 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslation Equivariant Transformer Neural Processes
Paper and Code
Jun 18, 2024
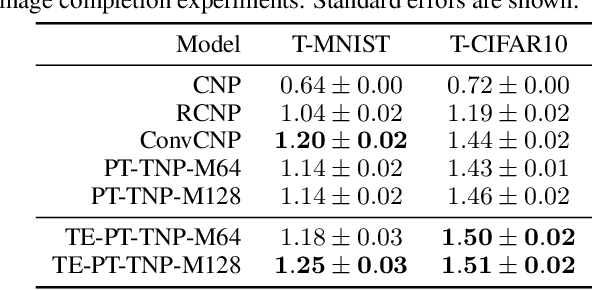


The effectiveness of neural processes (NPs) in modelling posterior prediction maps -- the mapping from data to posterior predictive distributions -- has significantly improved since their inception. This improvement can be attributed to two principal factors: (1) advancements in the architecture of permutation invariant set functions, which are intrinsic to all NPs; and (2) leveraging symmetries present in the true posterior predictive map, which are problem dependent. Transformers are a notable development in permutation invariant set functions, and their utility within NPs has been demonstrated through the family of models we refer to as TNPs. Despite significant interest in TNPs, little attention has been given to incorporating symmetries. Notably, the posterior prediction maps for data that are stationary -- a common assumption in spatio-temporal modelling -- exhibit translation equivariance. In this paper, we introduce of a new family of translation equivariant TNPs that incorporate translation equivariance. Through an extensive range of experiments on synthetic and real-world spatio-temporal data, we demonstrate the effectiveness of TE-TNPs relative to their non-translation-equivariant counterparts and other NP baselines.