 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Self-Supervised Learning with Effective Contrastive Units for LiDAR Point Clouds
Paper and Code
Sep 10, 2024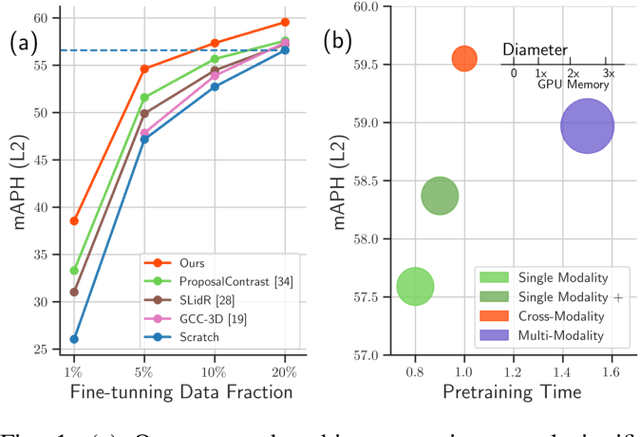
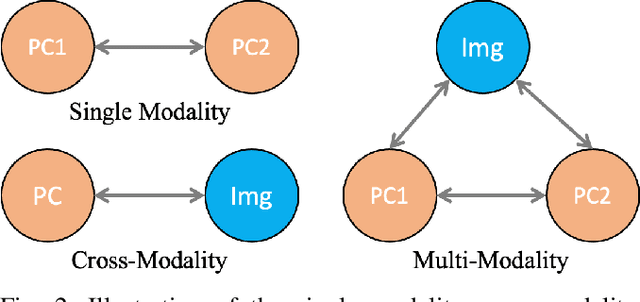
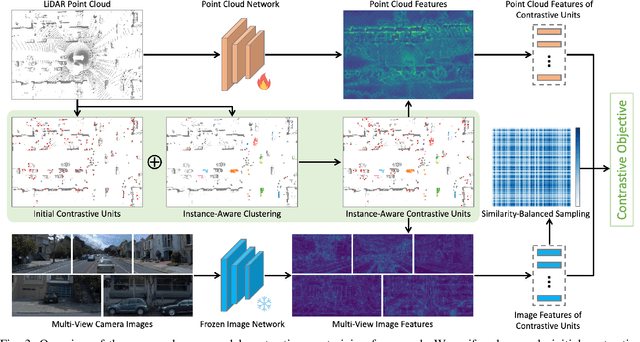

3D perception in LiDAR point clouds is crucial for a self-driving vehicle to properly act in 3D environment. However, manually labeling point clouds is hard and costly. There has been a growing interest in self-supervised pre-training of 3D perception models. Following the success of contrastive learning in images, current methods mostly conduct contrastive pre-training on point clouds only. Yet an autonomous driving vehicle is typically supplied with multiple sensors including cameras and LiDAR. In this context, we systematically study single modality, cross-modality, and multi-modality for contrastive learning of point clouds, and show that cross-modality wins over other alternatives. In addition, considering the huge difference between the training sources in 2D images and 3D point clouds, it remains unclear how to design more effective contrastive units for LiDAR. We therefore propose the instance-aware and similarity-balanced contrastive units that are tailored for self-driving point clouds. Extensive experiments reveal that our approach achieves remarkable performance gains over various point cloud models across the downstream perception tasks of LiDAR based 3D object detection and 3D semantic segmentation on the four popular benchmarks including Waymo Open Dataset, nuScenes, SemanticKITTI and ONCE.