 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric Constraints in Deep Learning Frameworks: A Survey
Mar 19, 2024Stereophotogrammetry is an emerging technique of scene understanding. Its origins go back to at least the 1800s when people first started to investigate using photographs to measure the physical properties of the world. Since then, thousands of approaches have been explored. The classic geometric techniques of Shape from Stereo is built on using geometry to define constraints on scene and camera geometry and then solving the non-linear systems of equations. More recent work has taken an entirely different approach, using end-to-end deep learning without any attempt to explicitly model the geometry. In this survey, we explore the overlap for geometric-based and deep learning-based frameworks. We compare and contrast geometry enforcing constraints integrated into a deep learning framework for depth estimation or other closely related problems. We present a new taxonomy for prevalent geometry enforcing constraints used in modern deep learning frameworks. We also present insightful observations and potential future research directions.
Joint Person Segmentation and Identification in Synchronized First- and Third-person Videos
Jul 25, 2018
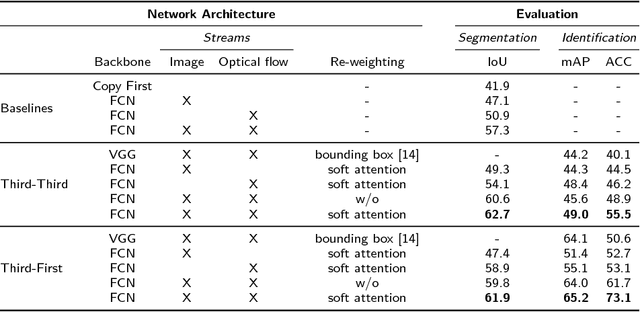
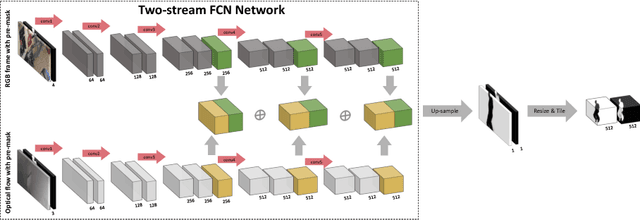
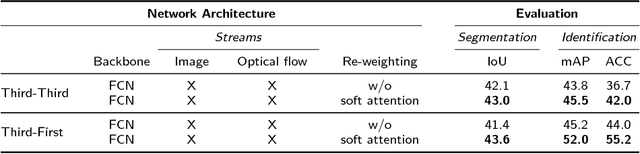
In a world of pervasive cameras, public spaces are often captured from multiple perspectives by cameras of different types, both fixed and mobile. An important problem is to organize these heterogeneous collections of videos by finding connections between them, such as identifying correspondences between the people appearing in the videos and the people holding or wearing the cameras. In this paper, we wish to solve two specific problems: (1) given two or more synchronized third-person videos of a scene, produce a pixel-level segmentation of each visible person and identify corresponding people across different views (i.e., determine who in camera A corresponds with whom in camera B), and (2) given one or more synchronized third-person videos as well as a first-person video taken by a mobile or wearable camera, segment and identify the camera wearer in the third-person videos. Unlike previous work which requires ground truth bounding boxes to estimate the correspondences, we perform person segmentation and identification jointly. We find that solving these two problems simultaneously is mutually beneficial, because better fine-grained segmentation allows us to better perform matching across views, and information from multiple views helps us perform more accurate segmentation. We evaluate our approach on two challenging datasets of interacting people captured from multiple wearable cameras, and show that our proposed method performs significantly better than the state-of-the-art on both person segmentation and identification.
Multi-Task Spatiotemporal Neural Networks for Structured Surface Reconstruction
Jul 20, 2018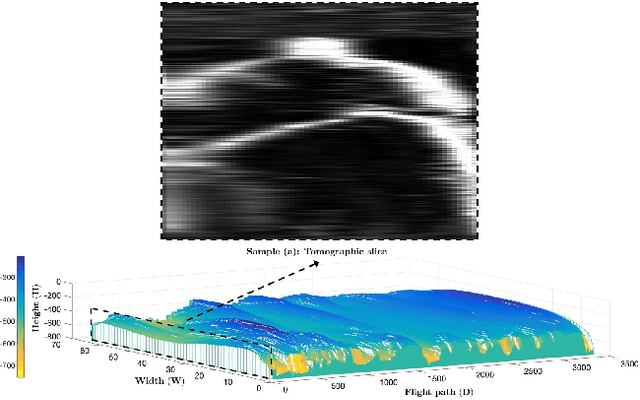

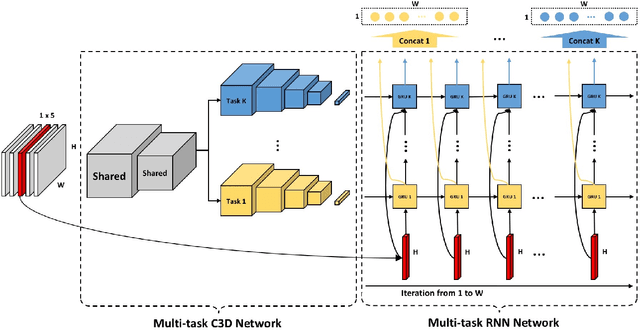
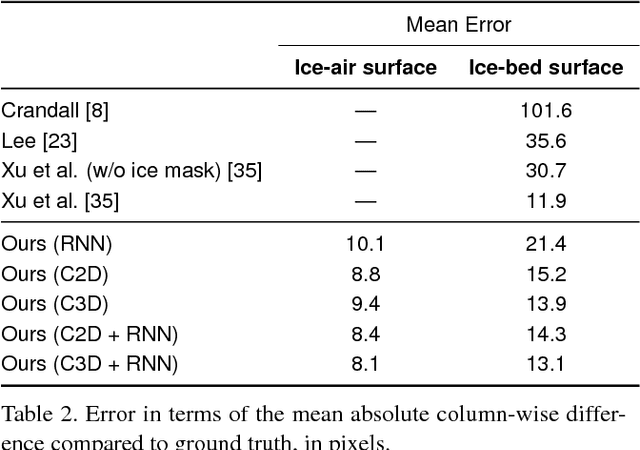
Deep learning methods have surpassed the performance of traditional techniques on a wide range of problems in computer vision, but nearly all of this work has studied consumer photos, where precisely correct output is often not critical. It is less clear how well these techniques may apply on structured prediction problems where fine-grained output with high precision is required, such as in scientific imaging domains. Here we consider the problem of segmenting echogram radar data collected from the polar ice sheets, which is challenging because segmentation boundaries are often very weak and there is a high degree of noise. We propose a multi-task spatiotemporal neural network that combines 3D ConvNets and Recurrent Neural Networks (RNNs) to estimate ice surface boundaries from sequences of tomographic radar images. We show that our model outperforms the state-of-the-art on this problem by (1) avoiding the need for hand-tuned parameters, (2) extracting multiple surfaces (ice-air and ice-bed) simultaneously, (3) requiring less non-visual metadata, and (4) being about 6 times faster.
Fully-Coupled Two-Stream Spatiotemporal Networks for Extremely Low Resolution Action Recognition
Jan 11, 2018

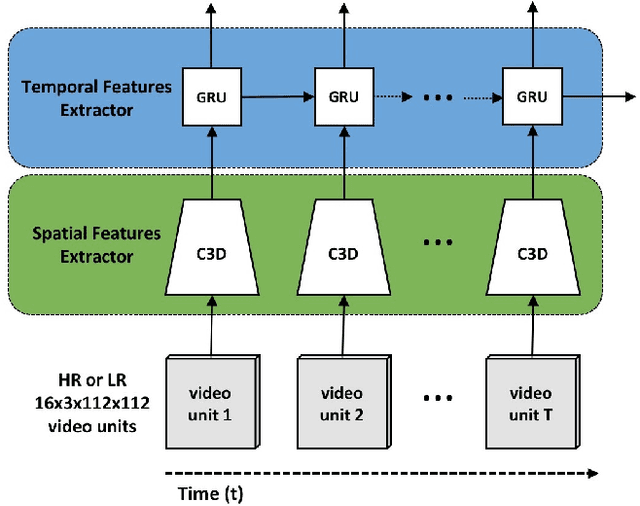

A major emerging challenge is how to protect people's privacy as cameras and computer vision are increasingly integrated into our daily lives, including in smart devices inside homes. A potential solution is to capture and record just the minimum amount of information needed to perform a task of interest. In this paper, we propose a fully-coupled two-stream spatiotemporal architecture for reliable human action recognition on extremely low resolution (e.g., 12x16 pixel) videos. We provide an efficient method to extract spatial and temporal features and to aggregate them into a robust feature representation for an entire action video sequence. We also consider how to incorporate high resolution videos during training in order to build better low resolution action recognition models. We evaluate on two publicly-available datasets, showing significant improvements over the state-of-the-art.
Automatic Estimation of Ice Bottom Surfaces from Radar Imagery
Dec 21, 2017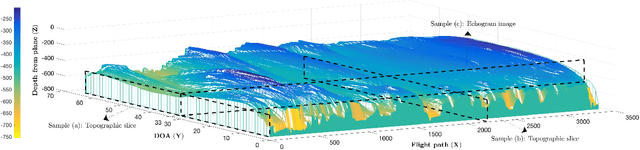
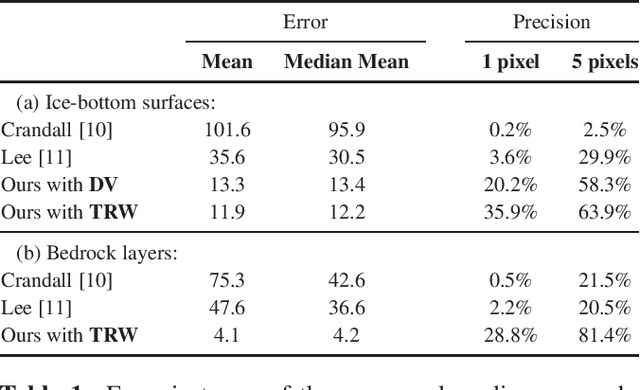
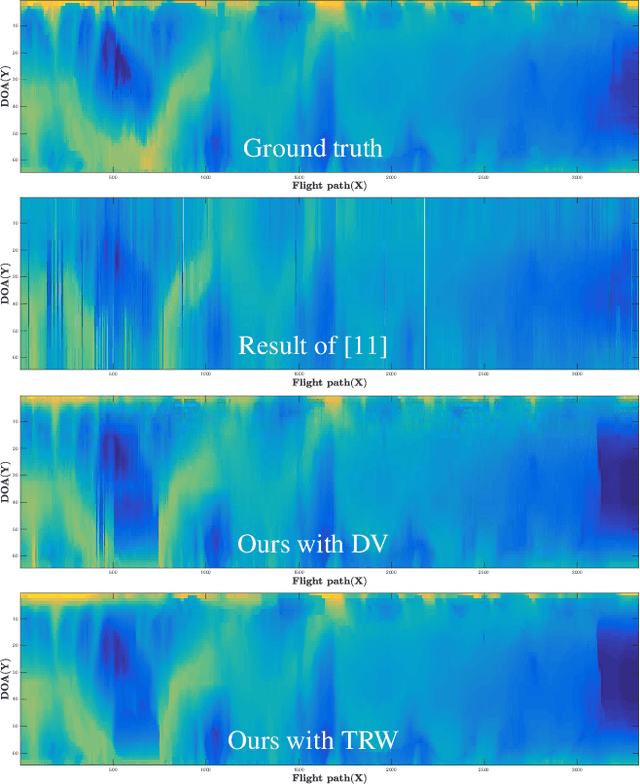
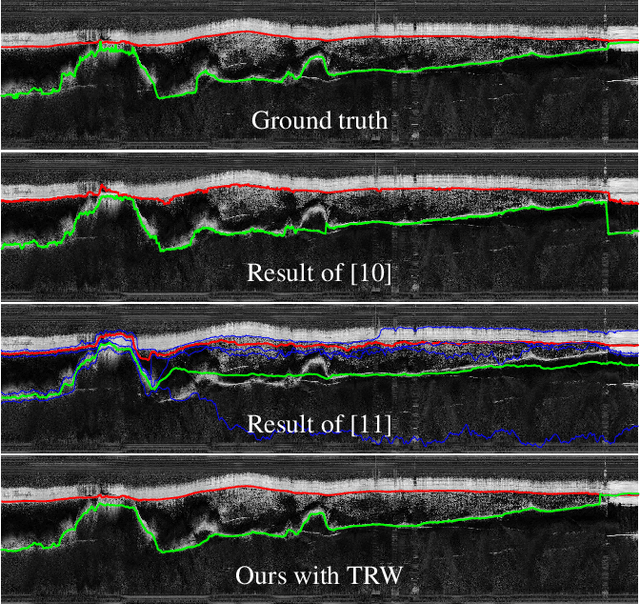
Ground-penetrating radar on planes and satellites now makes it practical to collect 3D observations of the subsurface structure of the polar ice sheets, providing crucial data for understanding and tracking global climate change. But converting these noisy readings into useful observations is generally done by hand, which is impractical at a continental scale. In this paper, we propose a computer vision-based technique for extracting 3D ice-bottom surfaces by viewing the task as an inference problem on a probabilistic graphical model. We first generate a seed surface subject to a set of constraints, and then incorporate additional sources of evidence to refine it via discrete energy minimization. We evaluate the performance of the tracking algorithm on 7 topographic sequences (each with over 3000 radar images) collected from the Canadian Arctic Archipelago with respect to human-labeled ground truth.