 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvery Pixel Counts ++: Joint Learning of Geometry and Motion with 3D Holistic Understanding
Paper and Code


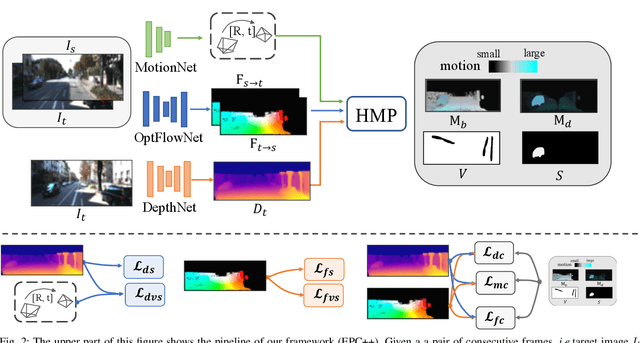
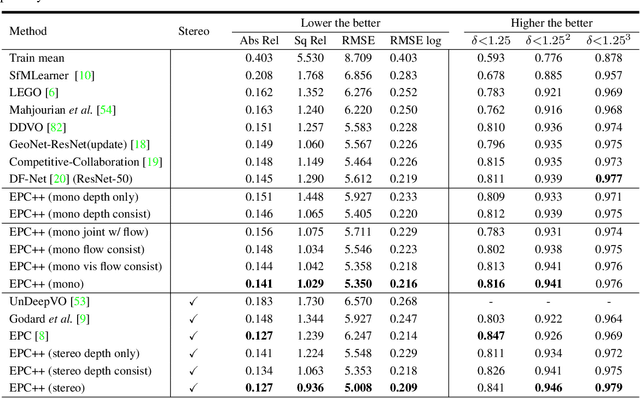
Learning to estimate 3D geometry in a single frame and optical flow from consecutive frames by watching unlabeled videos via deep convolutional network has made significant process recently. Current state-of-the-art (SOTA) methods treat the tasks independently. One important assumption of the current depth estimation pipeline is that the scene contains no moving object, which can be complemented by the optical flow. In this paper, we propose to address the two tasks as a whole, i.e. to jointly understand per-pixel 3D geometry and motion. This also eliminates the need of static scene assumption and enforces the inherent geometrical consistency during the learning process, yielding significantly improved results for both tasks. We call our method as "Every Pixel Counts++" or "EPC++". Specifically, during training, given two consecutive frames from a video, we adopt three parallel networks to predict the camera motion (MotionNet), dense depth map (DepthNet), and per-pixel optical flow between two frames (FlowNet) respectively. Comprehensive experiments were conducted on the KITTI 2012 and KITTI 2015 datasets. Performance on the five tasks of depth estimation, optical flow estimation, odometry, moving object segmentation and scene flow estimation shows that our approach outperforms other SOTA methods, demonstrating the effectiveness of each module of our proposed method.