 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Naïve Prompting: Strategies for Improved Zero-shot Context-aided Forecasting with LLMs
Aug 13, 2025Forecasting in real-world settings requires models to integrate not only historical data but also relevant contextual information, often available in textual form. While recent work has shown that large language models (LLMs) can be effective context-aided forecasters via na\"ive direct prompting, their full potential remains underexplored. We address this gap with 4 strategies, providing new insights into the zero-shot capabilities of LLMs in this setting. ReDP improves interpretability by eliciting explicit reasoning traces, allowing us to assess the model's reasoning over the context independently from its forecast accuracy. CorDP leverages LLMs solely to refine existing forecasts with context, enhancing their applicability in real-world forecasting pipelines. IC-DP proposes embedding historical examples of context-aided forecasting tasks in the prompt, substantially improving accuracy even for the largest models. Finally, RouteDP optimizes resource efficiency by using LLMs to estimate task difficulty, and routing the most challenging tasks to larger models. Evaluated on different kinds of context-aided forecasting tasks from the CiK benchmark, our strategies demonstrate distinct benefits over na\"ive prompting across LLMs of different sizes and families. These results open the door to further simple yet effective improvements in LLM-based context-aided forecasting.
Context is Key: A Benchmark for Forecasting with Essential Textual Information
Oct 24, 2024



Forecasting is a critical task in decision making across various domains. While numerical data provides a foundation, it often lacks crucial context necessary for accurate predictions. Human forecasters frequently rely on additional information, such as background knowledge or constraints, which can be efficiently communicated through natural language. However, the ability of existing forecasting models to effectively integrate this textual information remains an open question. To address this, we introduce "Context is Key" (CiK), a time series forecasting benchmark that pairs numerical data with diverse types of carefully crafted textual context, requiring models to integrate both modalities. We evaluate a range of approaches, including statistical models, time series foundation models, and LLM-based forecasters, and propose a simple yet effective LLM prompting method that outperforms all other tested methods on our benchmark. Our experiments highlight the importance of incorporating contextual information, demonstrate surprising performance when using LLM-based forecasting models, and also reveal some of their critical shortcomings. By presenting this benchmark, we aim to advance multimodal forecasting, promoting models that are both accurate and accessible to decision-makers with varied technical expertise. The benchmark can be visualized at https://servicenow.github.io/context-is-key-forecasting/v0/ .
XC-Cache: Cross-Attending to Cached Context for Efficient LLM Inference
Apr 23, 2024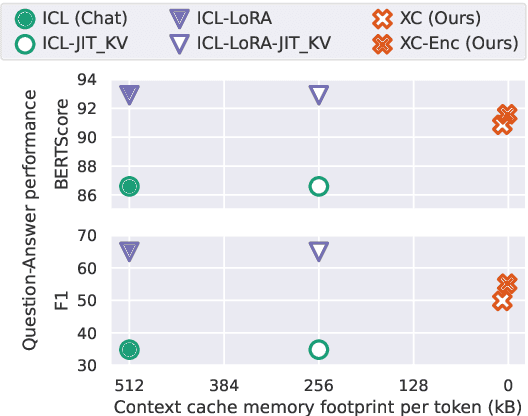
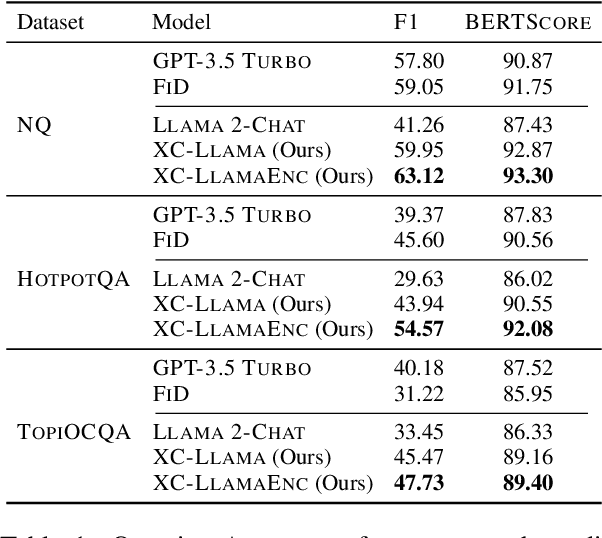
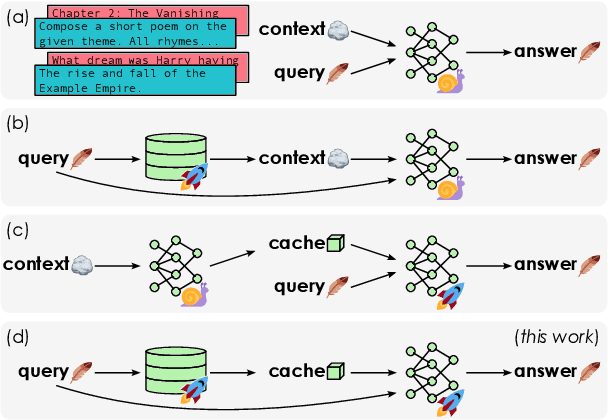
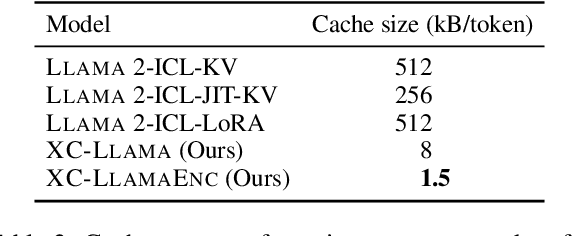
In-context learning (ICL) approaches typically leverage prompting to condition decoder-only language model generation on reference information. Just-in-time processing of a context is inefficient due to the quadratic cost of self-attention operations, and caching is desirable. However, caching transformer states can easily require almost as much space as the model parameters. When the right context isn't known in advance, caching ICL can be challenging. This work addresses these limitations by introducing models that, inspired by the encoder-decoder architecture, use cross-attention to condition generation on reference text without the prompt. More precisely, we leverage pre-trained decoder-only models and only train a small number of added layers. We use Question-Answering (QA) as a testbed to evaluate the ability of our models to perform conditional generation and observe that they outperform ICL, are comparable to fine-tuned prompted LLMs, and drastically reduce the space footprint relative to standard KV caching by two orders of magnitude.
TACTiS-2: Better, Faster, Simpler Attentional Copulas for Multivariate Time Series
Oct 02, 2023



We introduce a new model for multivariate probabilistic time series prediction, designed to flexibly address a range of tasks including forecasting, interpolation, and their combinations. Building on copula theory, we propose a simplified objective for the recently-introduced transformer-based attentional copulas (TACTiS), wherein the number of distributional parameters now scales linearly with the number of variables instead of factorially. The new objective requires the introduction of a training curriculum, which goes hand-in-hand with necessary changes to the original architecture. We show that the resulting model has significantly better training dynamics and achieves state-of-the-art performance across diverse real-world forecasting tasks, while maintaining the flexibility of prior work, such as seamless handling of unaligned and unevenly-sampled time series.
Regions of Reliability in the Evaluation of Multivariate Probabilistic Forecasts
Apr 19, 2023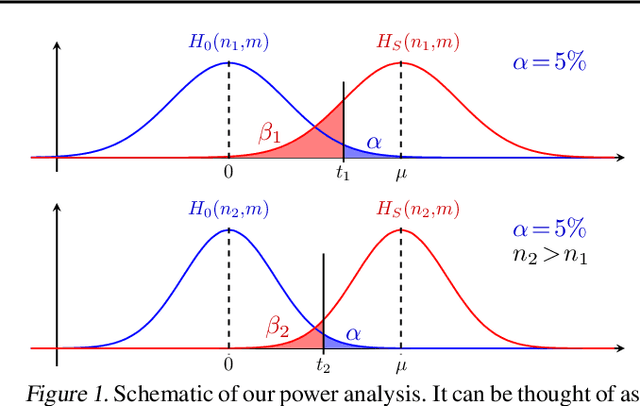


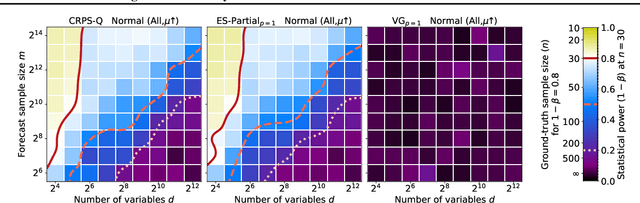
Multivariate probabilistic time series forecasts are commonly evaluated via proper scoring rules, i.e., functions that are minimal in expectation for the ground-truth distribution. However, this property is not sufficient to guarantee good discrimination in the non-asymptotic regime. In this paper, we provide the first systematic finite-sample study of proper scoring rules for time-series forecasting evaluation. Through a power analysis, we identify the "region of reliability" of a scoring rule, i.e., the set of practical conditions where it can be relied on to identify forecasting errors. We carry out our analysis on a comprehensive synthetic benchmark, specifically designed to test several key discrepancies between ground-truth and forecast distributions, and we gauge the generalizability of our findings to real-world tasks with an application to an electricity production problem. Our results reveal critical shortcomings in the evaluation of multivariate probabilistic forecasts as commonly performed in the literature.
TACTiS: Transformer-Attentional Copulas for Time Series
Feb 07, 2022
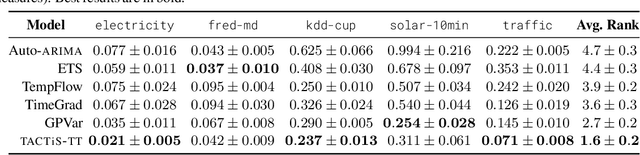

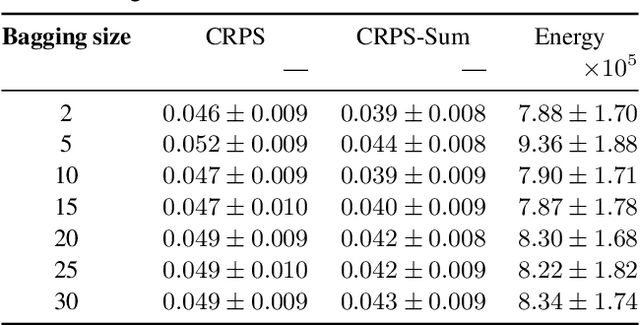
The estimation of time-varying quantities is a fundamental component of decision making in fields such as healthcare and finance. However, the practical utility of such estimates is limited by how accurately they quantify predictive uncertainty. In this work, we address the problem of estimating the joint predictive distribution of high-dimensional multivariate time series. We propose a versatile method, based on the transformer architecture, that estimates joint distributions using an attention-based decoder that provably learns to mimic the properties of non-parametric copulas. The resulting model has several desirable properties: it can scale to hundreds of time series, supports both forecasting and interpolation, can handle unaligned and non-uniformly sampled data, and can seamlessly adapt to missing data during training. We demonstrate these properties empirically and show that our model produces state-of-the-art predictions on several real-world datasets.