 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSchedule-and-Calibrate: Utility-Guided Multi-Task Reinforcement Learning for Code LLMs
May 07, 2026Reinforcement learning (RL) with verifiable rewards has proven effective at post-training LLMs for coding, yet deploying separate task-specific specialists incurs costs that scale with the number of tasks, motivating a unified multi-task RL (MTRL) approach. However, existing MTRL methods treat all coding tasks uniformly, relying on fixed data curricula under a shared optimization strategy, ultimately limiting the effectiveness of multi-task training. To address these limitations, we propose ASTOR, a multi-tASk code reinforcement learning framework via uTility-driven coORdination. Centered on task utility, a signal capturing each task learning potential and cross-task synergy, ASTOR comprises two coupled modules: 1) Hierarchical Utility-Routed Data Scheduling module hierarchically allocates training budget and prioritizes informative prompts, steering training toward the most valuable data and 2) Adaptive Utility-Calibrated Policy Optimization module dynamically scales per-task KL regularization, matching update constraints to each tasks current training state. Experiments on two widely-used LLMs across four representative coding tasks demonstrate that ASTOR consistently improves a single model across all tasks, outperforming the best task-specific specialist by 9.0%-9.5% and surpassing the strongest MTRL baseline by 7.5%-12.8%.
OriNet: A Fully Convolutional Network for 3D Human Pose Estimation
Nov 12, 2018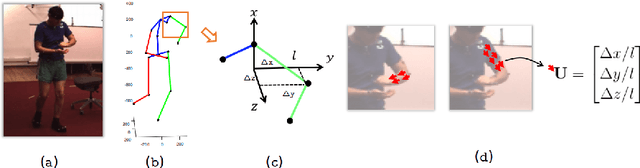
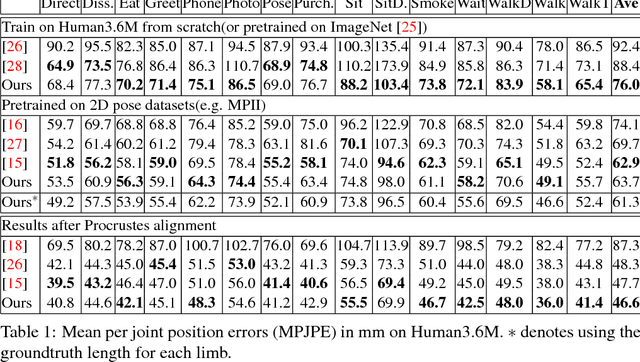
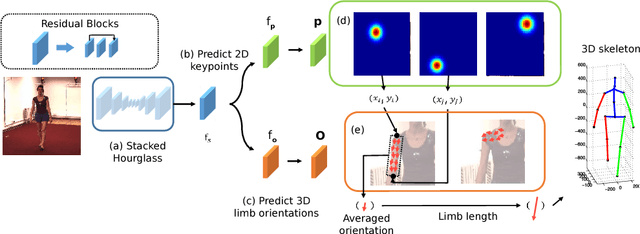
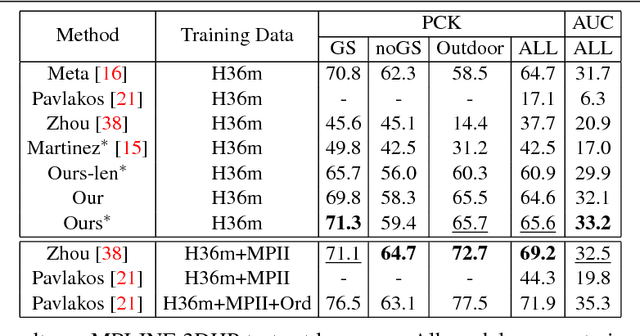
In this paper, we propose a fully convolutional network for 3D human pose estimation from monocular images. We use limb orientations as a new way to represent 3D poses and bind the orientation together with the bounding box of each limb region to better associate images and predictions. The 3D orientations are modeled jointly with 2D keypoint detections. Without additional constraints, this simple method can achieve good results on several large-scale benchmarks. Further experiments show that our method can generalize well to novel scenes and is robust to inaccurate bounding boxes.
* BMVC 2018. Code available at https://github.com/chenxuluo/OriNet-demo
Visual Question Generation as Dual Task of Visual Question Answering
Sep 21, 2017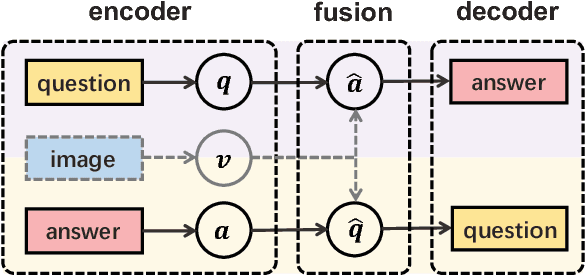
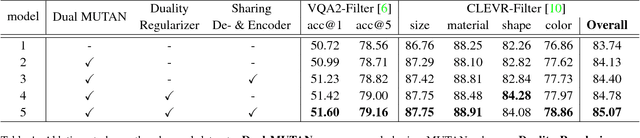
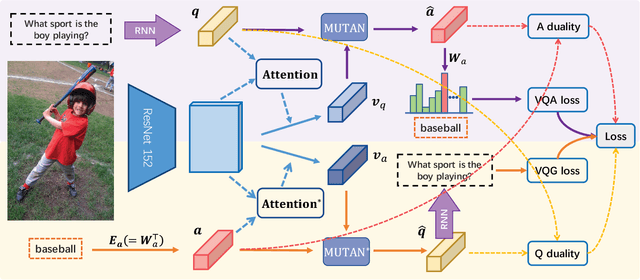
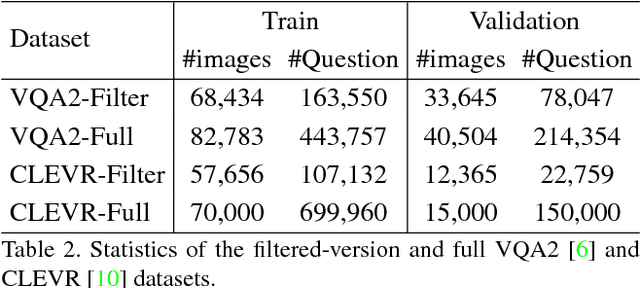
Recently visual question answering (VQA) and visual question generation (VQG) are two trending topics in the computer vision, which have been explored separately. In this work, we propose an end-to-end unified framework, the Invertible Question Answering Network (iQAN), to leverage the complementary relations between questions and answers in images by jointly training the model on VQA and VQG tasks. Corresponding parameter sharing scheme and regular terms are proposed as constraints to explicitly leverage Q,A's dependencies to guide the training process. After training, iQAN can take either question or answer as input, then output the counterpart. Evaluated on the large-scale visual question answering datasets CLEVR and VQA2, our iQAN improves the VQA accuracy over the baselines. We also show the dual learning framework of iQAN can be generalized to other VQA architectures and consistently improve the results over both the VQA and VQG tasks.
Multi-Context Attention for Human Pose Estimation
Feb 24, 2017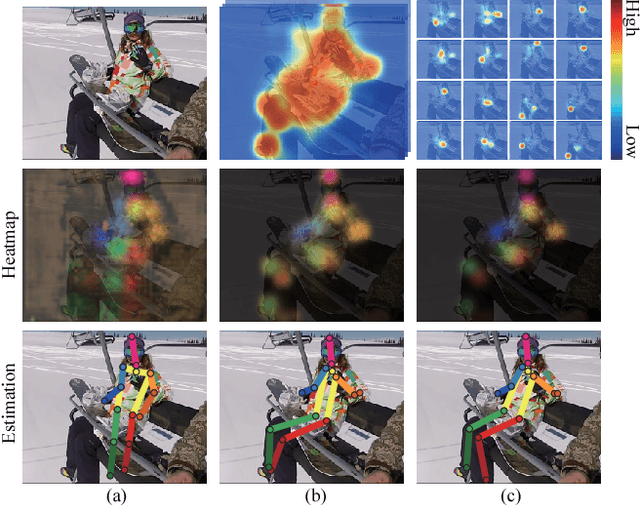
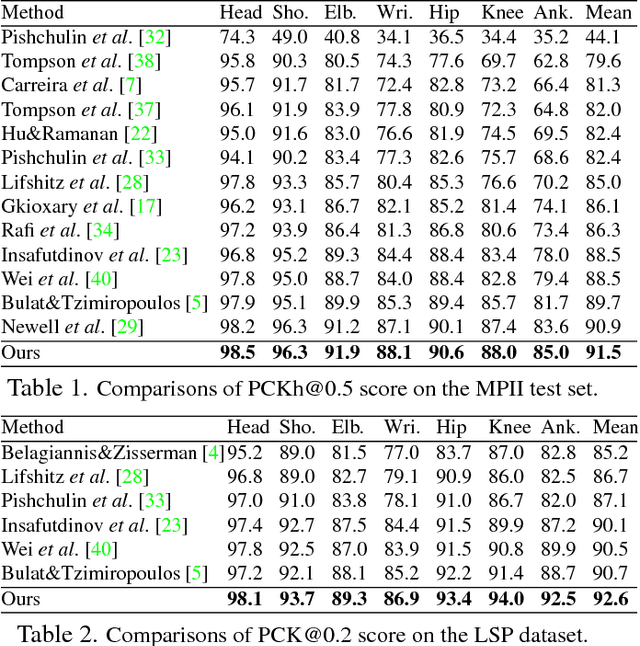
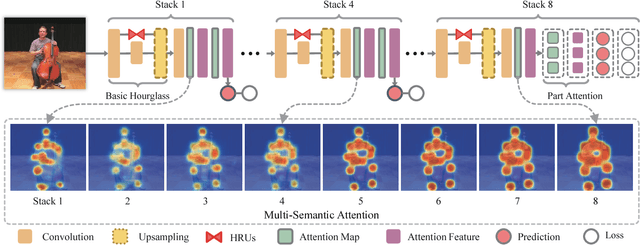
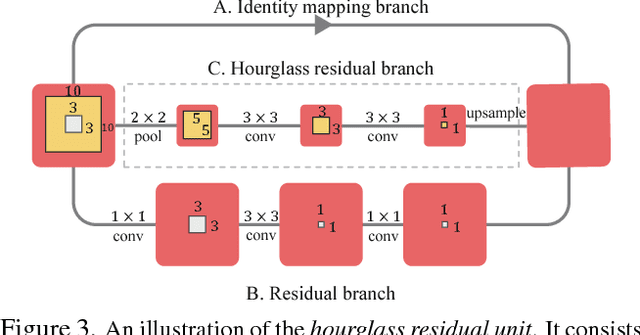
In this paper, we propose to incorporate convolutional neural networks with a multi-context attention mechanism into an end-to-end framework for human pose estimation. We adopt stacked hourglass networks to generate attention maps from features at multiple resolutions with various semantics. The Conditional Random Field (CRF) is utilized to model the correlations among neighboring regions in the attention map. We further combine the holistic attention model, which focuses on the global consistency of the full human body, and the body part attention model, which focuses on the detailed description for different body parts. Hence our model has the ability to focus on different granularity from local salient regions to global semantic-consistent spaces. Additionally, we design novel Hourglass Residual Units (HRUs) to increase the receptive field of the network. These units are extensions of residual units with a side branch incorporating filters with larger receptive fields, hence features with various scales are learned and combined within the HRUs. The effectiveness of the proposed multi-context attention mechanism and the hourglass residual units is evaluated on two widely used human pose estimation benchmarks. Our approach outperforms all existing methods on both benchmarks over all the body parts.
CRF-CNN: Modeling Structured Information in Human Pose Estimation
Nov 02, 2016
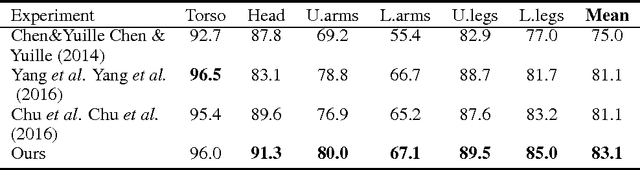

Deep convolutional neural networks (CNN) have achieved great success. On the other hand, modeling structural information has been proved critical in many vision problems. It is of great interest to integrate them effectively. In a classical neural network, there is no message passing between neurons in the same layer. In this paper, we propose a CRF-CNN framework which can simultaneously model structural information in both output and hidden feature layers in a probabilistic way, and it is applied to human pose estimation. A message passing scheme is proposed, so that in various layers each body joint receives messages from all the others in an efficient way. Such message passing can be implemented with convolution between features maps in the same layer, and it is also integrated with feedforward propagation in neural networks. Finally, a neural network implementation of end-to-end learning CRF-CNN is provided. Its effectiveness is demonstrated through experiments on two benchmark datasets.
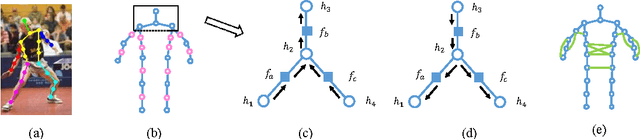
Structured Feature Learning for Pose Estimation
Mar 30, 2016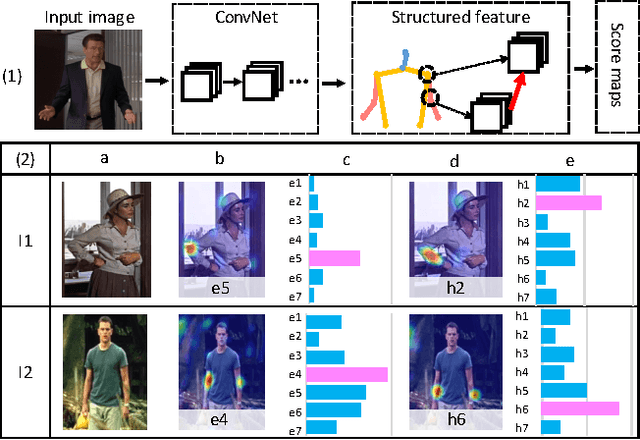
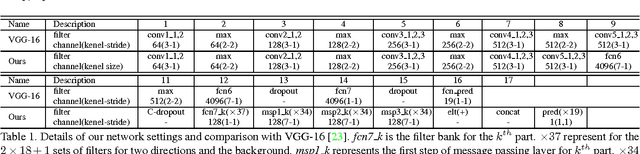

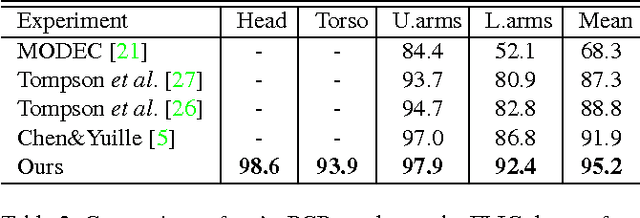
In this paper, we propose a structured feature learning framework to reason the correlations among body joints at the feature level in human pose estimation. Different from existing approaches of modelling structures on score maps or predicted labels, feature maps preserve substantially richer descriptions of body joints. The relationships between feature maps of joints are captured with the introduced geometrical transform kernels, which can be easily implemented with a convolution layer. Features and their relationships are jointly learned in an end-to-end learning system. A bi-directional tree structured model is proposed, so that the feature channels at a body joint can well receive information from other joints. The proposed framework improves feature learning substantially. With very simple post processing, it reaches the best mean PCP on the LSP and FLIC datasets. Compared with the baseline of learning features at each joint separately with ConvNet, the mean PCP has been improved by 18% on FLIC. The code is released to the public.