 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistillBEV: Boosting Multi-Camera 3D Object Detection with Cross-Modal Knowledge Distillation
Paper and Code
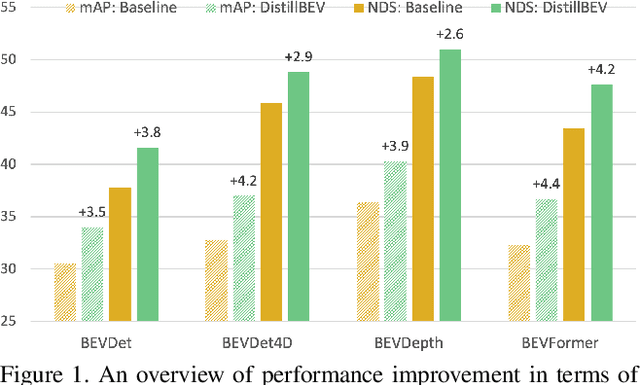
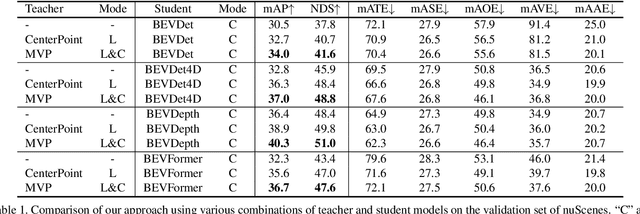
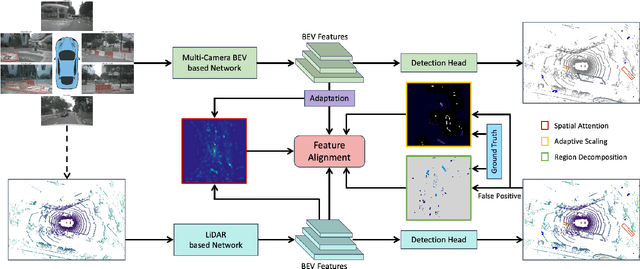
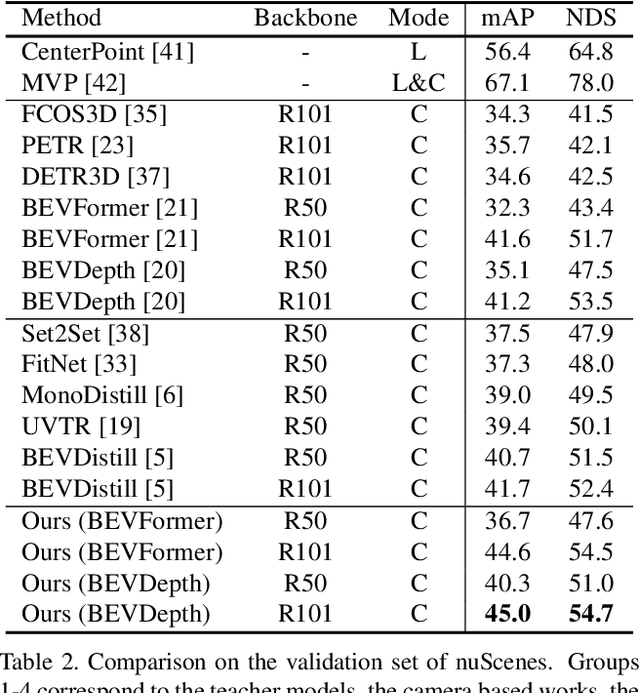
3D perception based on the representations learned from multi-camera bird's-eye-view (BEV) is trending as cameras are cost-effective for mass production in autonomous driving industry. However, there exists a distinct performance gap between multi-camera BEV and LiDAR based 3D object detection. One key reason is that LiDAR captures accurate depth and other geometry measurements, while it is notoriously challenging to infer such 3D information from merely image input. In this work, we propose to boost the representation learning of a multi-camera BEV based student detector by training it to imitate the features of a well-trained LiDAR based teacher detector. We propose effective balancing strategy to enforce the student to focus on learning the crucial features from the teacher, and generalize knowledge transfer to multi-scale layers with temporal fusion. We conduct extensive evaluations on multiple representative models of multi-camera BEV. Experiments reveal that our approach renders significant improvement over the student models, leading to the state-of-the-art performance on the popular benchmark nuScenes.