieves remarkable performance gains over various point cloud models across the downstream perception tasks of LiDAR based 3D object detection and 3D semantic segmentation on the four popular benchmarks including Waymo Open Dataset, nuScenes, SemanticKITTI and ONCE.
DistillBEV: Boosting Multi-Camera 3D Object Detection with Cross-Modal Knowledge Distillation
Sep 26, 2023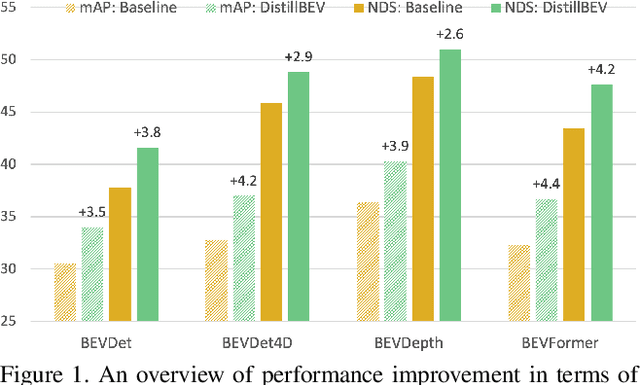
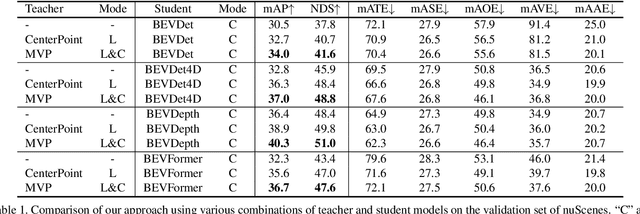
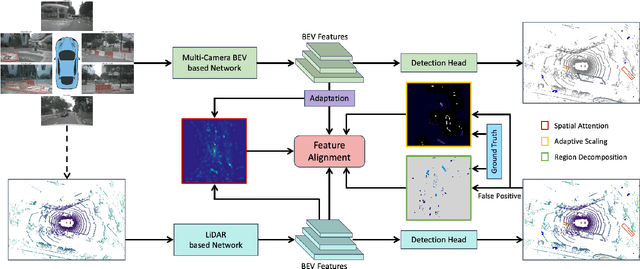
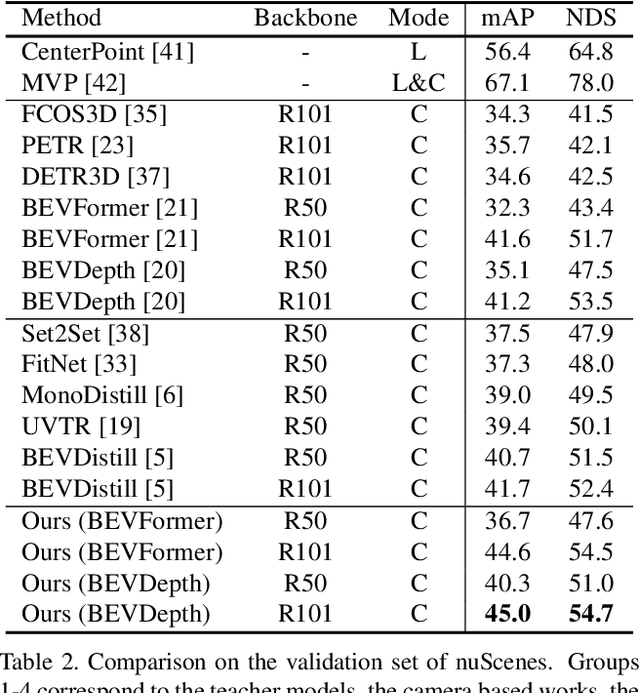
3D perception based on the representations learned from multi-camera bird's-eye-view (BEV) is trending as cameras are cost-effective for mass production in autonomous driving industry. However, there exists a distinct performance gap between multi-camera BEV and LiDAR based 3D object detection. One key reason is that LiDAR captures accurate depth and other geometry measurements, while it is notoriously challenging to infer such 3D information from merely image input. In this work, we propose to boost the representation learning of a multi-camera BEV based student detector by training it to imitate the features of a well-trained LiDAR based teacher detector. We propose effective balancing strategy to enforce the student to focus on learning the crucial features from the teacher, and generalize knowledge transfer to multi-scale layers with temporal fusion. We conduct extensive evaluations on multiple representative models of multi-camera BEV. Experiments reveal that our approach renders significant improvement over the student models, leading to the state-of-the-art performance on the popular benchmark nuScenes.
PillarNeXt: Rethinking Network Designs for 3D Object Detection in LiDAR Point Clouds
May 08, 2023In order to deal with the sparse and unstructured raw point clouds, LiDAR based 3D object detection research mostly focuses on designing dedicated local point aggregators for fine-grained geometrical modeling. In this paper, we revisit the local point aggregators from the perspective of allocating computational resources. We find that the simplest pillar based models perform surprisingly well considering both accuracy and latency. Additionally, we show that minimal adaptions from the success of 2D object detection, such as enlarging receptive field, significantly boost the performance. Extensive experiments reveal that our pillar based networks with modernized designs in terms of architecture and training render the state-of-the-art performance on the two popular benchmarks: Waymo Open Dataset and nuScenes. Our results challenge the common intuition that the detailed geometry modeling is essential to achieve high performance for 3D object detection.
Exploring Simple 3D Multi-Object Tracking for Autonomous Driving
Aug 23, 2021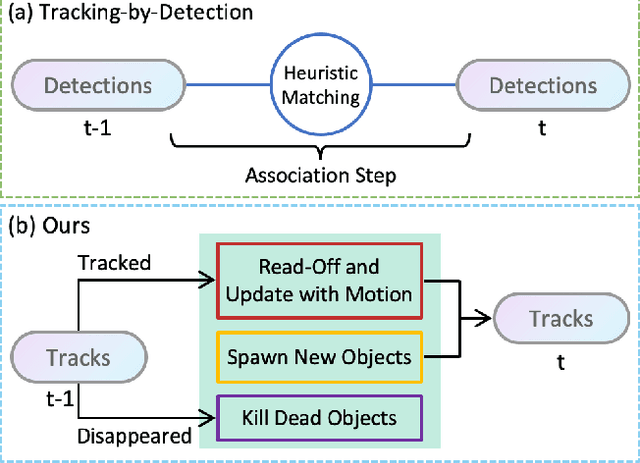
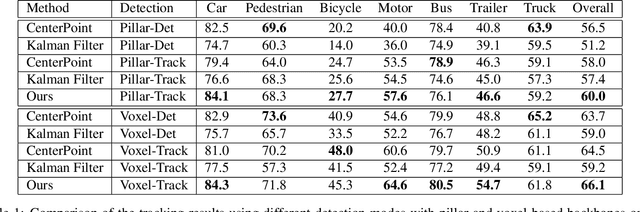
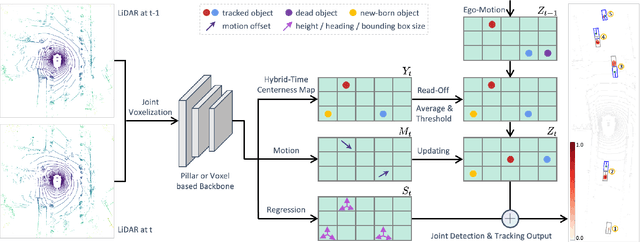

3D multi-object tracking in LiDAR point clouds is a key ingredient for self-driving vehicles. Existing methods are predominantly based on the tracking-by-detection pipeline and inevitably require a heuristic matching step for the detection association. In this paper, we present SimTrack to simplify the hand-crafted tracking paradigm by proposing an end-to-end trainable model for joint detection and tracking from raw point clouds. Our key design is to predict the first-appear location of each object in a given snippet to get the tracking identity and then update the location based on motion estimation. In the inference, the heuristic matching step can be completely waived by a simple read-off operation. SimTrack integrates the tracked object association, newborn object detection, and dead track killing in a single unified model. We conduct extensive evaluations on two large-scale datasets: nuScenes and Waymo Open Dataset. Experimental results reveal that our simple approach compares favorably with the state-of-the-art methods while ruling out the heuristic matching rules.
Self-Supervised Pillar Motion Learning for Autonomous Driving
Apr 18, 2021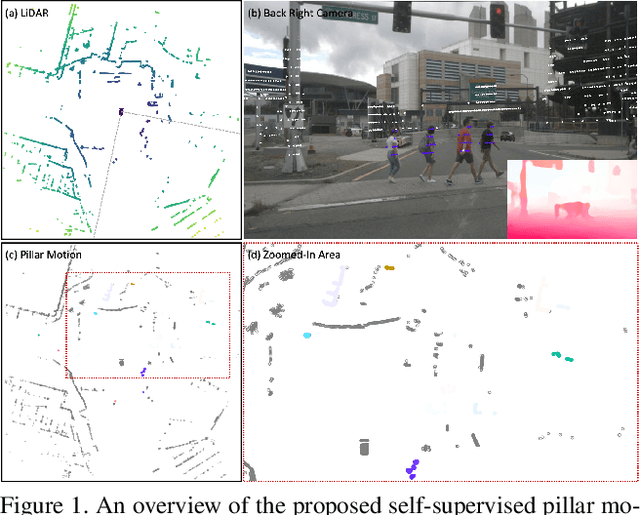

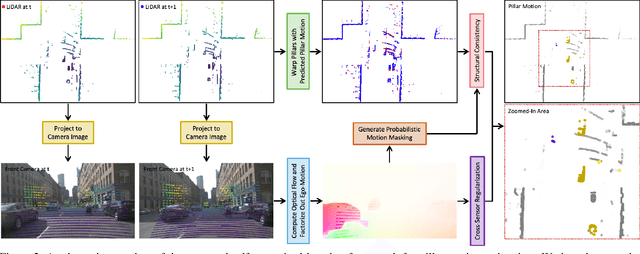

Autonomous driving can benefit from motion behavior comprehension when interacting with diverse traffic participants in highly dynamic environments. Recently, there has been a growing interest in estimating class-agnostic motion directly from point clouds. Current motion estimation methods usually require vast amount of annotated training data from self-driving scenes. However, manually labeling point clouds is notoriously difficult, error-prone and time-consuming. In this paper, we seek to answer the research question of whether the abundant unlabeled data collections can be utilized for accurate and efficient motion learning. To this end, we propose a learning framework that leverages free supervisory signals from point clouds and paired camera images to estimate motion purely via self-supervision. Our model involves a point cloud based structural consistency augmented with probabilistic motion masking as well as a cross-sensor motion regularization to realize the desired self-supervision. Experiments reveal that our approach performs competitively to supervised methods, and achieves the state-of-the-art result when combining our self-supervised model with supervised fine-tuning.
Probabilistic Multi-modal Trajectory Prediction with Lane Attention for Autonomous Vehicles
Jul 06, 2020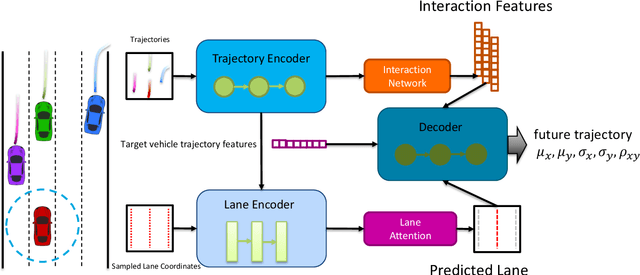
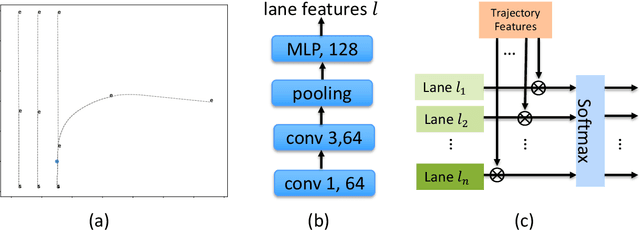
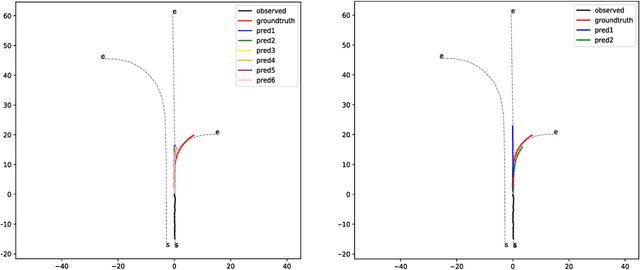
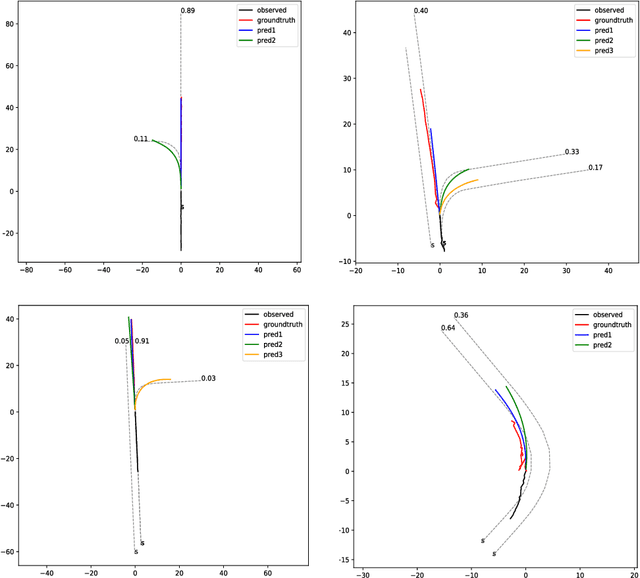
Trajectory prediction is crucial for autonomous vehicles. The planning system not only needs to know the current state of the surrounding objects but also their possible states in the future. As for vehicles, their trajectories are significantly influenced by the lane geometry and how to effectively use the lane information is of active interest. Most of the existing works use rasterized maps to explore road information, which does not distinguish different lanes. In this paper, we propose a novel instance-aware representation for lane representation. By integrating the lane features and trajectory features, a goal-oriented lane attention module is proposed to predict the future locations of the vehicle. We show that the proposed lane representation together with the lane attention module can be integrated into the widely used encoder-decoder framework to generate diverse predictions. Most importantly, each generated trajectory is associated with a probability to handle the uncertainty. Our method does not suffer from collapsing to one behavior modal and can cover diverse possibilities. Extensive experiments and ablation studies on the benchmark datasets corroborate the effectiveness of our proposed method. Notably, our proposed method ranks third place in the Argoverse motion forecasting competition at NeurIPS 2019.
Grouped Spatial-Temporal Aggregation for Efficient Action Recognition
Sep 28, 2019

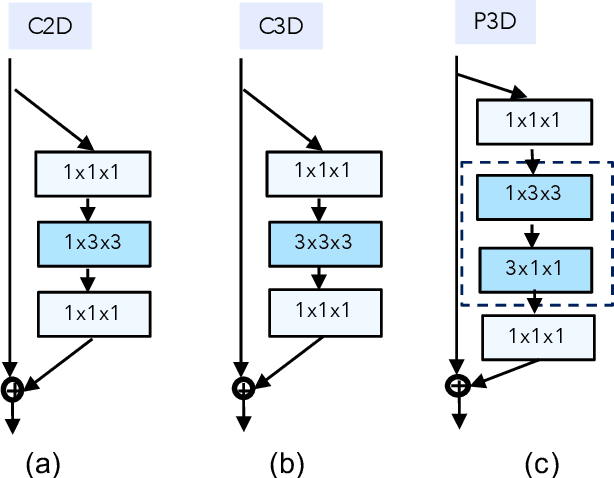
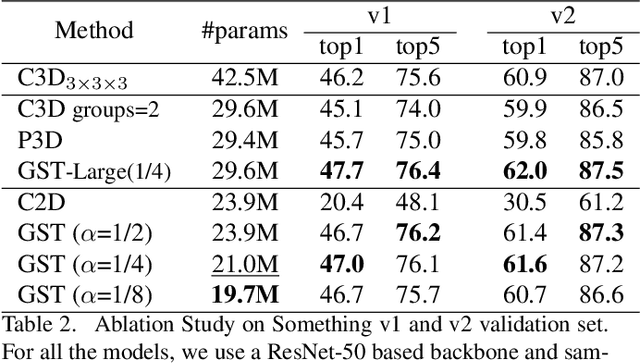
Temporal reasoning is an important aspect of video analysis. 3D CNN shows good performance by exploring spatial-temporal features jointly in an unconstrained way, but it also increases the computational cost a lot. Previous works try to reduce the complexity by decoupling the spatial and temporal filters. In this paper, we propose a novel decomposition method that decomposes the feature channels into spatial and temporal groups in parallel. This decomposition can make two groups focus on static and dynamic cues separately. We call this grouped spatial-temporal aggregation (GST). This decomposition is more parameter-efficient and enables us to quantitatively analyze the contributions of spatial and temporal features in different layers. We verify our model on several action recognition tasks that require temporal reasoning and show its effectiveness.
* ICCV 2019
OriNet: A Fully Convolutional Network for 3D Human Pose Estimation
Nov 12, 2018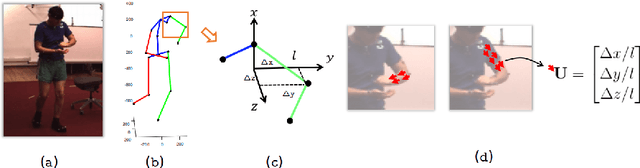
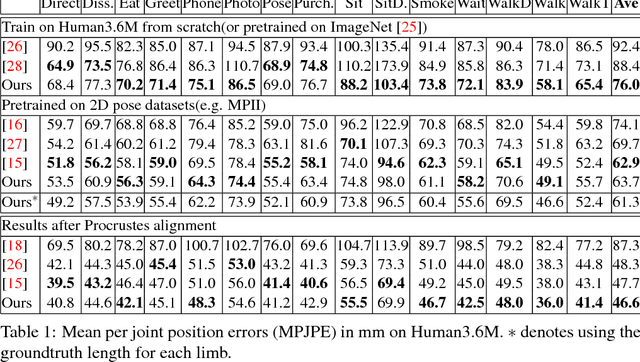
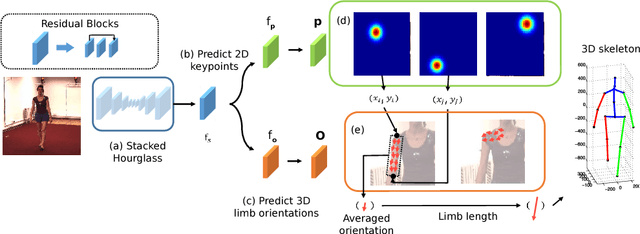
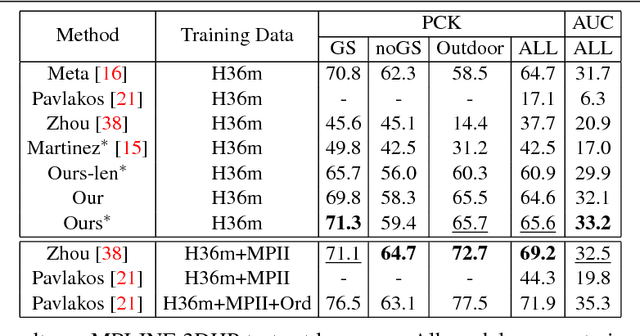
In this paper, we propose a fully convolutional network for 3D human pose estimation from monocular images. We use limb orientations as a new way to represent 3D poses and bind the orientation together with the bounding box of each limb region to better associate images and predictions. The 3D orientations are modeled jointly with 2D keypoint detections. Without additional constraints, this simple method can achieve good results on several large-scale benchmarks. Further experiments show that our method can generalize well to novel scenes and is robust to inaccurate bounding boxes.
* BMVC 2018. Code available at https://github.com/chenxuluo/OriNet-demo
Every Pixel Counts ++: Joint Learning of Geometry and Motion with 3D Holistic Understanding
Oct 14, 2018

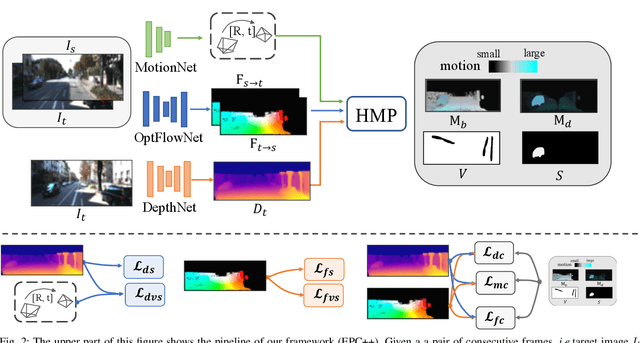
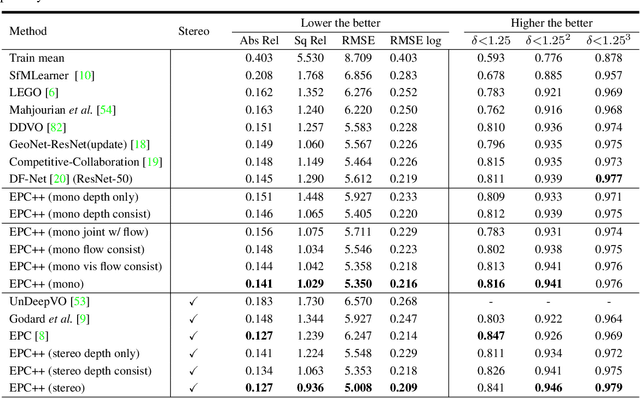
Learning to estimate 3D geometry in a single frame and optical flow from consecutive frames by watching unlabeled videos via deep convolutional network has made significant process recently. Current state-of-the-art (SOTA) methods treat the tasks independently. One important assumption of the current depth estimation pipeline is that the scene contains no moving object, which can be complemented by the optical flow. In this paper, we propose to address the two tasks as a whole, i.e. to jointly understand per-pixel 3D geometry and motion. This also eliminates the need of static scene assumption and enforces the inherent geometrical consistency during the learning process, yielding significantly improved results for both tasks. We call our method as "Every Pixel Counts++" or "EPC++". Specifically, during training, given two consecutive frames from a video, we adopt three parallel networks to predict the camera motion (MotionNet), dense depth map (DepthNet), and per-pixel optical flow between two frames (FlowNet) respectively. Comprehensive experiments were conducted on the KITTI 2012 and KITTI 2015 datasets. Performance on the five tasks of depth estimation, optical flow estimation, odometry, moving object segmentation and scene flow estimation shows that our approach outperforms other SOTA methods, demonstrating the effectiveness of each module of our proposed method.
Joint Unsupervised Learning of Optical Flow and Depth by Watching Stereo Videos
Oct 08, 2018
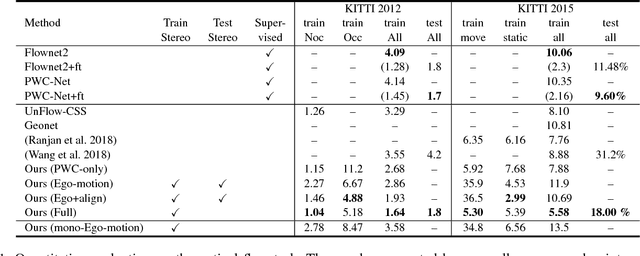
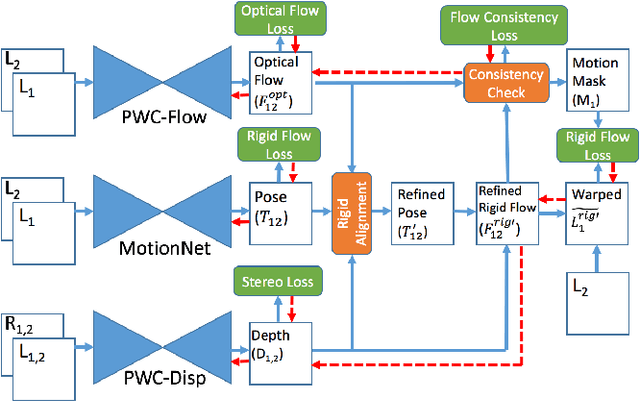
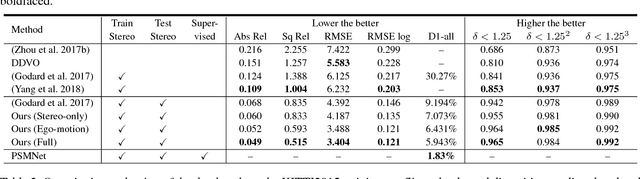
Learning depth and optical flow via deep neural networks by watching videos has made significant progress recently. In this paper, we jointly solve the two tasks by exploiting the underlying geometric rules within stereo videos. Specifically, given two consecutive stereo image pairs from a video, we first estimate depth, camera ego-motion and optical flow from three neural networks. Then the whole scene is decomposed into moving foreground and static background by compar- ing the estimated optical flow and rigid flow derived from the depth and ego-motion. We propose a novel consistency loss to let the optical flow learn from the more accurate rigid flow in static regions. We also design a rigid alignment module which helps refine ego-motion estimation by using the estimated depth and optical flow. Experiments on the KITTI dataset show that our results significantly outperform other state-of- the-art algorithms. Source codes can be found at https: //github.com/baidu-research/UnDepthflow