 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Question Generation as Dual Task of Visual Question Answering
Paper and Code
Sep 21, 2017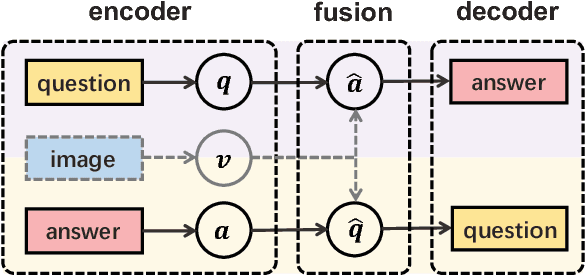
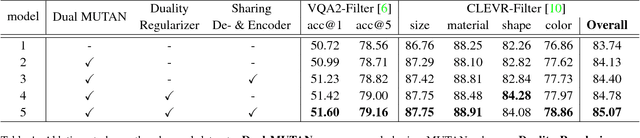
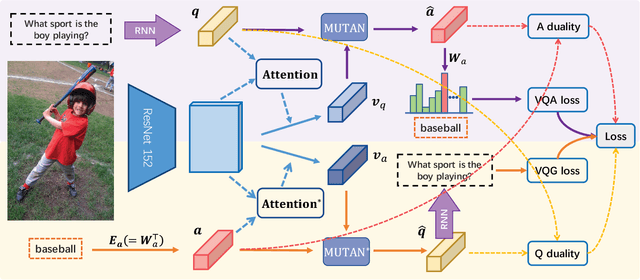
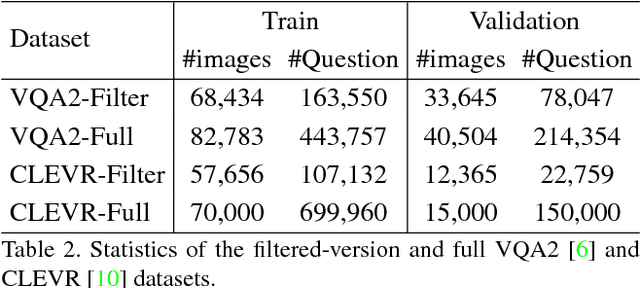
Recently visual question answering (VQA) and visual question generation (VQG) are two trending topics in the computer vision, which have been explored separately. In this work, we propose an end-to-end unified framework, the Invertible Question Answering Network (iQAN), to leverage the complementary relations between questions and answers in images by jointly training the model on VQA and VQG tasks. Corresponding parameter sharing scheme and regular terms are proposed as constraints to explicitly leverage Q,A's dependencies to guide the training process. After training, iQAN can take either question or answer as input, then output the counterpart. Evaluated on the large-scale visual question answering datasets CLEVR and VQA2, our iQAN improves the VQA accuracy over the baselines. We also show the dual learning framework of iQAN can be generalized to other VQA architectures and consistently improve the results over both the VQA and VQG tasks.