 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAardvark Weather: end-to-end data-driven weather forecasting
Mar 30, 2024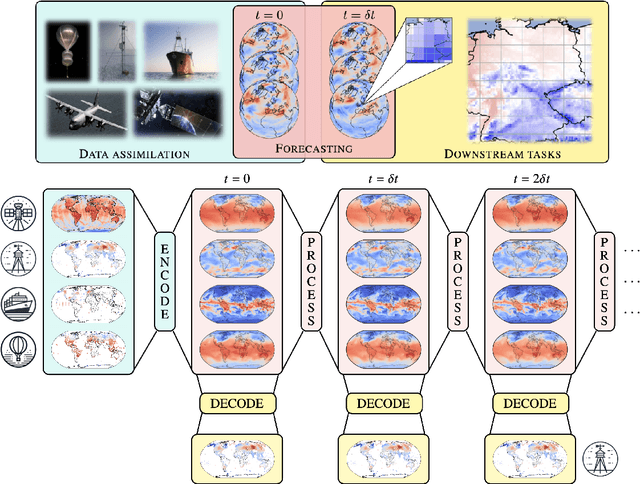
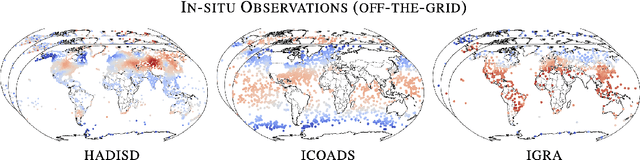
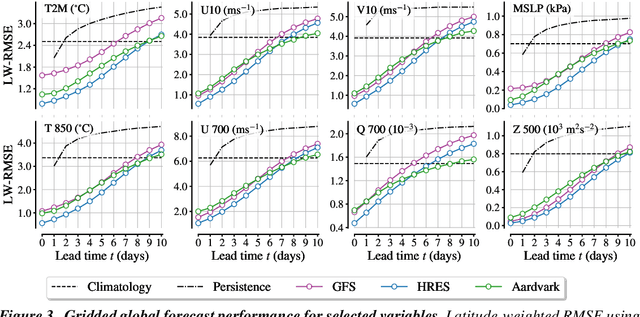
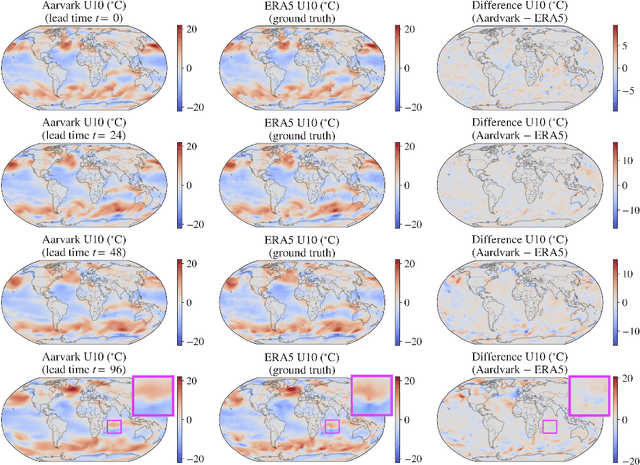
Machine learning is revolutionising medium-range weather prediction. However it has only been applied to specific and individual components of the weather prediction pipeline. Consequently these data-driven approaches are unable to be deployed without input from conventional operational numerical weather prediction (NWP) systems, which is computationally costly and does not support end-to-end optimisation. In this work, we take a radically different approach and replace the entire NWP pipeline with a machine learning model. We present Aardvark Weather, the first end-to-end data-driven forecasting system which takes raw observations as input and provides both global and local forecasts. These global forecasts are produced for 24 variables at multiple pressure levels at one-degree spatial resolution and 24 hour temporal resolution, and are skillful with respect to hourly climatology at five to seven day lead times. Local forecasts are produced for temperature, mean sea level pressure, and wind speed at a geographically diverse set of weather stations, and are skillful with respect to an IFS-HRES interpolation baseline at multiple lead-times. Aardvark, by virtue of its simplicity and scalability, opens the door to a new paradigm for performing accurate and efficient data-driven medium-range weather forecasting.
CLAD: A Contrastive Learning based Approach for Background Debiasing
Oct 06, 2022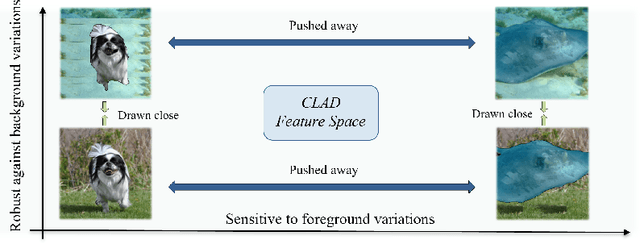


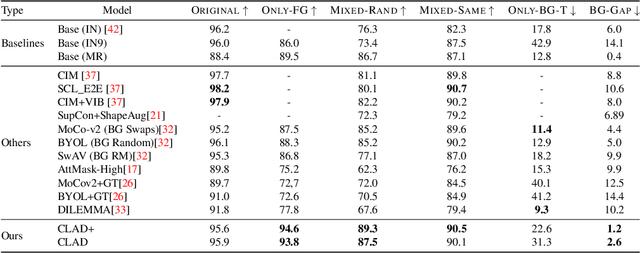
Convolutional neural networks (CNNs) have achieved superhuman performance in multiple vision tasks, especially image classification. However, unlike humans, CNNs leverage spurious features, such as background information to make decisions. This tendency creates different problems in terms of robustness or weak generalization performance. Through our work, we introduce a contrastive learning-based approach (CLAD) to mitigate the background bias in CNNs. CLAD encourages semantic focus on object foregrounds and penalizes learning features from irrelavant backgrounds. Our method also introduces an efficient way of sampling negative samples. We achieve state-of-the-art results on the Background Challenge dataset, outperforming the previous benchmark with a margin of 4.1\%. Our paper shows how CLAD serves as a proof of concept for debiasing of spurious features, such as background and texture (in supplementary material).