 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency-Based Vulnerability Analysis of Deep Learning Models against Image Corruptions
Jun 12, 2023Deep learning models often face challenges when handling real-world image corruptions. In response, researchers have developed image corruption datasets to evaluate the performance of deep neural networks in handling such corruptions. However, these datasets have a significant limitation: they do not account for all corruptions encountered in real-life scenarios. To address this gap, we present MUFIA (Multiplicative Filter Attack), an algorithm designed to identify the specific types of corruptions that can cause models to fail. Our algorithm identifies the combination of image frequency components that render a model susceptible to misclassification while preserving the semantic similarity to the original image. We find that even state-of-the-art models trained to be robust against known common corruptions struggle against the low visibility-based corruptions crafted by MUFIA. This highlights the need for more comprehensive approaches to enhance model robustness against a wider range of real-world image corruptions.
CLAD: A Contrastive Learning based Approach for Background Debiasing
Oct 06, 2022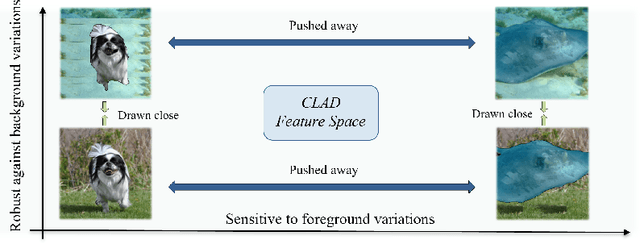


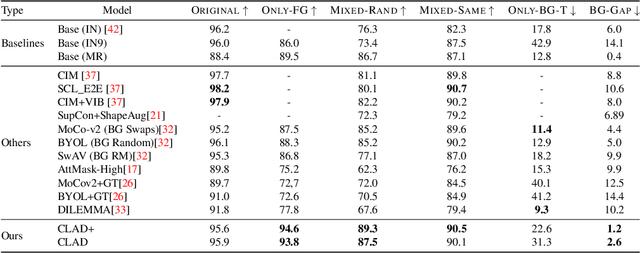
Convolutional neural networks (CNNs) have achieved superhuman performance in multiple vision tasks, especially image classification. However, unlike humans, CNNs leverage spurious features, such as background information to make decisions. This tendency creates different problems in terms of robustness or weak generalization performance. Through our work, we introduce a contrastive learning-based approach (CLAD) to mitigate the background bias in CNNs. CLAD encourages semantic focus on object foregrounds and penalizes learning features from irrelavant backgrounds. Our method also introduces an efficient way of sampling negative samples. We achieve state-of-the-art results on the Background Challenge dataset, outperforming the previous benchmark with a margin of 4.1\%. Our paper shows how CLAD serves as a proof of concept for debiasing of spurious features, such as background and texture (in supplementary material).
A comment on Guo et al. [arXiv:2206.11228]
Aug 02, 2022In a recent article, Guo et al. [arXiv:2206.11228] report that adversarially trained neural representations in deep networks may already be as robust as corresponding primate IT neural representations. While we find the paper's primary experiment illuminating, we have doubts about the interpretation and phrasing of the results presented in the paper.
Empirical Advocacy of Bio-inspired Models for Robust Image Recognition
May 18, 2022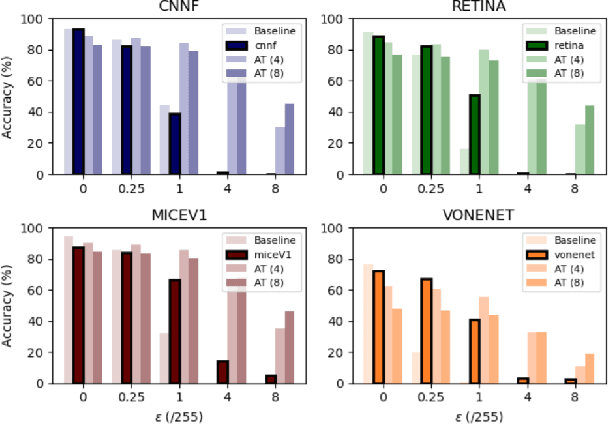
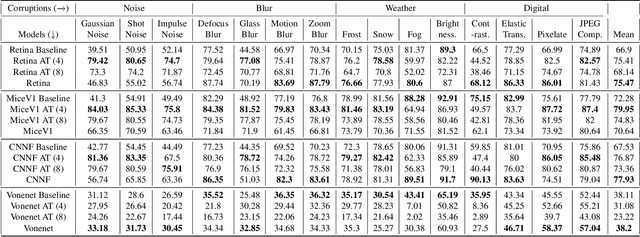
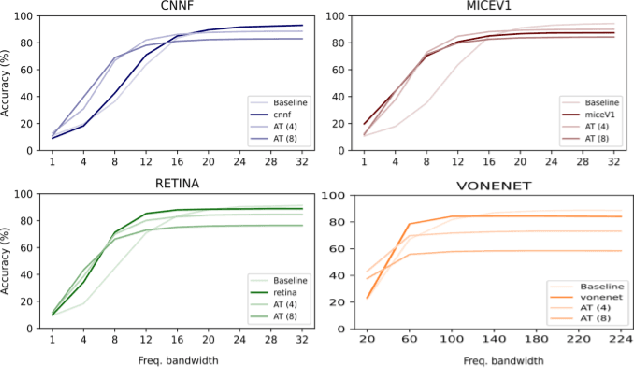
Deep convolutional neural networks (DCNNs) have revolutionized computer vision and are often advocated as good models of the human visual system. However, there are currently many shortcomings of DCNNs, which preclude them as a model of human vision. There are continuous attempts to use features of the human visual system to improve the robustness of neural networks to data perturbations. We provide a detailed analysis of such bio-inspired models and their properties. To this end, we benchmark the robustness of several bio-inspired models against their most comparable baseline DCNN models. We find that bio-inspired models tend to be adversarially robust without requiring any special data augmentation. Additionally, we find that bio-inspired models beat adversarially trained models in the presence of more real-world common corruptions. Interestingly, we also find that bio-inspired models tend to use both low and mid-frequency information, in contrast to other DCNN models. We find that this mix of frequency information makes them robust to both adversarial perturbations and common corruptions.
Bio-inspired Robustness: A Review
Mar 16, 2021
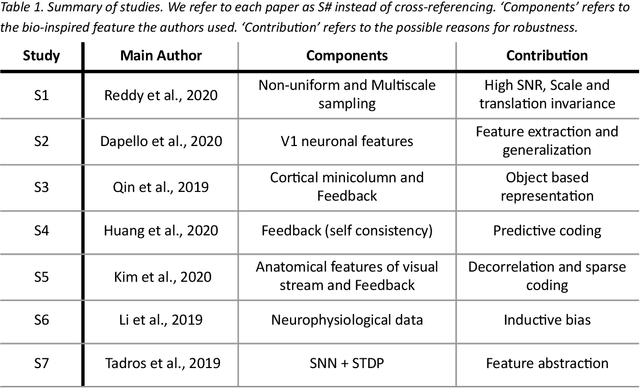
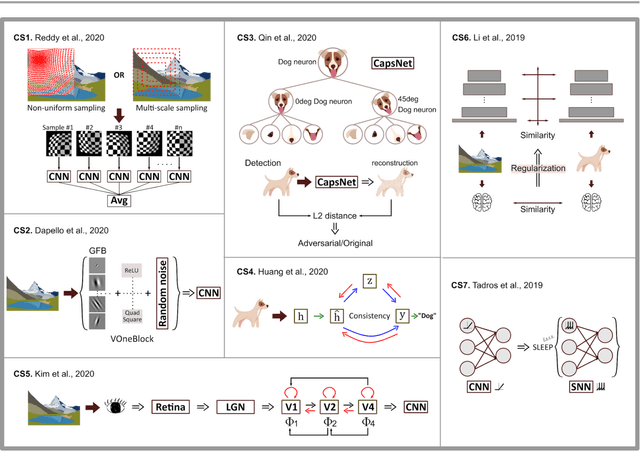
Deep convolutional neural networks (DCNNs) have revolutionized computer vision and are often advocated as good models of the human visual system. However, there are currently many shortcomings of DCNNs, which preclude them as a model of human vision. For example, in the case of adversarial attacks, where adding small amounts of noise to an image, including an object, can lead to strong misclassification of that object. But for humans, the noise is often invisible. If vulnerability to adversarial noise cannot be fixed, DCNNs cannot be taken as serious models of human vision. Many studies have tried to add features of the human visual system to DCNNs to make them robust against adversarial attacks. However, it is not fully clear whether human vision inspired components increase robustness because performance evaluations of these novel components in DCNNs are often inconclusive. We propose a set of criteria for proper evaluation and analyze different models according to these criteria. We finally sketch future efforts to make DCCNs one step closer to the model of human vision.
A Little Fog for a Large Turn
Jan 16, 2020
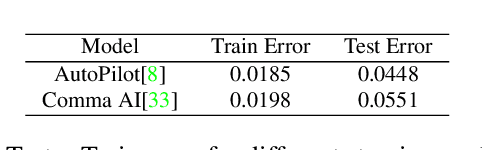
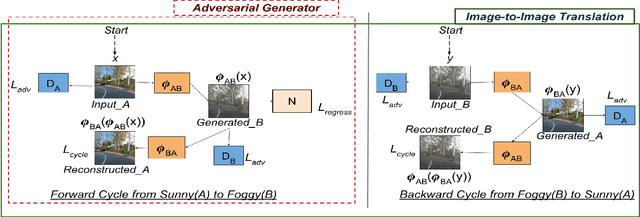

Small, carefully crafted perturbations called adversarial perturbations can easily fool neural networks. However, these perturbations are largely additive and not naturally found. We turn our attention to the field of Autonomous navigation wherein adverse weather conditions such as fog have a drastic effect on the predictions of these systems. These weather conditions are capable of acting like natural adversaries that can help in testing models. To this end, we introduce a general notion of adversarial perturbations, which can be created using generative models and provide a methodology inspired by Cycle-Consistent Generative Adversarial Networks to generate adversarial weather conditions for a given image. Our formulation and results show that these images provide a suitable testbed for steering models used in Autonomous navigation models. Our work also presents a more natural and general definition of Adversarial perturbations based on Perceptual Similarity.
Harnessing the Vulnerability of Latent Layers in Adversarially Trained Models
May 13, 2019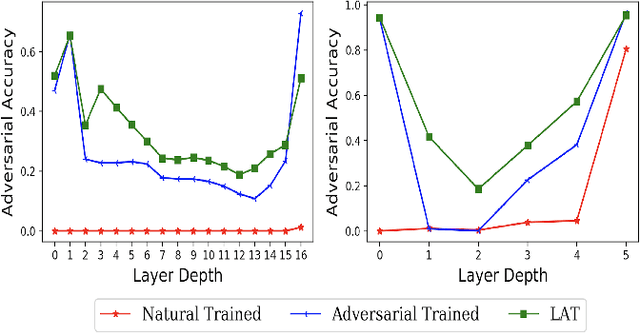
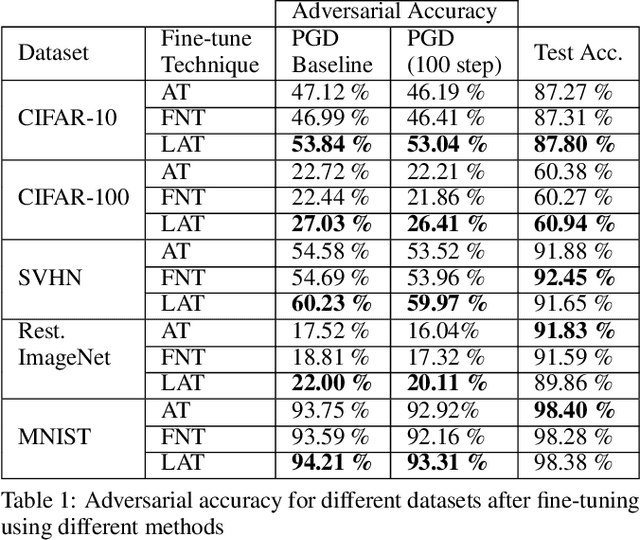
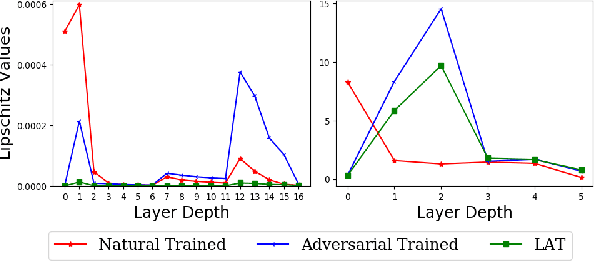

Neural networks are vulnerable to adversarial attacks -- small visually imperceptible crafted noise which when added to the input drastically changes the output. The most effective method of defending against these adversarial attacks is to use the methodology of adversarial training. We analyze the adversarially trained robust models to study their vulnerability against adversarial attacks at the level of the latent layers. Our analysis reveals that contrary to the input layer which is robust to adversarial attack, the latent layer of these robust models are highly susceptible to adversarial perturbations of small magnitude. Leveraging this information, we introduce a new technique Latent Adversarial Training (LAT) which comprises of fine-tuning the adversarially trained models to ensure the robustness at the feature layers. We also propose Latent Attack (LA), a novel algorithm for construction of adversarial examples. LAT results in minor improvement in test accuracy and leads to a state-of-the-art adversarial accuracy against the universal first-order adversarial PGD attack which is shown for the MNIST, CIFAR-10, CIFAR-100 datasets.