Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOriNet: A Fully Convolutional Network for 3D Human Pose Estimation
Paper and Code
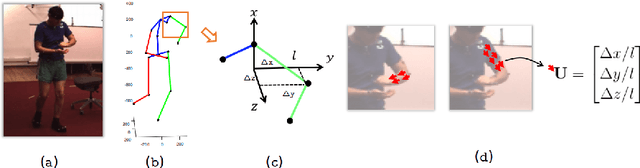
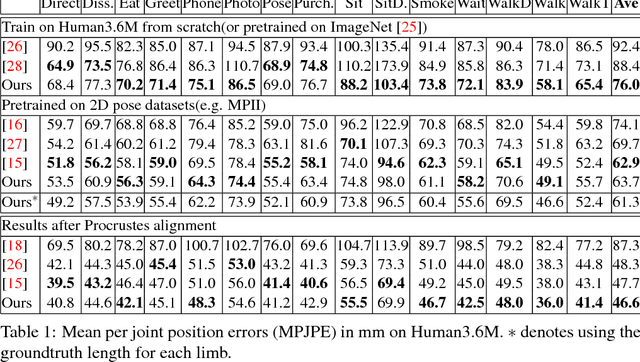
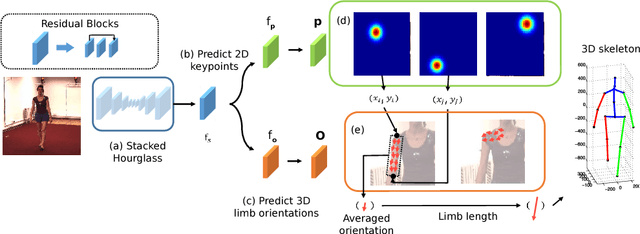
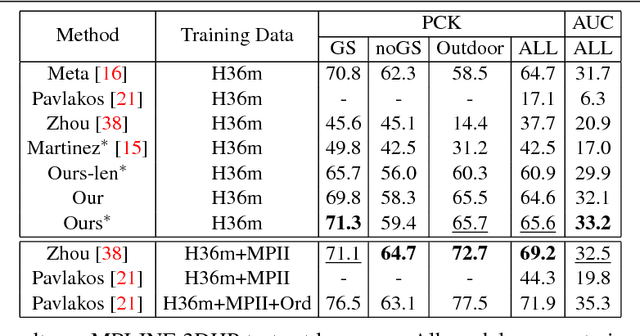
In this paper, we propose a fully convolutional network for 3D human pose estimation from monocular images. We use limb orientations as a new way to represent 3D poses and bind the orientation together with the bounding box of each limb region to better associate images and predictions. The 3D orientations are modeled jointly with 2D keypoint detections. Without additional constraints, this simple method can achieve good results on several large-scale benchmarks. Further experiments show that our method can generalize well to novel scenes and is robust to inaccurate bounding boxes.
* BMVC 2018 - Proceedings of the British Machine Vision Conference
2018 * BMVC 2018. Code available at https://github.com/chenxuluo/OriNet-demo
View paper on