 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoLT: Joint Probabilistic Predictions on Tabular Data Using LLMs
Feb 17, 2025We introduce a simple method for probabilistic predictions on tabular data based on Large Language Models (LLMs) called JoLT (Joint LLM Process for Tabular data). JoLT uses the in-context learning capabilities of LLMs to define joint distributions over tabular data conditioned on user-specified side information about the problem, exploiting the vast repository of latent problem-relevant knowledge encoded in LLMs. JoLT defines joint distributions for multiple target variables with potentially heterogeneous data types without any data conversion, data preprocessing, special handling of missing data, or model training, making it accessible and efficient for practitioners. Our experiments show that JoLT outperforms competitive methods on low-shot single-target and multi-target tabular classification and regression tasks. Furthermore, we show that JoLT can automatically handle missing data and perform data imputation by leveraging textual side information. We argue that due to its simplicity and generality, JoLT is an effective approach for a wide variety of real prediction problems.
A Meta-Learning Approach to Bayesian Causal Discovery
Dec 21, 2024



Discovering a unique causal structure is difficult due to both inherent identifiability issues, and the consequences of finite data. As such, uncertainty over causal structures, such as those obtained from a Bayesian posterior, are often necessary for downstream tasks. Finding an accurate approximation to this posterior is challenging, due to the large number of possible causal graphs, as well as the difficulty in the subproblem of finding posteriors over the functional relationships of the causal edges. Recent works have used meta-learning to view the problem of estimating the maximum a-posteriori causal graph as supervised learning. Yet, these methods are limited when estimating the full posterior as they fail to encode key properties of the posterior, such as correlation between edges and permutation equivariance with respect to nodes. Further, these methods also cannot reliably sample from the posterior over causal structures. To address these limitations, we propose a Bayesian meta learning model that allows for sampling causal structures from the posterior and encodes these key properties. We compare our meta-Bayesian causal discovery against existing Bayesian causal discovery methods, demonstrating the advantages of directly learning a posterior over causal structure.
Context is Key: A Benchmark for Forecasting with Essential Textual Information
Oct 24, 2024



Forecasting is a critical task in decision making across various domains. While numerical data provides a foundation, it often lacks crucial context necessary for accurate predictions. Human forecasters frequently rely on additional information, such as background knowledge or constraints, which can be efficiently communicated through natural language. However, the ability of existing forecasting models to effectively integrate this textual information remains an open question. To address this, we introduce "Context is Key" (CiK), a time series forecasting benchmark that pairs numerical data with diverse types of carefully crafted textual context, requiring models to integrate both modalities. We evaluate a range of approaches, including statistical models, time series foundation models, and LLM-based forecasters, and propose a simple yet effective LLM prompting method that outperforms all other tested methods on our benchmark. Our experiments highlight the importance of incorporating contextual information, demonstrate surprising performance when using LLM-based forecasting models, and also reveal some of their critical shortcomings. By presenting this benchmark, we aim to advance multimodal forecasting, promoting models that are both accurate and accessible to decision-makers with varied technical expertise. The benchmark can be visualized at https://servicenow.github.io/context-is-key-forecasting/v0/ .
AI for operational methane emitter monitoring from space
Aug 08, 2024Mitigating methane emissions is the fastest way to stop global warming in the short-term and buy humanity time to decarbonise. Despite the demonstrated ability of remote sensing instruments to detect methane plumes, no system has been available to routinely monitor and act on these events. We present MARS-S2L, an automated AI-driven methane emitter monitoring system for Sentinel-2 and Landsat satellite imagery deployed operationally at the United Nations Environment Programme's International Methane Emissions Observatory. We compile a global dataset of thousands of super-emission events for training and evaluation, demonstrating that MARS-S2L can skillfully monitor emissions in a diverse range of regions globally, providing a 216% improvement in mean average precision over a current state-of-the-art detection method. Running this system operationally for six months has yielded 457 near-real-time detections in 22 different countries of which 62 have already been used to provide formal notifications to governments and stakeholders.
Translation Equivariant Transformer Neural Processes
Jun 18, 2024
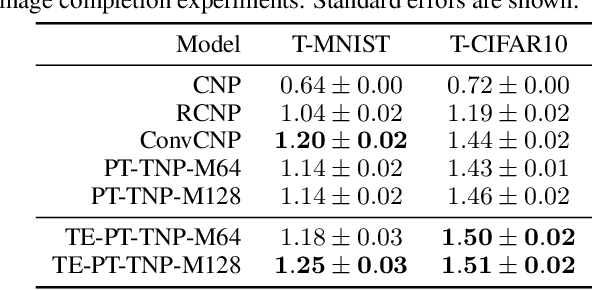


The effectiveness of neural processes (NPs) in modelling posterior prediction maps -- the mapping from data to posterior predictive distributions -- has significantly improved since their inception. This improvement can be attributed to two principal factors: (1) advancements in the architecture of permutation invariant set functions, which are intrinsic to all NPs; and (2) leveraging symmetries present in the true posterior predictive map, which are problem dependent. Transformers are a notable development in permutation invariant set functions, and their utility within NPs has been demonstrated through the family of models we refer to as TNPs. Despite significant interest in TNPs, little attention has been given to incorporating symmetries. Notably, the posterior prediction maps for data that are stationary -- a common assumption in spatio-temporal modelling -- exhibit translation equivariance. In this paper, we introduce of a new family of translation equivariant TNPs that incorporate translation equivariance. Through an extensive range of experiments on synthetic and real-world spatio-temporal data, we demonstrate the effectiveness of TE-TNPs relative to their non-translation-equivariant counterparts and other NP baselines.
LLM Processes: Numerical Predictive Distributions Conditioned on Natural Language
May 21, 2024



Machine learning practitioners often face significant challenges in formally integrating their prior knowledge and beliefs into predictive models, limiting the potential for nuanced and context-aware analyses. Moreover, the expertise needed to integrate this prior knowledge into probabilistic modeling typically limits the application of these models to specialists. Our goal is to build a regression model that can process numerical data and make probabilistic predictions at arbitrary locations, guided by natural language text which describes a user's prior knowledge. Large Language Models (LLMs) provide a useful starting point for designing such a tool since they 1) provide an interface where users can incorporate expert insights in natural language and 2) provide an opportunity for leveraging latent problem-relevant knowledge encoded in LLMs that users may not have themselves. We start by exploring strategies for eliciting explicit, coherent numerical predictive distributions from LLMs. We examine these joint predictive distributions, which we call LLM Processes, over arbitrarily-many quantities in settings such as forecasting, multi-dimensional regression, black-box optimization, and image modeling. We investigate the practical details of prompting to elicit coherent predictive distributions, and demonstrate their effectiveness at regression. Finally, we demonstrate the ability to usefully incorporate text into numerical predictions, improving predictive performance and giving quantitative structure that reflects qualitative descriptions. This lets us begin to explore the rich, grounded hypothesis space that LLMs implicitly encode.
Aardvark Weather: end-to-end data-driven weather forecasting
Mar 30, 2024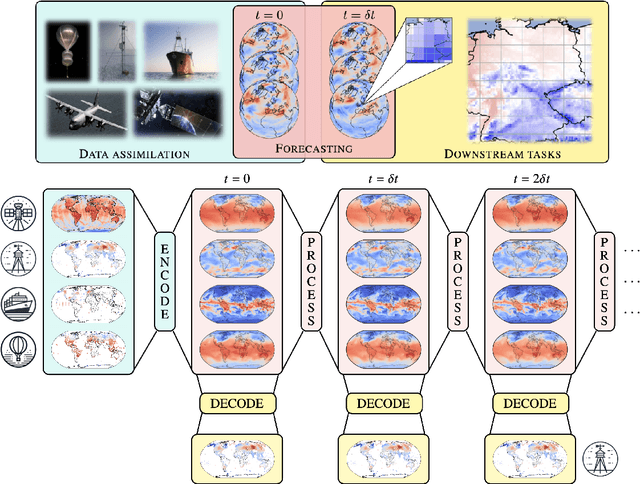
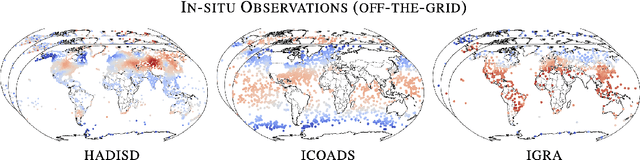
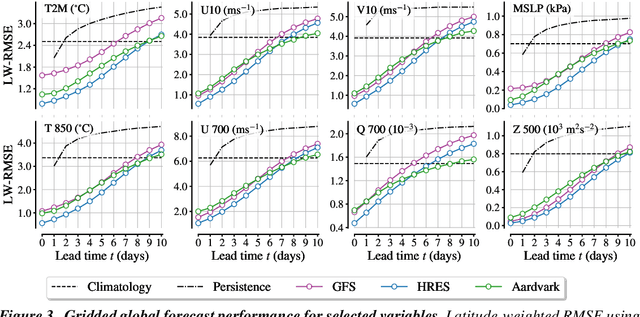
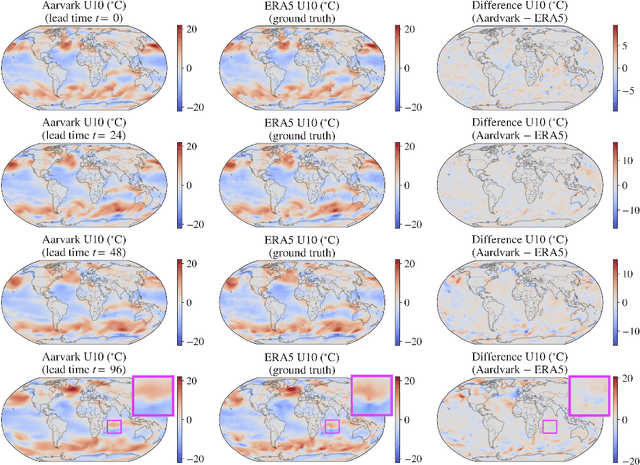
Machine learning is revolutionising medium-range weather prediction. However it has only been applied to specific and individual components of the weather prediction pipeline. Consequently these data-driven approaches are unable to be deployed without input from conventional operational numerical weather prediction (NWP) systems, which is computationally costly and does not support end-to-end optimisation. In this work, we take a radically different approach and replace the entire NWP pipeline with a machine learning model. We present Aardvark Weather, the first end-to-end data-driven forecasting system which takes raw observations as input and provides both global and local forecasts. These global forecasts are produced for 24 variables at multiple pressure levels at one-degree spatial resolution and 24 hour temporal resolution, and are skillful with respect to hourly climatology at five to seven day lead times. Local forecasts are produced for temperature, mean sea level pressure, and wind speed at a geographically diverse set of weather stations, and are skillful with respect to an IFS-HRES interpolation baseline at multiple lead-times. Aardvark, by virtue of its simplicity and scalability, opens the door to a new paradigm for performing accurate and efficient data-driven medium-range weather forecasting.
Diffusion-Augmented Neural Processes
Nov 16, 2023Over the last few years, Neural Processes have become a useful modelling tool in many application areas, such as healthcare and climate sciences, in which data are scarce and prediction uncertainty estimates are indispensable. However, the current state of the art in the field (AR CNPs; Bruinsma et al., 2023) presents a few issues that prevent its widespread deployment. This work proposes an alternative, diffusion-based approach to NPs which, through conditioning on noised datasets, addresses many of these limitations, whilst also exceeding SOTA performance.
Sim2Real for Environmental Neural Processes
Oct 30, 2023
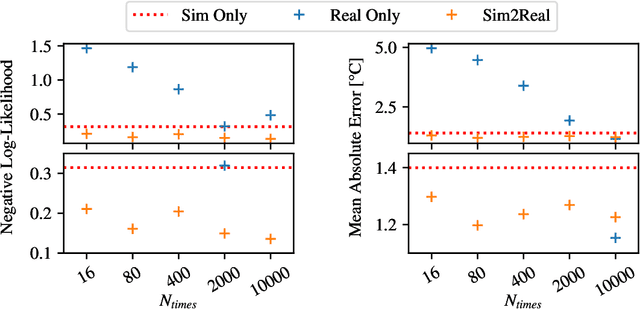

Machine learning (ML)-based weather models have recently undergone rapid improvements. These models are typically trained on gridded reanalysis data from numerical data assimilation systems. However, reanalysis data comes with limitations, such as assumptions about physical laws and low spatiotemporal resolution. The gap between reanalysis and reality has sparked growing interest in training ML models directly on observations such as weather stations. Modelling scattered and sparse environmental observations requires scalable and flexible ML architectures, one of which is the convolutional conditional neural process (ConvCNP). ConvCNPs can learn to condition on both gridded and off-the-grid context data to make uncertainty-aware predictions at target locations. However, the sparsity of real observations presents a challenge for data-hungry deep learning models like the ConvCNP. One potential solution is 'Sim2Real': pre-training on reanalysis and fine-tuning on observational data. We analyse Sim2Real with a ConvCNP trained to interpolate surface air temperature over Germany, using varying numbers of weather stations for fine-tuning. On held-out weather stations, Sim2Real training substantially outperforms the same model architecture trained only with reanalysis data or only with station data, showing that reanalysis data can serve as a stepping stone for learning from real observations. Sim2Real could thus enable more accurate models for weather prediction and climate monitoring.
Active Learning with Convolutional Gaussian Neural Processes for Environmental Sensor Placement
Nov 22, 2022Deploying environmental measurement stations can be a costly and time-consuming procedure, especially in remote regions that are difficult to access, such as Antarctica. Therefore, it is crucial that sensors are placed as efficiently as possible, maximising the informativeness of their measurements. This can be tackled by fitting a probabilistic model to existing data and identifying placements that would maximally reduce the model's uncertainty. The models most widely used for this purpose are Gaussian processes (GPs). However, designing a GP covariance which captures the complex behaviour of non-stationary spatiotemporal data is a difficult task. Further, the computational cost of GPs makes them challenging to scale to large environmental datasets. In this work, we explore using a convolutional Gaussian neural process (ConvGNP) to address these issues. A ConvGNP is a meta-learning model that uses neural networks to parameterise a GP predictive. Our model is data-driven, flexible, efficient, and permits multiple input predictors of gridded or scattered modalities. Using simulated surface air temperature fields over Antarctica as ground truth, we show that a ConvGNP significantly outperforms a non-stationary GP baseline in terms of predictive performance. We then use the ConvGNP in an Antarctic sensor placement toy experiment, yielding promising results.